
本文字数:15160;估计阅读时间:38 分钟
审校:庄晓东(魏庄)

介绍
在本文中,我们将借此机会提示用户:字典在加速查询方面的强大作用 - 尤其是包含JOIN的查询,以及一些使用技巧。此外,本文中的所有示例都可以在我们的play.clickhouse.com环境中复现(参见 blogs 数据库)。
数据介绍
我们原始的表结构是这样的,其中记录了100多年的天气信息:
CREATE TABLE noaa
(
`station_id` LowCardinality(String),
`date` Date32,
`tempAvg` Int32 COMMENT 'Average temperature (tenths of a degrees C)',
`tempMax` Int32 COMMENT 'Maximum temperature (tenths of degrees C)',
`tempMin` Int32 COMMENT 'Minimum temperature (tenths of degrees C)',
`precipitation` UInt32 COMMENT 'Precipitation (tenths of mm)',
`snowfall` UInt32 COMMENT 'Snowfall (mm)',
`snowDepth` UInt32 COMMENT 'Snow depth (mm)',
`percentDailySun` UInt8 COMMENT 'Daily percent of possible sunshine (percent)',
`averageWindSpeed` UInt32 COMMENT 'Average daily wind speed (tenths of meters per second)',
`maxWindSpeed` UInt32 COMMENT 'Peak gust wind speed (tenths of meters per second)',
`weatherType` Enum8('Normal' = 0, 'Fog' = 1, 'Heavy Fog' = 2, 'Thunder' = 3, 'Small Hail' = 4, 'Hail' = 5, 'Glaze' = 6, 'Dust/Ash' = 7, 'Smoke/Haze' = 8, 'Blowing/Drifting Snow' = 9, 'Tornado' = 10, 'High Winds' = 11, 'Blowing Spray' = 12, 'Mist' = 13, 'Drizzle' = 14, 'Freezing Drizzle' = 15, 'Rain' = 16, 'Freezing Rain' = 17, 'Snow' = 18, 'Unknown Precipitation' = 19, 'Ground Fog' = 21, 'Freezing Fog' = 22),
`location` Point,
`elevation` Float32,
`name` LowCardinality(String)
) ENGINE = MergeTree() ORDER BY (station_id, date)每一行代表一个时间点的某天气站测量数据 - 每一行有一个 station_id 。利用 station_id 的前两位代表国家代码的事实,我们可以通过知道其前缀并使用子substring函数找到一个国家top 5的温度。例如,葡萄牙:
SELECT
tempMax / 10 AS maxTemp,
station_id,
date,
location,
name
FROM noaa
WHERE substring(station_id, 1, 2) = 'PO'
ORDER BY tempMax DESC
LIMIT 5
┌─maxTemp─┬─station_id──┬───────date─┬─location──────────┬─name───────────┐
│ 45.8 │ PO000008549 │ 1944-07-30 │ (-8.4167,40.2) │ COIMBRA │
│ 45.4 │ PO000008562 │ 2003-08-01 │ (-7.8667,38.0167) │ BEJA │
│ 45.2 │ PO000008562 │ 1995-07-23 │ (-7.8667,38.0167) │ BEJA │
│ 44.5 │ POM00008558 │ 2003-08-01 │ (-7.9,38.533) │ EVORA/C. COORD │
│ 44.2 │ POM00008558 │ 2022-07-13 │ (-7.9,38.533) │ EVORA/C. COORD │
└─────────┴─────────────┴────────────┴───────────────────┴────────────────┘
5 rows in set. Elapsed: 0.259 sec. Processed 1.08 billion rows, 7.46 GB (4.15 billion rows/s., 28.78 GB/s.)不幸的是,该查询需要全表扫描,因为它不能利用我们的主键 (station_id, date) 。
改进数据模型
我们社区的成员很快提出了一个简单的优化方法,通过减少从磁盘读取的数据量来提高上述查询的响应时间。可以跳过范式设计原则,并在修改成子查询之前,将 station_id单独存储在一个表中来实现。
