一文教你看懂Golang协程调度【GMP设计思想】
1 Golang调度器的由来
1.1 单进程的问题:进程阻塞、CPU浪费时间
- 单一执行程序、计算机只能一个任务一个任务来进行处理
- 进程阻塞所带来的CPU浪费时间
1.2 多进程、多线程问题:设计复杂、高内存、CPU占用
- 设计变得复杂:
- 进程/线程的数量越多,切换成本就越大,也就越浪费
- 多线程往往伴随着同步竞争(如:锁、资源冲突等)
- 多进程、多线程的壁垒
- 高内存占用:
- 进程占用内存(虚拟内存:4GB 32bitOS)
- 线程占用内存(约4MB)- 高CPU调度消耗
1.3 协程co-routine的模式(M:N,依赖调度器的性能)

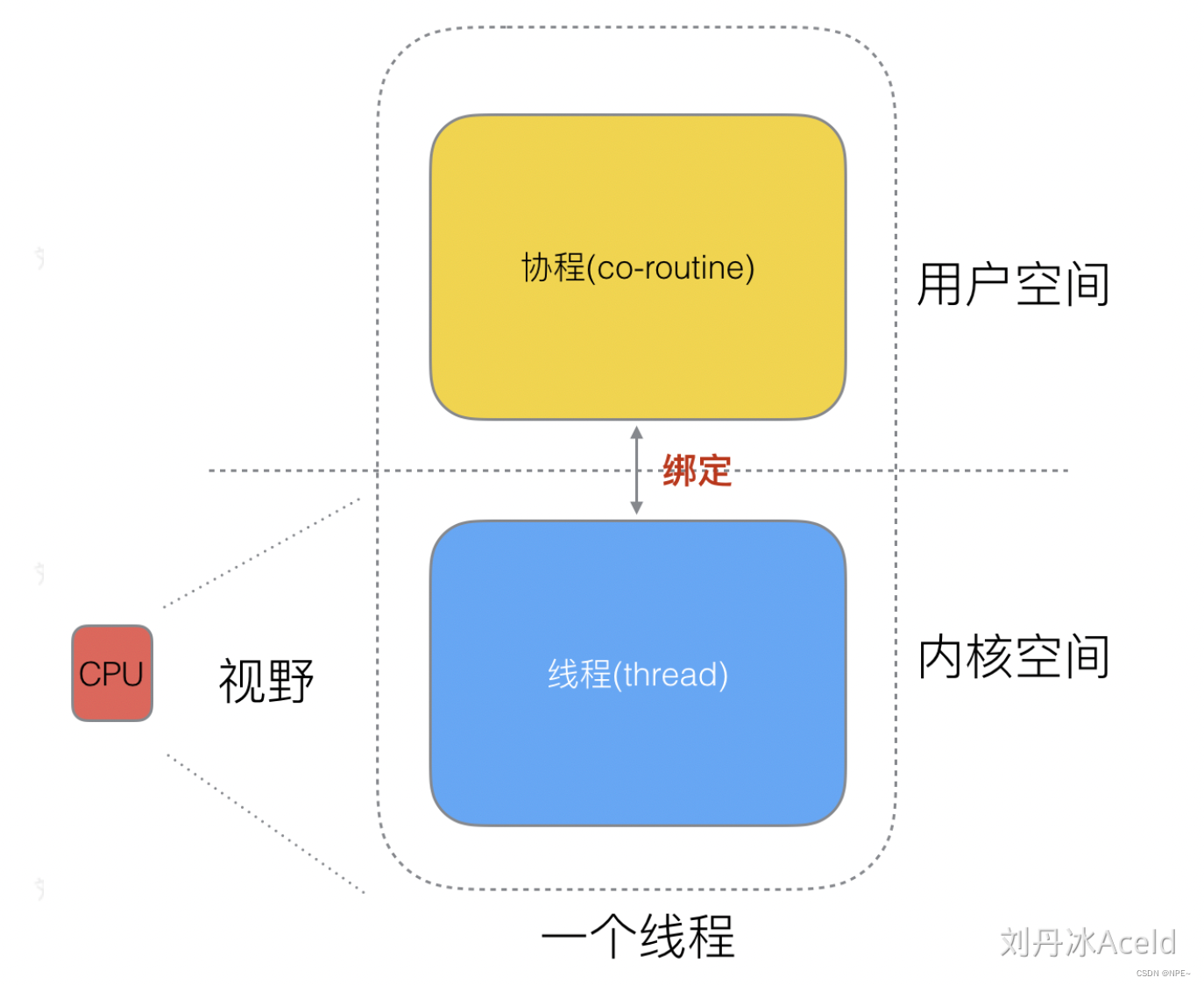
CPU本质是操控一个线程,只不过我们逻辑意义上将线程划分为了协程和内核空间的线程。然后我们通过编程语言来操控用户空间上的线程(协程)
①N:1方式:
- 无法利用多个CPU
- 出现阻塞的瓶颈
②1:1方式:- 跟多线程/多进程模型无异
- 切换协程成本代价昂贵
③M:N方式:- 能够利用多核
- 过于以来协程调度器的优化和算法
1.4 调度的优化
Goroutine的优化:
- 内存占用,几KB,可以大量开辟
- 灵活调度,切换成本低
早期Go调度器的弊端:
基于全局的Go队列和比较传统的轮询,利用多个thread去调度
弊端:
- 创建、销毁、调度G(goroutine)都需要每个M获取锁,形成了激烈的资源竞争
- M(thread)转移G会曹成延迟和额外的系统负载
- 系统调用(CPU在M之间的切换)导致频繁的线程阻塞和取消阻塞
2 GMP模型的设计思想
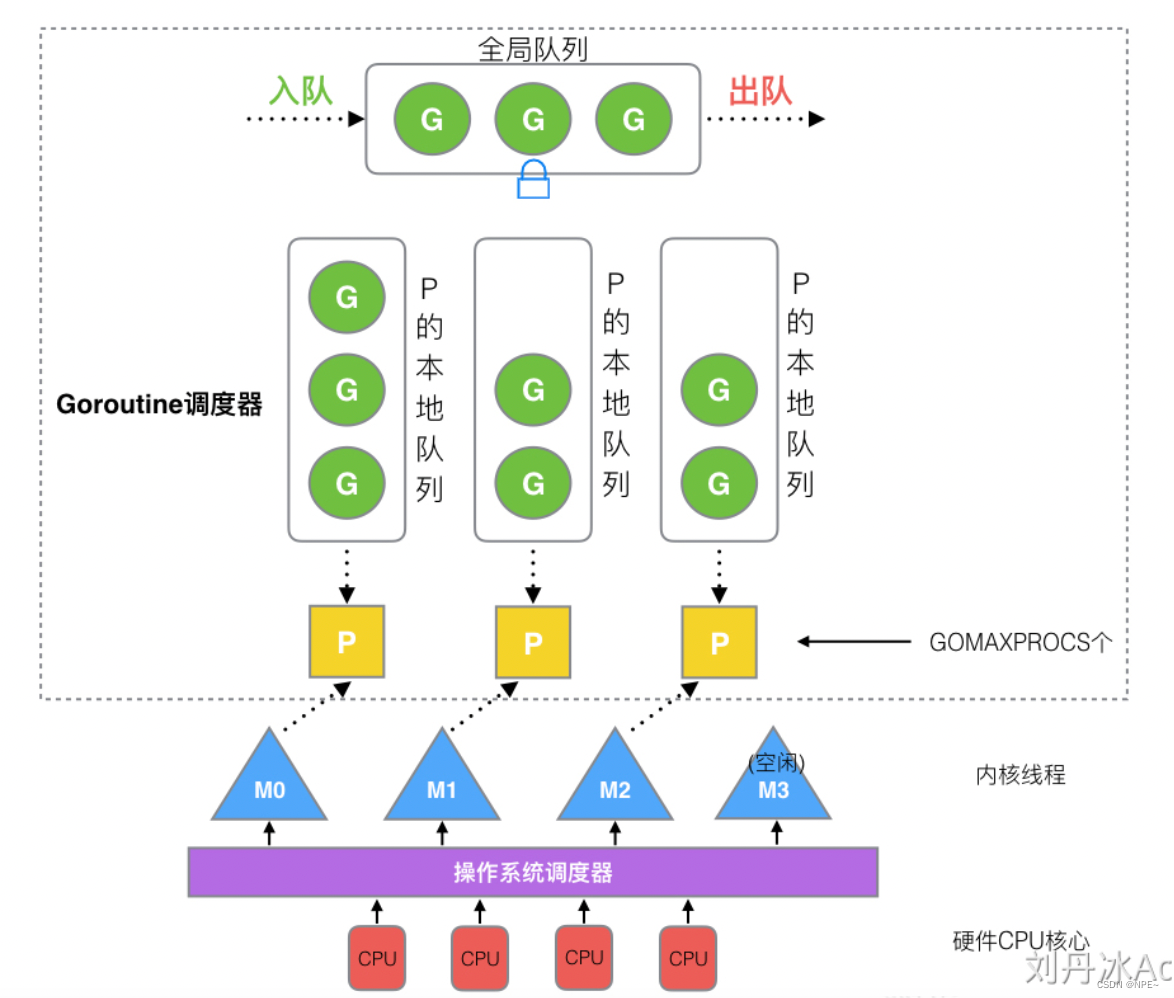
在Go中,线程是运行goroutine的实体,调度器的功能是把可运行的goroutine分配到工作线程上。
2.1 GMP模型简介
①GMP:goroutine-processor-thread
G:goroutine 协程
P:processor 处理器
M:thread 内核线程
②全局队列:存放等待运行的G
存放等待运行的goroutine
③P的本地队列:存放等待运行的G
processer的本地队列:
- 存放等待运行的goroutine
- 数量限制:不超过256G
- 优先将新创建的goroutine放在P的本地队列中,如果本地队列放满了才会放在全局队列中
④P列表:程序启动时创建
- 程序启动时创建
- 最多有GOMAXPROCS个(可配置)
⑤M列表:当前OS分配到Go程序的内核线程数
当前操作系统分配到当前Go程序的内核线程数
⑥P和M的数量
- P的数量:
- 环境变量$GOMAXPROCS配置
- 在程序中通过runtime.GOMAXPROCS()来设置
- M的数量:
