前言
决策树(Decision Tree)是一种基于树结构进行决策分析的算法,可以用于分类和回归问题。我们将从多个方面介绍机器学习决策树,包括决策树原理、算法分析、简单案例。
一、原理
决策树的基本原理是将数据集分成不同的类别或回归值,通过构建树形结构的模型进行预测。决策树模型由节点和边组成,每个节点表示一个属性或特征,每条边表示一个属性或特征的取值。决策树的根节点表示最重要的特征,其余节点表示次要的特征。决策树的每个叶子节点表示一个分类或回归值。
决策树的构建过程是从根节点开始,选择最优的属性或特征作为分裂条件,将数据集分成不同的子集。分裂条件可以通过信息增益、信息增益比、基尼系数等指标来计算。在分裂过程中,需要考虑过拟合和欠拟合问题,可以通过剪枝来解决。
决策树的预测过程是从根节点开始,按照分裂条件依次遍历各个节点,直到到达叶子节点。叶子节点对应的分类或回归值就是模型的预测结果。
二、衡量指标
决策树是一种用于分类和回归的有监督机器学习算法。在构建决策树时,我们需要选择合适的特征进行分裂,以使得分类结果更加准确。而选择特征的过程中,就需要使用一些评价指标来度量特征的重要性。常用的评价指标包括熵、信息增益、信息增益比、基尼系数等。
熵
熵是信息论中用来度量信息量的一个指标。在决策树中,我们可以使用熵来度量样本集合的不确定性。假设有一个样本集合 D D D,其中第 k k k 类样本所占的比例为 p k p_k pk,则该样本集合的熵可以表示为:
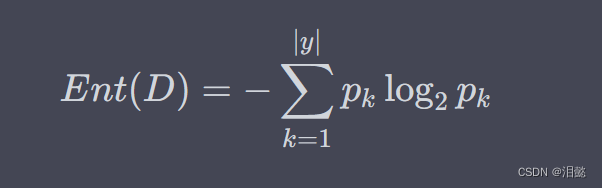
其中, ∣ y ∣ |y| ∣y∣ 表示样本集合 D D D 中可能的类别数目。
当样本集合 D D D 中只包含一种类别的样本时,熵达到最小值 0 0 0,表示样本集合完全确定;当样本集合 D D D 中包含所有类别的样本数量相等时,熵达到最大值 log 2 ∣ y ∣ \log_2 |y| log2∣y∣,表示样本集合完全不确定。
信息增益
信息增益是用来衡量特征对于分类的重要性的指标。假设有一个特征 A A A,它将样本集合 D D D 分成了 v v v 个子集 D 1 , D 2 , . . . , D v D_1, D_2, ..., D_v D1,D2,...,Dv,其中 D i D_i Di 表示 A A A 的取值为 a i a_i ai 的样本子集。则特征 A A A 对样本集合 D D D 的信息增益可以表示为:
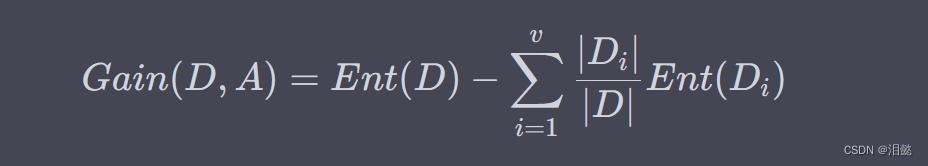
其中, ∣ D i ∣ |D_i| ∣Di∣ 表示样本子集 D i D_i Di 的样本数量, ∣ D ∣ |D| ∣D∣ 表示样本集合 D D D 的样本数量。信息增益的值越大,表示特征 A A A 对分类的贡献越大。
信息增益的计算方式和熵增益类似,区别在于熵增益的计算是针对样本集合的混乱程度,而信息增益是针对样本集合的分类能力。即信息增益越大,表示特征 A A A 对样本集合的分类能力越强。
然而,信息增益在某些情况下可能会出现偏向于选择取值较多的特征的问题。比如,假设有一个特征 A A A,它的取值有很多,但是每个取值的样本数量都很少,而另一个特征 B B B,它只有两个取值,但是每个取值的样本数量都很多。如果只考虑信息增益,那么很可能会选择特征 A A A 进行分裂,但是实际上特征 B B B 更加重要。