首先,我们回顾一下这些建议,以便读者理解。下面我们创建一个站点表,并直接通过使用url函数插入数据来填充它。
CREATE TABLE stations
(
`station_id` LowCardinality(String),
`country_code` LowCardinality(String),
`state` LowCardinality(String),
`name` LowCardinality(String),
`lat` Float64,
`lon` Float64,
`elevation` Float32
)
ENGINE = MergeTree
ORDER BY (country_code, station_id)
INSERT INTO stations
SELECT
station_id,
substring(station_id, 1, 2) AS country_code,
trimBoth(state) AS state,
name,
lat,
lon,
elevation
FROM url('https://noaa-ghcn-pds.s3.amazonaws.com/ghcnd-stations.txt', Regexp, 'station_id String, lat Float64, lon Float64, elevation Float32, state String, name String')
SETTINGS format_regexp = '^(.{11})\\s+(\\-?\\d{1,2}\\.\\d{4})\\s+(\\-?\\d{1,3}\\.\\d{1,4})\\s+(\\-?\\d*\\.\\d*)\\s+(.{2})\\s(.*?)\\s{2,}.*$'
0 rows in set. Elapsed: 1.781 sec. Processed 123.18 thousand rows, 7.99 MB (69.17 thousand rows/s., 4.48 MB/s.)例如,我们现在假设我们的 noaa表不再有location、elevation和name字段。葡萄牙top 5的温度查询现在几乎可以用子查询解决:
SELECT
tempMax / 10 AS maxTemp,
station_id,
date,
location,
name
FROM noaa
WHERE station_id IN (
SELECT station_id
FROM stations
WHERE country_code = 'PO'
)
ORDER BY tempMax DESC
LIMIT 5
┌─maxTemp─┬─station_id──┬───────date─┬─location──────────┬─name───────────┐
│ 45.8 │ PO000008549 │ 1944-07-30 │ (-8.4167,40.2) │ COIMBRA │
│ 45.4 │ PO000008562 │ 2003-08-01 │ (-7.8667,38.0167) │ BEJA │
│ 45.2 │ PO000008562 │ 1995-07-23 │ (-7.8667,38.0167) │ BEJA │
│ 44.5 │ POM00008558 │ 2003-08-01 │ (-7.9,38.533) │ EVORA/C. COORD │
│ 44.2 │ POM00008558 │ 2022-07-13 │ (-7.9,38.533) │ EVORA/C. COORD │
└─────────┴─────────────┴────────────┴───────────────────┴────────────────┘
5 rows in set. Elapsed: 0.009 sec. Processed 522.48 thousand rows, 6.64 MB (59.81 million rows/s., 760.45 MB/s.)由于子查询利用了 stations 表的 country_code 主键,这样查询更快。此外,父查询也可以使用其主键。只需要读取小范围这些列,从而使磁盘上读取更少的数据,任何连接成本。正如我们社区的成员指出的,这种情况下保持数据反范式是有益的。
但这里有一个问题 - 我们依赖于天气数据上的location和name的反范式。假设我们没有这样做,为了避免重复,并遵循范式原则,并在stations表上分开的原则,我们需要一个full join(实际上,我们可能会保留location和name反范式,并接受存储成本):
SELECT
tempMax / 10 AS maxTemp,
station_id,
date,
stations.name AS name,
(stations.lat, stations.lon) AS location
FROM noaa
INNER JOIN stations ON noaa.station_id = stations.station_id
WHERE stations.country_code = 'PO'
ORDER BY tempMax DESC
LIMIT 5
┌─maxTemp─┬─station_id──┬───────date─┬─name───────────┬─location──────────┐
│ 45.8 │ PO000008549 │ 1944-07-30 │ COIMBRA │ (40.2,-8.4167) │
│ 45.4 │ PO000008562 │ 2003-08-01 │ BEJA │ (38.0167,-7.8667) │