- Go语言本身限定M最多1W
- runtime/debug包中的SetMaxThreads函数来设置
- 如果有一个M阻塞,会创建一个新的M
- 如果有M空闲,那么就会回收或者睡眠一个M
2.2 调度器的设计策略
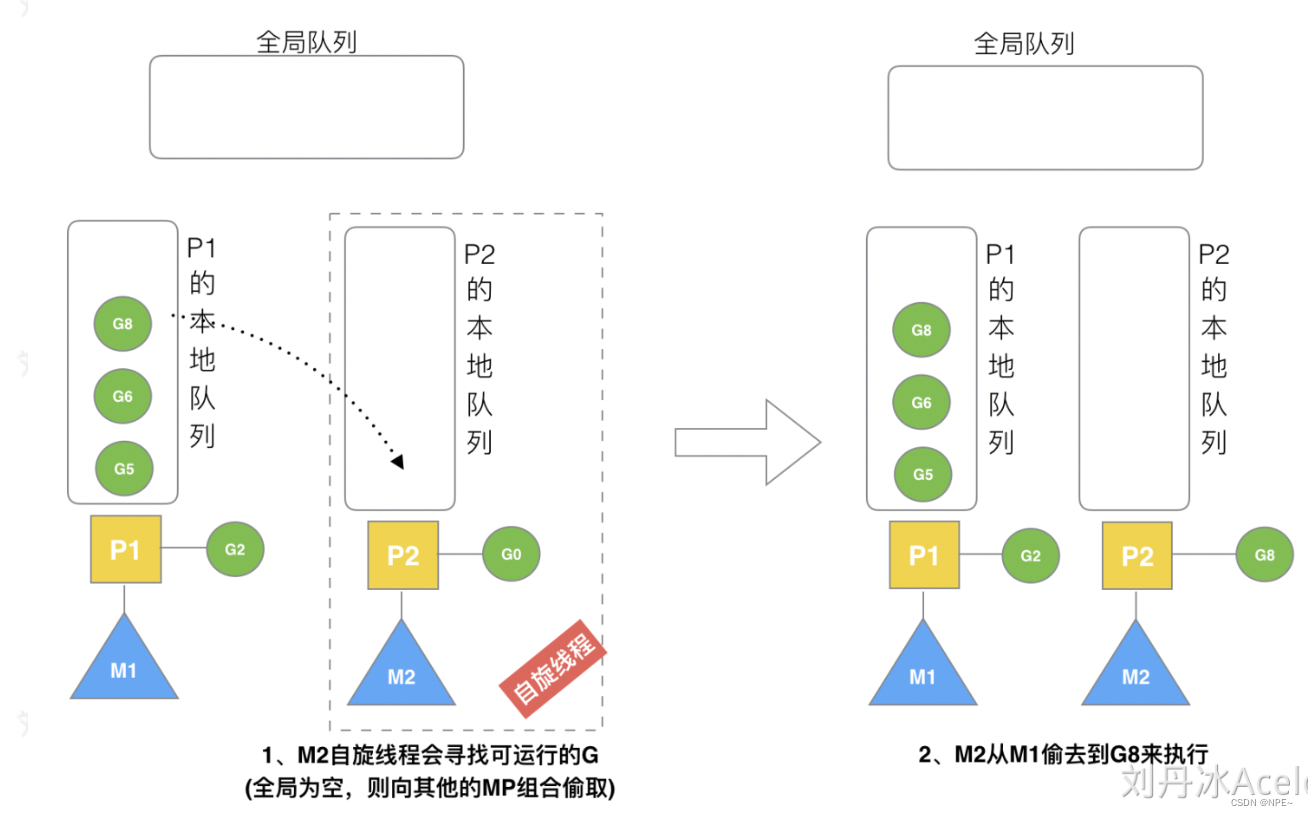
①复用线程:work stealing、hand off机制
避免频繁的创建、销毁线程,而是线程进行复用
- work stealing机制:当本线程无可运行的G时,会尝试从全局G中偷取G,如果全局队列为空,那么从其他线程绑定的P偷取G,而不是销毁空闲的线程【本地队列-全局队列-其他队列】
- hand off机制:当本线程因为G进行系统调用阻塞时,线程释放绑定的P,把P转移给其他空闲的线程执行。
②利用并行
GOMAXPROCS设置P的数量,最多有GOMAXPROCS个线程分布在多个CPU上同时运行
③抢占
在co-routine中要等待一个协程主动让出CPU才执行下一个协程,
在Go中,一个goroutine最多占用CPU 10ms,防止其他goroutine被饿死
④全局G队列
当M执行work stealing它可以从全局G的队列获取G
- 本地队列没有可运行的goroutine,会有steal机制,从从其他P里获取可运行的G ,本地队列运行顺序为 先从本地队列查询,全局队列查询,然后再从其他P里偷取,具体源码在runtime的proc.go
2.3 go func()经历了哪些过程
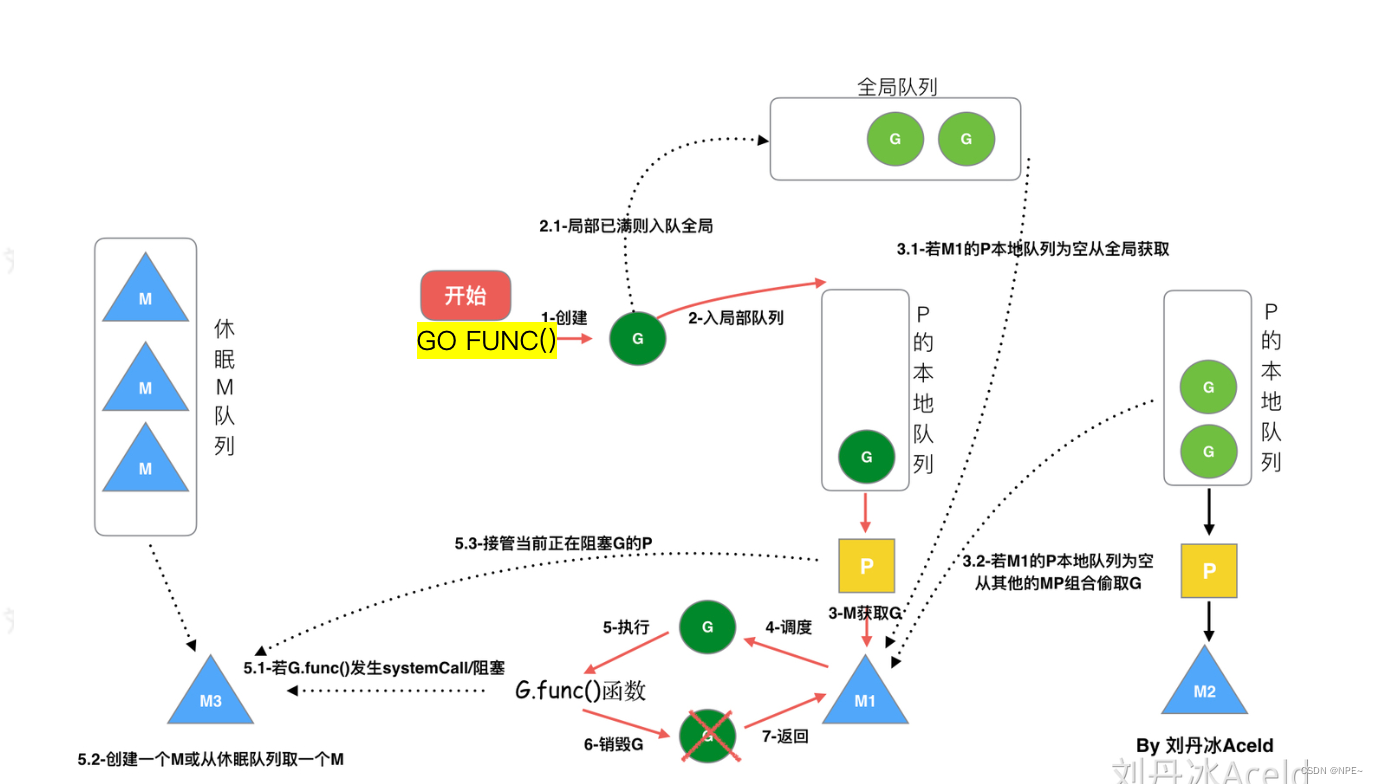
- 我们通过go func()来创建一个goroutine
- 有两个存储G的队列,一个是局部调度器P的本地队列、一个是全局G队列。新创建的G会先保存在P的本地队列中,如果P的本地队列已经满了就会保存在全局的队列中。
- G只能运行在M中,一个M必须持有一个P,M与P是1:1的关系。M会从P的本地队列弹出一个可执行状态的G来执行,如果P的本地队列为空,就会向其他的MP组合或者全局队列中偷取一个可执行的G来执行。【
本地-全局-其他队列】- 一个M调度G执行的过程是一个循环机制
- 当M执行某一个G时候如果发生了syscall或者其他阻塞操作,M会阻塞,如果当前有一些G在执行,runtime会把这个线程M从P中摘除(detach),然后再创建一个新的操作系统的线程(如果有空闲的线程可复用空闲线程)来服务于这个P。
- 当M系统调用结束的时候,这个G会尝试获取一个空闲的P执行,并放入到这个P的本地队列。如果获取不到P,那么这个线程M会变成休眠状态,加入到空闲线程中,然后这个G会被放入全局队列中。
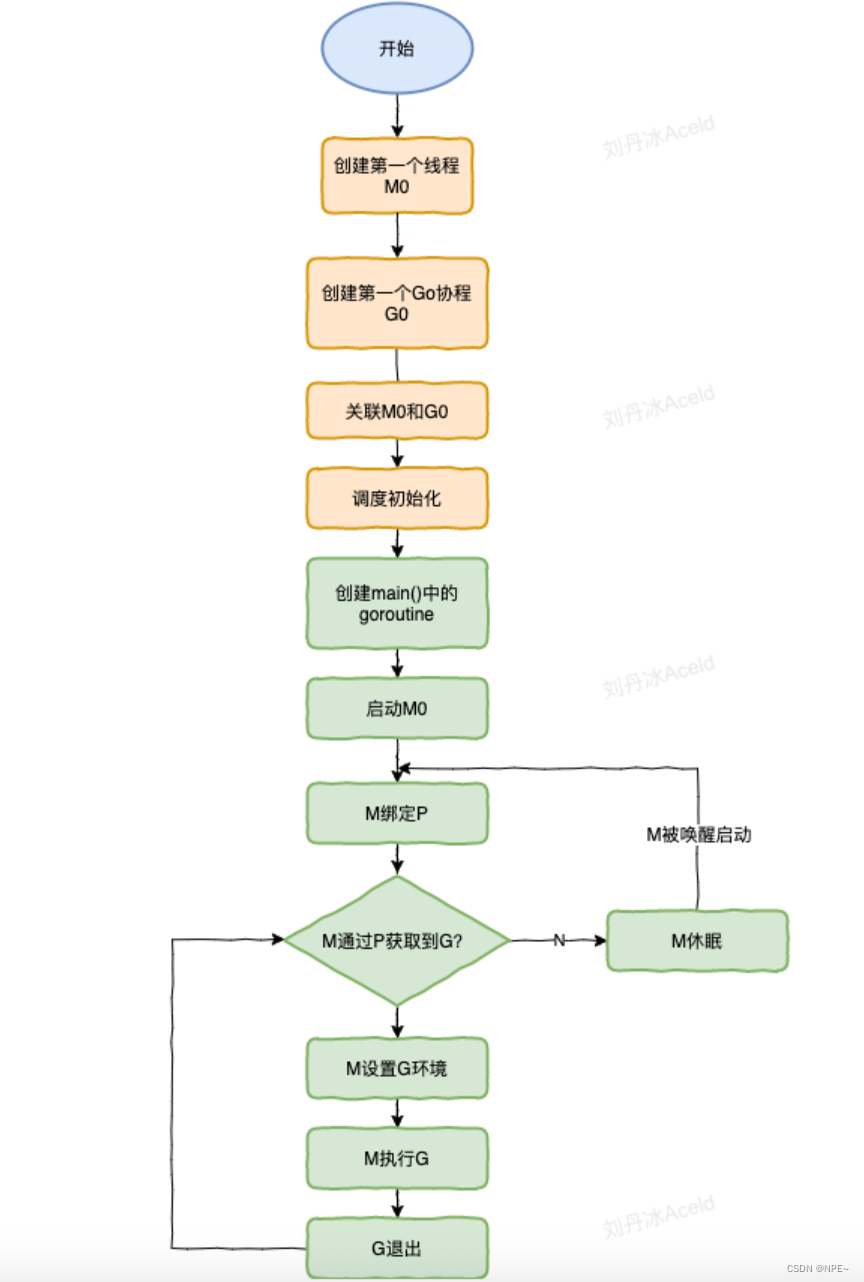
2.4 调度器调度的生命周期:M0、G0
package main
import "fmt"