信息增益比
为了解决信息增益偏向于选择取值较多的特征的问题,我们可以使用信息增益比来评估特征的重要性。信息增益比将信息增益除以特征 A A A 的熵:
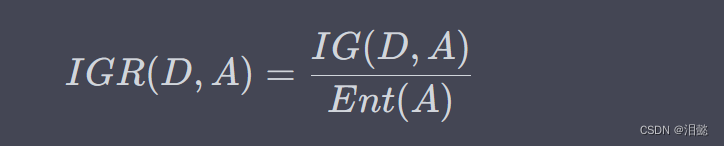
其中, E n t ( A ) = − ∑ i = 1 v ∣ D i ∣ ∣ D ∣ log 2 ∣ D i ∣ ∣ D ∣ Ent(A) = -\sum_{i=1}^{v}\frac{|D_i|}{|D|}\log_2\frac{|D_i|}{|D|} Ent(A)=−∑i=1v∣D∣∣Di∣log2∣D∣∣Di∣ 表示特征 A A A 的熵。
信息增益比的计算方式是先计算信息增益,然后将其除以特征 A A A 的熵。这样,可以消除特征取值数目多的影响,使得特征取值数目少的特征也有机会被选中。
基尼系数
基尼系数是另一种衡量特征重要性的指标,它衡量的是从样本集合中随机抽取两个样本,其类别不一致的概率,即:
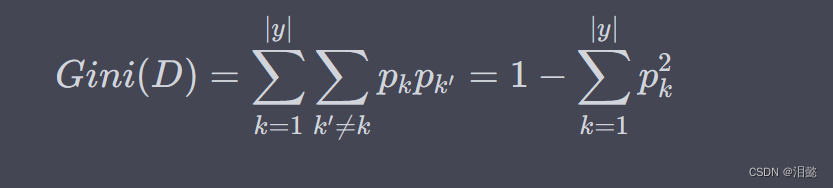
其中, p k p_k pk 表示样本集合中第 k k k 类样本所占的比例。
对于特征 A A A,假设它将样本集合 D D D 划分成了 v v v 个子集 D 1 , D 2 , . . . , D v D_1, D_2, ..., D_v D1,D2,...,Dv,其中 D i D_i Di 表示 A A A 的取值为 a i a_i ai 的样本子集。则特征 A A A 对样本集合 $的基尼指数可以表示为:
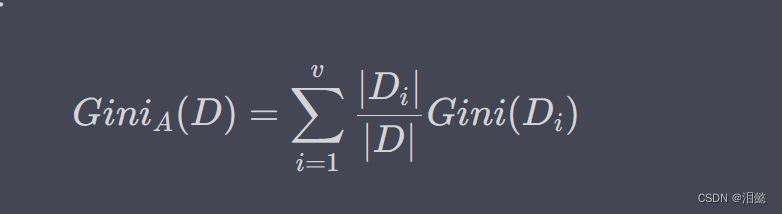
特征 A A A 的基尼指数表示样本集合 D D D 在特征 A A A 的条件下的不确定性,也就是对于特征 A A A,样本集合 D D D 的加权基尼指数。同样地,我们可以计算出特征 A A A 的基尼系数增益:
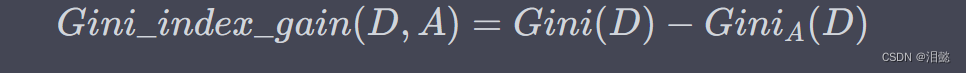
基尼系数与信息熵类似,都是用来衡量样本集合的混乱程度,但是它们之间有些微小的差别。在分类问题中,基尼系数通常比信息熵稍微快一些,但是它们之间的差别不大。因此,通常可以选择其中之一作为特征选择的指标。
认识
决策树是一种常用的分类与回归算法,可以通过构建树形结构来对样本进行分类或回归。决策树的构建过程包括特征选择、树的生成和剪枝三个部分。特征选择是决策树构建的重要步骤,常用的特征选择指标包括信息熵、信息增益、信息增益比和基尼系数。其中,信息熵和信息增益适用于离散特征,信息增益比和基尼系数适用于连续特征和离散特征。在实际应用中,可以根据数据集的特点和需求选择合适的特征选择指标,来构建高效、准确的决策树模型。
算法分析
决策树算法有多种,包括ID3、C4.5、CART等。这些算法在分裂条件、剪枝策略、特征选择等方面有所不同,下面简要介绍其中两个算法。
- ID3