func main() {
fmt.Println("Hello world")
}
下面我们分析代码流程:
- runtime创建最初的线程M0和G0,并把二者关联
- 调度器初始化:初始化M0、栈、垃圾回收,以及创建和初始化由GOMAXPROCS个P构成的P列表
- 示例代码中的main函数是main.main,runtime中也有一个main函数-runtime.main,代码经过编译后,
runtime.main会调用main.main,程序启动时会为runtime.main创建Goroutine,称它为main goroutine,然后吧main goroutine加入到P的本地队列。- 启动M0,M0已经绑定了P,会从P的本地队列获取G,获取到main goroutine
- G拥有栈,M根据G中的栈信息和调度信息设置运行环境
- M运行G
- G退出,再次回到M获取可运行的G,这样重复下去,直到main.main退出,runtime.main执行defer 和panic处理,或者调用runtime.exit退出程序。
调度器的生命周期几乎占满了一个Go程序的一生,runtime.main的goroutine执行之前都是为调度器做准备工作,runtime.main的goroutine运行,才是调度器的真正开始,直到runtime.main的结束而结束。
①M0:启动go程序后创建的第一个主线程
M0是启动程序后的编号为0的主线程,这个M对应的实例会在全局变量runtime.m0中,不需要在heap上分配,M0负责执行初始化操作和启动第一个G,再之后的M0就和其他M一样了
②G0:每个M启动后创建的第一个goroutine
G0是每次启动一个M都会第一个创建的goroutine,G0仅用于负责调度G,G0不指向任何可执行的函数,每个M都会有一个自己的G0.在调度或系统调用时会使用G0的栈空间,全局变量的G0是M0的G0
2.5 GMP可视化调试(trace编程)
① 基本的trace编程
- 创建trace文件 f,err := os.Create(“trace.out”)
- 启动trace trace.Start(f)
- 停止trace trace.Stop()
- go build运行之后,会得到一个trace.out文件
trace/main.go:
package main
import (
"fmt"
"os"
"runtime/trace"
)
func main() {
//1. 创建trace文件
file, err := os.Create("trace.out")
if err != nil {
panic(err)
}
defer file.Close()
//2. 开启trace
trace.Start(file)
//执行业务逻辑
fmt.Println("do something...")
//3. 暂停trace
trace.Stop()
}
运行上面的程序之后会得到一个trace.out文件:

②通过go tool trace工具打开trace文件
- go tool trace trace.out
- 通过http://127.0.0.1:xxxx进行访问(端口是随机的)

点击页面上的view trace:
查看效果:
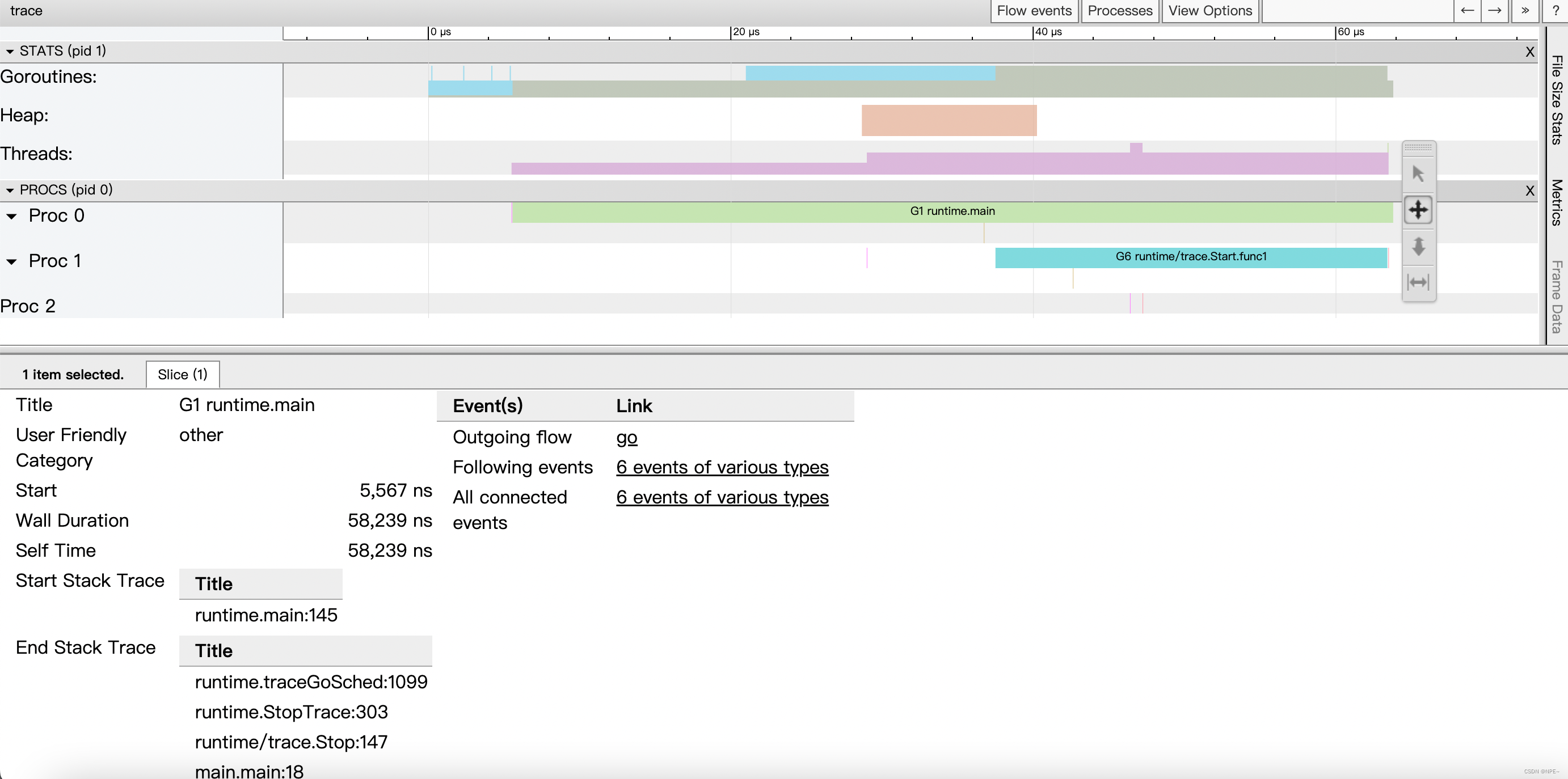
点击图表中不同的未知,查看左下方的值

1. G信息
点击Goroutines那一行可视化的数据条,我们会看到一些详细的信息。
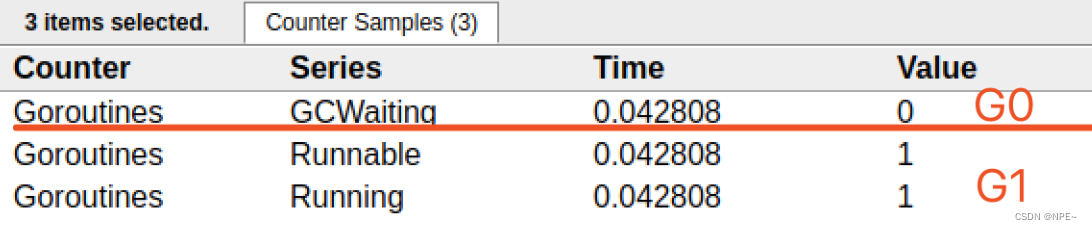
一共有两个G在程序中,一个是特殊的G0,是每个M必须有的一个初始化的G,这个我们不必讨论。
其中G1应该就是main goroutine(执行main函数的协程),在一段时间内处于可运行和运行的状态。
2. M信息
点击Threads那一行可视化的数据条,我们会看到一些详细的信息。

一共有两个M在程序中,一个是特殊的M0,用于初始化使用,这个我们不必讨论。
3. P信息

G1中调用了main.main,创建了trace goroutine g18。G1运行在P1上,G18运行在P0上。
这里有两个P,我们知道,一个P必须绑定一个M才能调度G。
4. M信息
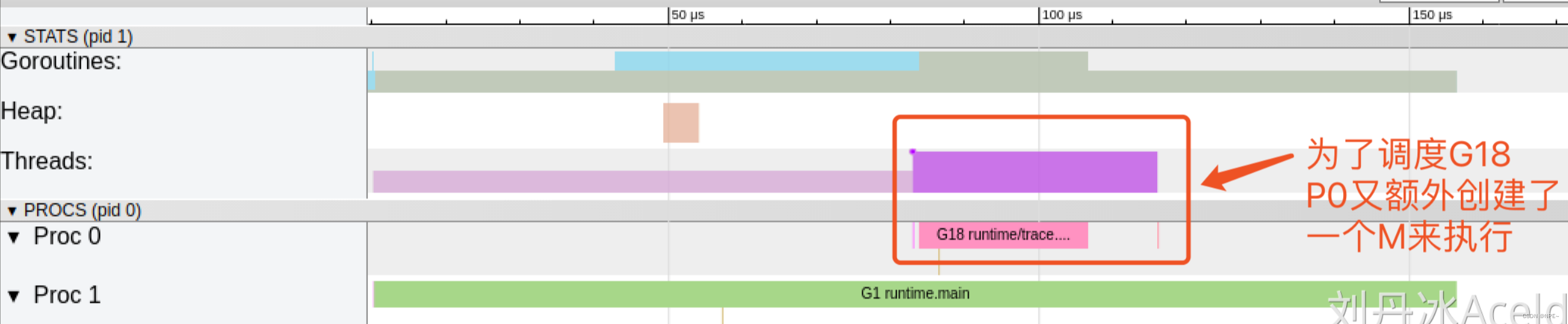
我们会发现,确实G18在P0上被运行的时候,确实在Threads行多了一个M的数据,点击查看如下:
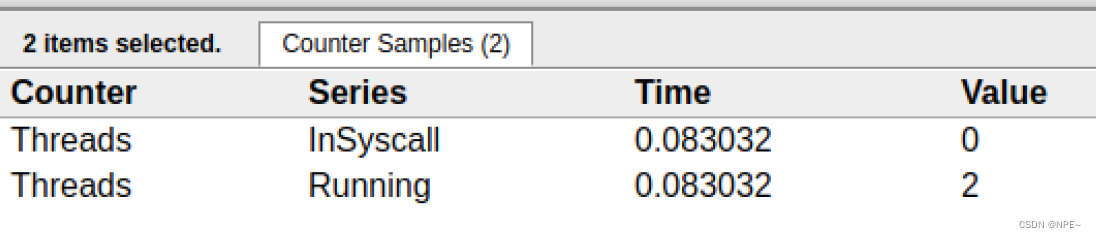
多了一个M2应该就是P0为了执行G18而动态创建的M2.