ID3算法是一种基于信息增益的决策树算法,用于分类问题。信息增益是指分裂前后信息熵的差值,信息熵可以用来表示数据的不确定性。ID3算法选择信息增益最大的属性或特征进行分裂,直到所有数据都属于同一类别或无法继续分裂。
D3算法的优点是简单易懂、计算速度快,缺点是对于连续值的处理不好,容易产生过拟合。
- CART
CART算法是一种基于基尼系数的决策树算法,可以用于分类和回归问题。基尼系数是指分裂前后基尼指数的差值,基尼指数可以用来表示数据的纯度。CART算法选择基尼系数最小的属性或特征进行分裂,直到满足某个停止条件。
CART算法的优点是可以处理连续值和离散值,容易产生高精度的模型,缺点是容易产生过拟合,需要进行剪枝操作。
实战案例
鸢尾花分类问题为例构建分类问题
鸢尾花数据集是机器学习中常用的分类数据集,包含三种不同种类的鸢尾花,共计150个样本,每个样本包含四个特征(萼片长度、萼片宽度、花瓣长度、花瓣宽度)和一个标签(0、1、2表示三种不同种类的鸢尾花)
- 导入数据集
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
iris = load_iris()
X = iris.data
y = iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
- 模型训练
clf = DecisionTreeClassifier(random_state=42)
clf.fit(X_train, y_train)
- 模型指标
# 预测测试集
y_pred = clf.predict(X_test)
# 计算模型指标
acc = accuracy_score(y_test, y_pred)
pre = precision_score(y_test, y_pred, average='macro')
rec = recall_score(y_test, y_pred, average='macro')
f1 = f1_score(y_test, y_pred, average='macro')
print(f"Accuracy: {
acc:.2f}\n Precision: {
pre:.2f} \nRecall: {
rec:.2f}\n F1-score: {
f1:.2f}")
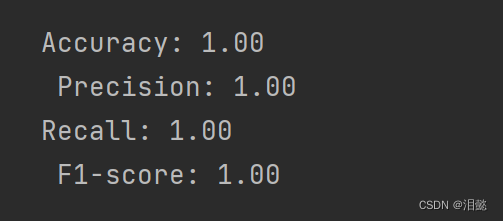
可以看到各个指标都是1,说明模型分类成功率为一百
我们看一下混淆矩阵
from sklearn.metrics import confusion_matrix
confusion_matrixs=confusion_matrix(y_test,y_pred)
confusion_matrixs
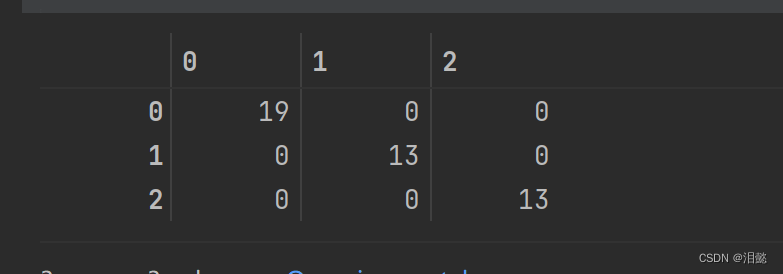
可以看到成功被分类了
总结
决策树可以用于多种应用场景,包括分类、回归、特征选择等。
在分类问题中,决策树可以用于识别垃圾邮件、疾病诊断、客户分类等。在回归问题中,决策树可以用于预测房价、股票走势等。在特征选择中,决策树可以用于选择最重要的特征,提高模型的准确率。
下一节将会详细多方面的进行决策树案例实践与介绍
希望多多支持,后续继续分享有趣的东西