③通过Debug trace方式
main.go
package main
import (
"fmt"
"time"
)
func main() {
for i := 0; i < 5; i++ {
time.Sleep(time.Second)
fmt.Println("Hello World")
}
}
# 编写
go build main.go
# 执行编译好的可执行文件
GODEBUG=schedtrace=1000 ./main
# 查看输出结果
SCHED 0ms: gomaxprocs=2 idleprocs=0 threads=4 spinningthreads=1 idlethreads=1 runqueue=0 [0 0]
Hello World
SCHED 1003ms: gomaxprocs=2 idleprocs=2 threads=4 spinningthreads=0 idlethreads=2 runqueue=0 [0 0]
Hello World
SCHED 2014ms: gomaxprocs=2 idleprocs=2 threads=4 spinningthreads=0 idlethreads=2 runqueue=0 [0 0]
Hello World
SCHED 3015ms: gomaxprocs=2 idleprocs=2 threads=4 spinningthreads=0 idlethreads=2 runqueue=0 [0 0]
Hello World
SCHED 4023ms: gomaxprocs=2 idleprocs=2 threads=4 spinningthreads=0 idlethreads=2 runqueue=0 [0 0]
Hello World
● SCHED:调试信息输出标志字符串,代表本行是goroutine调度器的输出;
● 0ms:即从程序启动到输出这行日志的时间;
● gomaxprocs: P的数量,本例有2个P, 因为默认的P的属性是和cpu核心数量默认一致,当然也可以通过GOMAXPROCS来设置;
● idleprocs: 处于idle状态的P的数量;通过gomaxprocs和idleprocs的差值,我们就可知道执行go代码的P的数量;
● threads: os threads/M的数量,包含scheduler使用的m数量,加上runtime自用的类似sysmon这样的thread的数量;
● spinningthreads: 处于自旋状态的os thread数量;
● idlethread: 处于idle状态的os thread的数量;
● runqueue=0: Scheduler全局队列中G的数量;
● [0 0]: 分别为2个P的local queue中的G的数量。
3 GMP场景分析合集
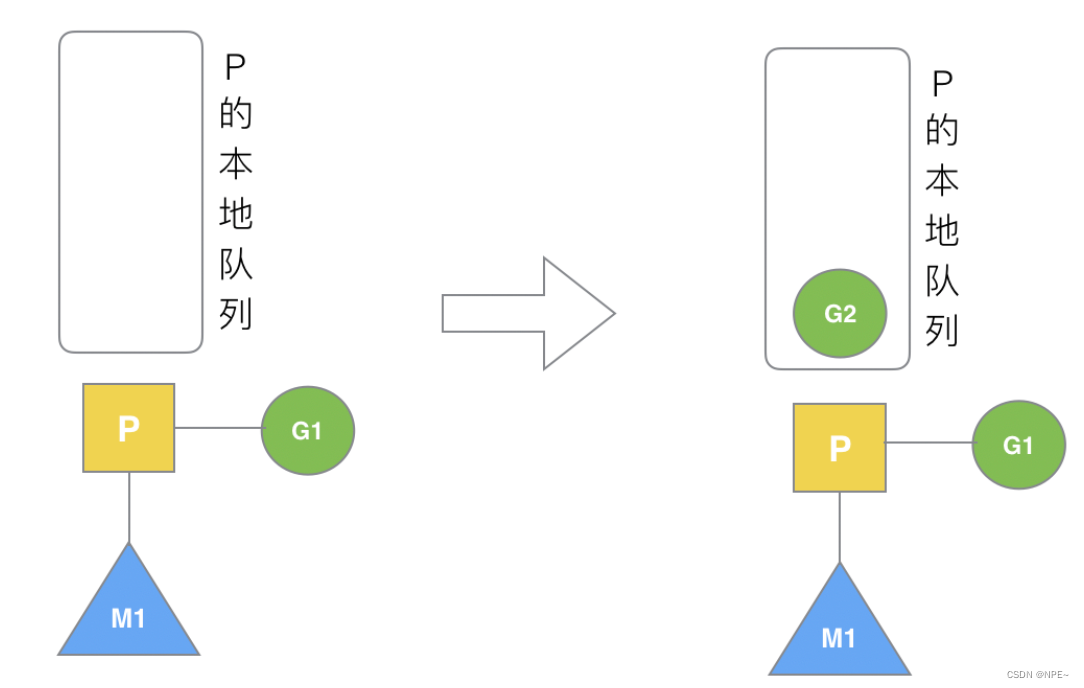
3.1 G1创建G2:优先入本地队列
正在执行的G创建的其他G优先加入本地队列。
P拥有G1,M1获取P后开始运行G1,G1使用go func()创建了G2,为了局部性G2优先加入到P1的本地队列。
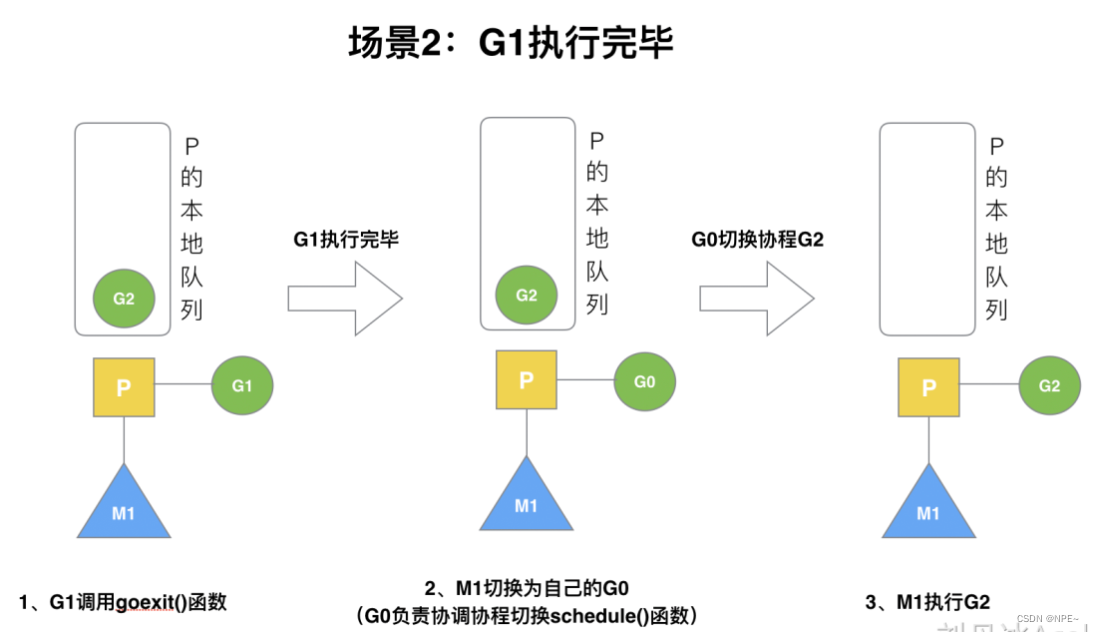
3.2 G1执行完毕调用G2:G0负责调度
G1执行完毕之后,由G0调度从队列中获取G2,然后让P来执行G2.
G1运行完成后(函数:goexit),M上运行的goroutine切换为G0,G0负责调度时协程的切换(函数:schedule)。从P的本地队列取G2,从G0切换到G2,并开始运行G2(函数:execute)。实现了线程M1的复用。
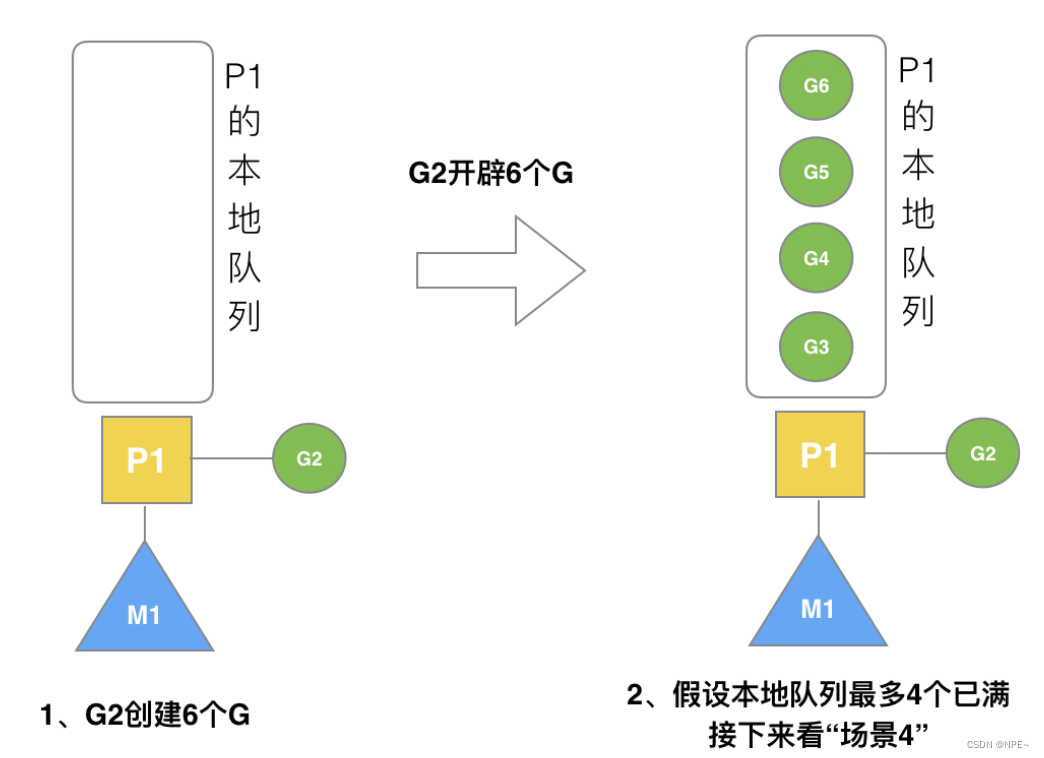
3.3 G2开辟过多G
假设每个P的本地队列只能存3个G。G2要创建了6个G,前3个G(G3, G4, G5)已经加入p1的本地队列,p1本地队列满了
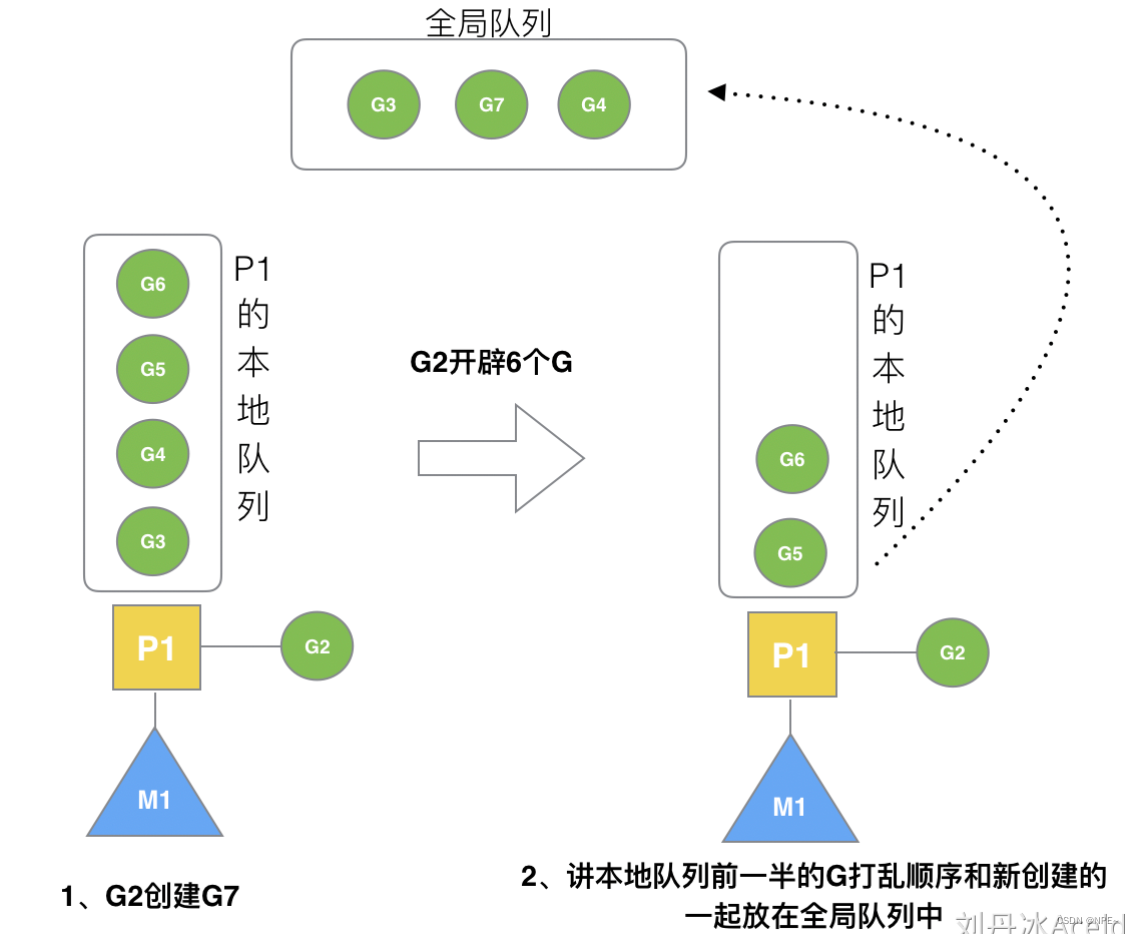
3.4 G2本地已经满继续创建G:打乱放全局队列
G2所绑定的队列已经满了,但此时又创建了新的G,则打乱本地队列的前半部分G和新创建的G一起放入全局队列。(保证:随机,避免新G饥饿。)
G2在创建G7的时候,发现P1的本地队列已满,需要执行负载均衡(把P1中本地队列中前一半的G,还有新创建G转移到全局队列)
- (实现中并不一定是新的G,如果G是G2之后就执行的,会被保存在本地队列,利用某个老的G替换新G加入全局队列)
- 这些G被转移到全局队列时,会被打乱顺序。所以G3,G4,G7被转移到全局队列。
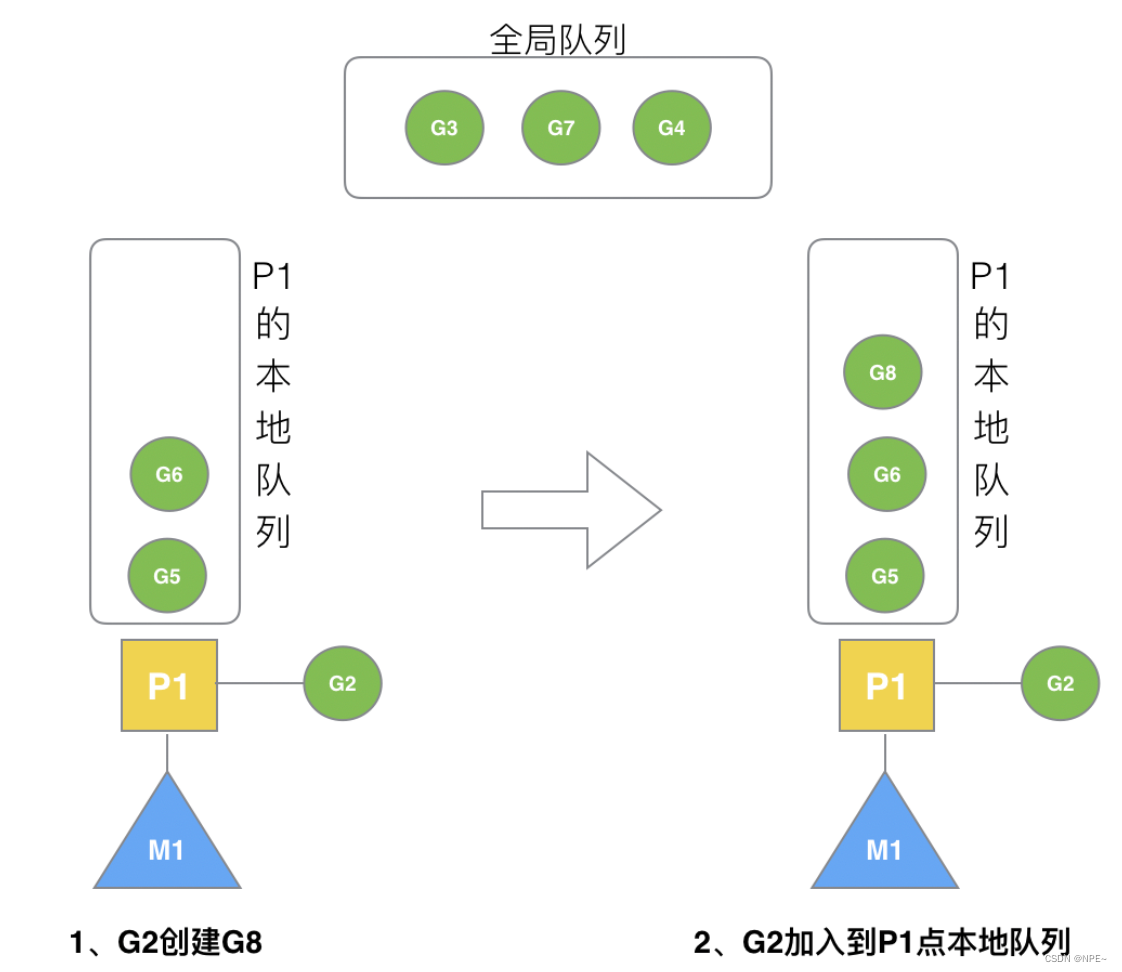
3.5 G2本地未满创G8:放入本地队列
如果在创建新G之后本地队列未满,则先放本地队列。
G2创建G8时,P1的本地队列未满,所以G8会被加入到P1的本地队列。
- G8加入到P1点本地队列的原因还是因为P1此时在与M1绑定,而G2此时是M1在执行。所以G2创建的新的G会优先放置到自己的M绑定的P上。
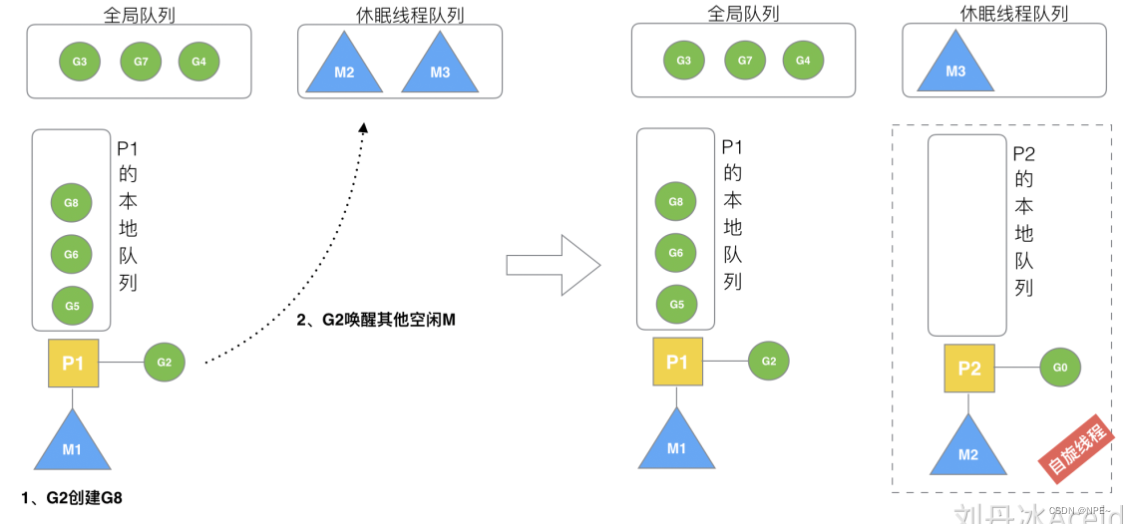
3.6 创建G时会尝试环境其他空闲的M和P去消费新G
创建新G成功后,会尝试换唤醒M和P,让其组合来消费新G。
规定:在创建G时,运行的G会尝试唤醒其他空闲的P和M组合去执行。
- 假定G2唤醒了M2,M2绑定了P2,并运行G0,但P2本地队列没有G,M2此时为自旋线程(没有G但为运行状态的线程,不断寻找G)。
3.7 从全局队列到P本地队列的LB(负载均衡)
自旋线程根据LB来从全局队列拉取G进行消费。
M2尝试从全局队列(简称“GQ”)取一批G放到P2的本地队列(函数:findrunnable())。M2从全局队列取的G数量符合下面的公式
n = min(len(GQ) / GOMAXPROCS + 1, cap(LQ) / 2 )
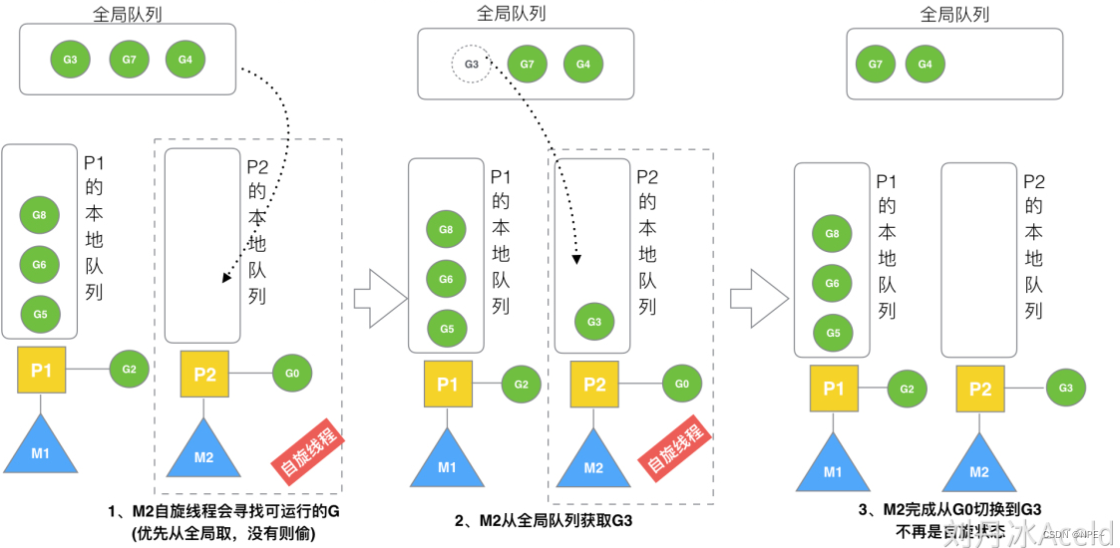
至少从全局队列取1个g,但每次不要从全局队列移动太多的g到p本地队列,给其他p留点。这是从全局队列到P本地队列的负载均衡。
3.8 M2从M1偷取G
如果M2队列为空,则从M1的本地队列中偷取后半部分G进行消费。(好不容易偷一次)
假设G2一直在M1上运行,经过2轮后,M2已经把G7、G4从全局队列获取到了P2的本地队列并完成运行,全局队列和P2的本地队列都空了,如场景8图的左半部分。
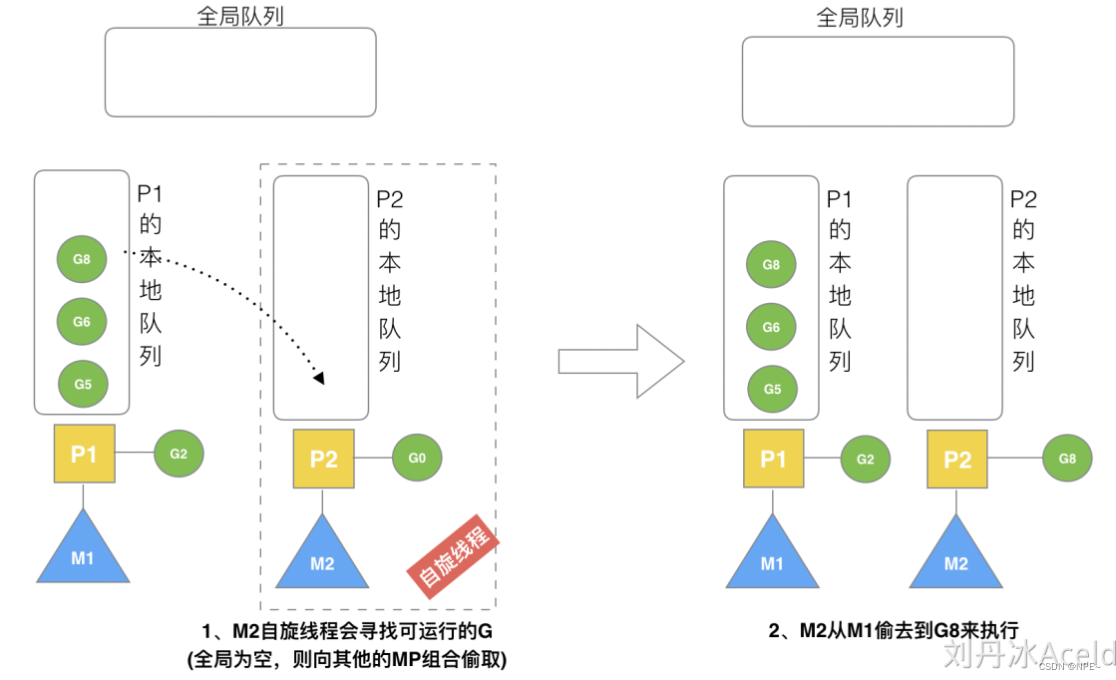
全局队列已经没有G,那m就要执行work stealing(偷取):从其他有G的P哪里偷取一半G过来,放到自己的P本地队列。P2从P1的本地队列尾部取一半的G,本例中一半则只有1个G8,放到P2的本地队列并执行。
3.9 自旋线程的最大限制:自旋+运行<=GOMAXPROCS
正在运行的线程+自旋的线程 <= GOMAXPROCS。
G1本地队列G5、G6已经被其他M偷走并运行完成,当前M1和M2分别在运行G2和G8,M3和M4没有goroutine可以运行,M3和M4处于自旋状态,它们不断寻找goroutine。
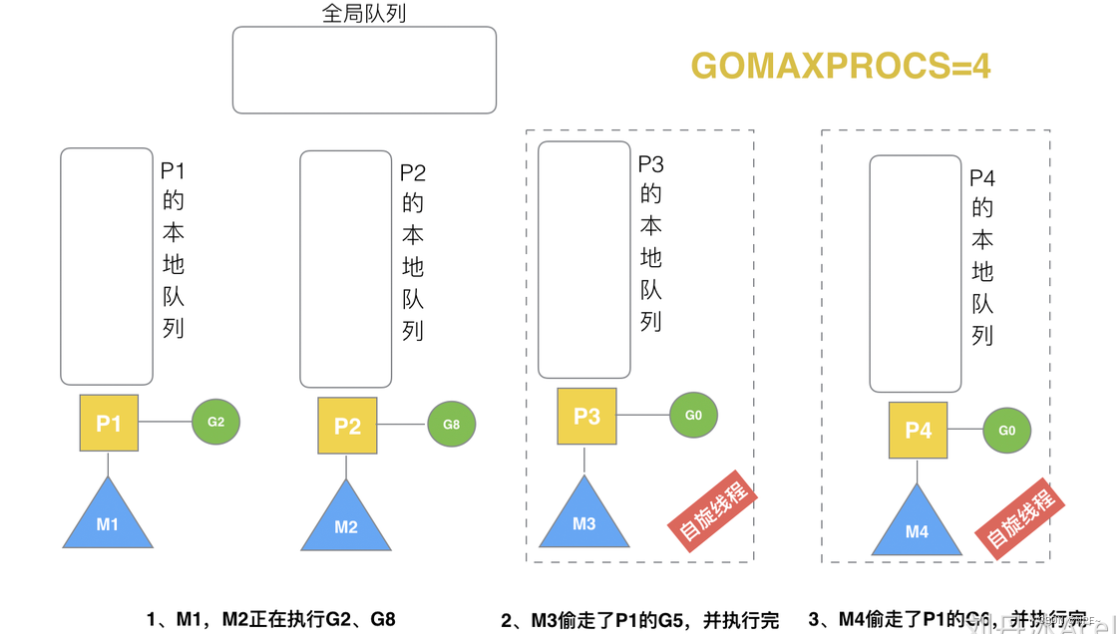
为什么要让m3和m4自旋,自旋本质是在运行,线程在运行却没有执行G,就变成了浪费CPU. 为什么不销毁现场,来节约CPU资源。因为创建和销毁CPU也会浪费时间,我们希望当有新goroutine创建时,立刻能有M运行它,如果销毁再新建就增加了时延,降低了效率。当然也考虑了过多的自旋线程是浪费CPU,所以系统中最多有GOMAXPROCS个自旋的线程(当前例子中的GOMAXPROCS=4,所以一共4个P),多余的没事做线程会让他们休眠。
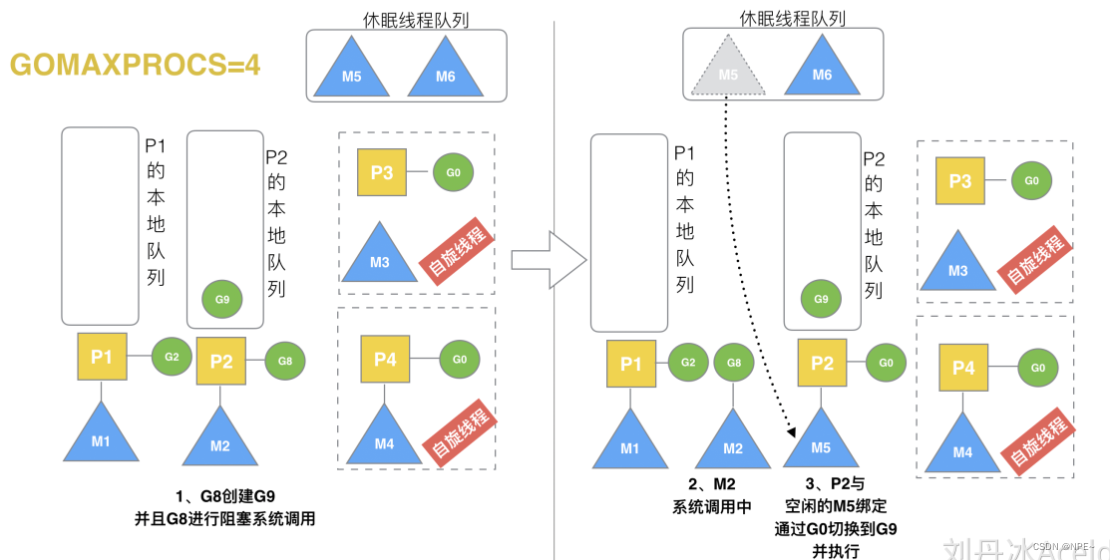
3.10 G发生系统调用或阻塞
P与阻塞的M解绑,去唤醒休眠中的M进行组合。
假定当前除了M3和M4为自旋线程,还有M5和M6为空闲的线程(没有得到P的绑定,注意我们这里最多就只能够存在4个P,所以P的数量应该永远是M>=P, 大部分都是M在抢占需要运行的P),G8创建了G9,G8进行了阻塞的系统调用,M2和P2立即解绑,P2会执行以下判断:如果P2本地队列有G、全局队列有G或有空闲的M,P2都会立马唤醒1个M和它绑定,否则P2则会加入到空闲P列表,等待M来获取可用的p。本场景中,P2本地队列有G9,可以和其他空闲的线程M5绑定
3.11 G发生系统调用或非阻塞
尝试获取之前解绑的P,如果之前的P已经与其他M组合,则尝试从空闲的P队列中获取新P。如果获取失败,则将阻塞结束的G放入全局队列
G8创建了G9,假如G8进行了非阻塞系统调用。
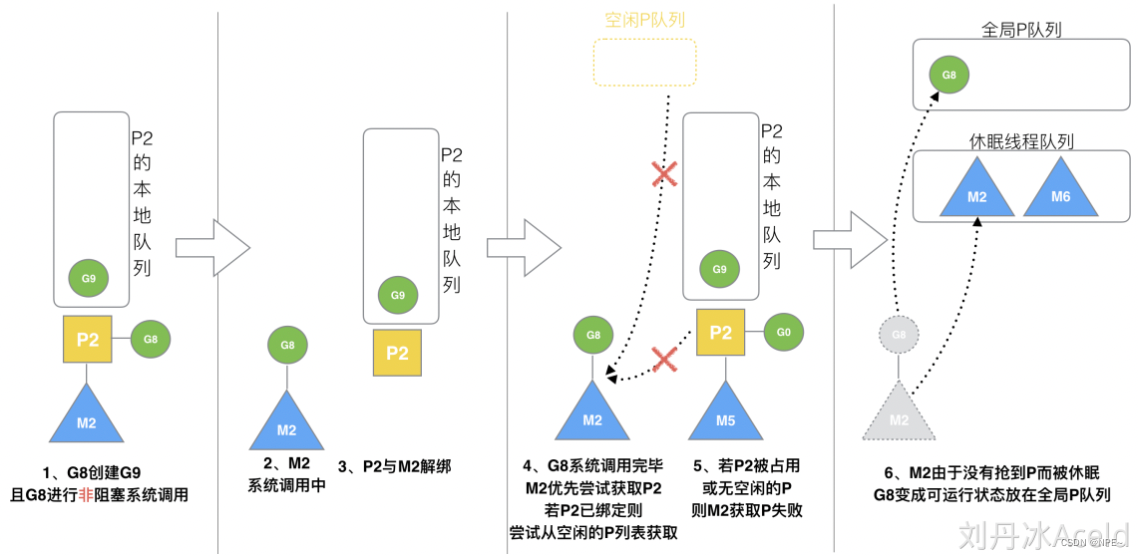
M2和P2会解绑,但M2会记住P2,然后G8和M2进入系统调用状态。当G8和M2退出系统调用时,会尝试获取P2,如果无法获取,则获取空闲的P,如果依然没有,G8会被记为可运行状态,并加入到全局队列,M2因为没有P的绑定而变成休眠状态(长时间休眠等待GC回收销毁)。
总结:Go调度器很轻量也很简单,足以撑起goroutine的调度工作,并且让Go具有了原生(强大)并发的能力。Go调度本质是把大量的goroutine分配到少量线程上去执行,并利用多核并行,实现更强大的并发。
参考:https://www.yuque.com/aceld/golang/srxd6d