│ 45.2 │ PO000008562 │ 1995-07-23 │ BEJA │ (38.0167,-7.8667) │
│ 44.5 │ POM00008558 │ 2003-08-01 │ EVORA/C. COORD │ (38.533,-7.9) │
│ 44.2 │ POM00008558 │ 2022-07-13 │ EVORA/C. COORD │ (38.533,-7.9) │
└─────────┴─────────────┴────────────┴────────────────┴───────────────────┘
5 rows in set. Elapsed: 0.488 sec. Processed 1.08 billion rows, 14.06 GB (2.21 billion rows/s., 28.82 GB/s.)遗憾的是,与我们之前的反范式方法相比,这需要全表扫描,所以更慢。这个原因是:
当运行一个JOIN时,与查询的其他阶段相比,没有执行顺序的优化。JOIN(在右表中搜索)在WHERE中的过滤和聚合之前运行。
我们还建议字典作为一个可能的解决方案。现在让我们展示一下,在数据已经遵循范式的原则下,我们如何使用字典来提高查询的性能。
创建字典
字典为我们提供了数据在内存中以键值存储的表示形式,优化了查找查询效率。我们可以利用这种结构来提高查询的性能,特别是当JOIN的一侧是在内存中的查找表时,JOIN查询可以获益。
选择源和键
字典目前可以从两个源填充:本地ClickHouse表和HTTP URLs*。字典的内容可以配置为定期重新加载,以反映源数据中的变化。
* 我们预期将来会扩展此功能,以包括在OSS中支持的其他源。
下面,我们使用 stations 表作为源创建我们的字典。
CREATE DICTIONARY stations_dict
(
`station_id` String,
`state` String,
`country_code` String,
`name` String,
`lat` Float64,
`lon` Float64,
`elevation` Float32
)
PRIMARY KEY station_id
SOURCE(CLICKHOUSE(TABLE 'stations'))
LIFETIME(MIN 0 MAX 0)
LAYOUT(complex_key_hashed_array())此处的 PRIMARY KEY 是 station_id ,直观地表示将在其上执行查找的列。值必须是唯一的,即具有相同主键的行将被去重。其他列表示属性。您可能已经注意到,我们已经将location分成 lat 和 lon ,因为字典的属性类型目前不支持Point类型。 LAYOUT 和 LIFETIME 不那么显而易见,需要一些解释。
选择布局(layout)
字典的布局控制了它如何存储在内存中以及主键的索引策略。每种布局选项都有不同的优缺点。
flat 类型为最大键值分配一个数组,例如,如果最大值为100k,则数组也将有100k的条目。这非常适合在源数据中有一个单调递增的主键。在这种情况下,它使用非常少的内存,并提供比基于哈希的替代方案快4-5倍的访问速度 - 只需要一个简单的数组偏移查找。但是,它的限制在于键大小也不能超过500k - 尽管这可以通过设置 max_array_size 来配置。对于比较大的稀疏分布,它本质上效率较低,在这种情况下也浪费内存。
对于您有非常大量的条目,大的键值和/或值的稀疏分布的情况,那么 flat 布局变得不那么理想。那么,我们通常会推荐基于哈希的字典 - 特别是 hashed_array 字典,它可以有效地支持数百万条目。这种布局比 hashed 布局更节省内存,而且几乎同样快。对于这种类型,只有一个哈希表用于存储主键,值提供特定属性数组中的偏移位置。这与hashed布局形成对比,尽管会稍微快一点,但需要为每个属性分配一个哈希表 - 因此消耗更多的内存。在大多数情况下,我们因此建议 hashed_array 布局 - 尽管用户在只有少数属性的情况下,应该尝试 hashed 。
所有这些类型也要求键可以转换为UInt64。如果不是,例如,它们是字符串,我们可以使用hashed字典的复杂变体: complex_key_hashed 和 complex_key_hashed_array ,来遵循上面相同的规则。
我们尝试使用下面的流程图来演示上述逻辑,以帮助您选择正确的布局(大多数时候):
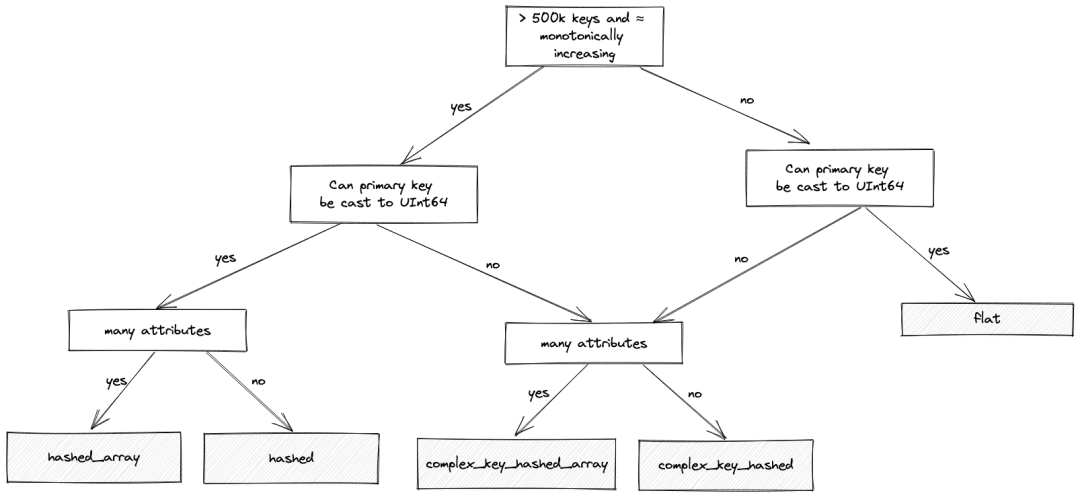
对于我们的数据,其中主键是String类型的 country_code ,我们选择 complex_key_hashed_array 类型,因为我们的字典在每种情况下都至少有三个属性。
注意:我们还有 hashed 和 complex_key_hashed 布局的稀疏变种。此布局旨在通过将主键分成组并在其中递增范围来实现O(1)时间操作。我们很少推荐这种布局,只有在您只有一个属性时,它才有效。尽管操作是常数时间的,但实际的常数通常高于非稀疏变种。最后,ClickHouse提供了如polygon和ip_trie等专门的布局。
选择生命周期
上面的字典DDL还为字典指定 LIFETIME 。这指定了字典应该多久重新读取源来刷新数据。这可以指定为秒数或范围,例如, LIFETIME(300) 或 LIFETIME(MIN 300 MAX 360) 。在后一种情况下,会选择一个在范围内均匀分布的随机时间。当多个服务器正在更新时,这确保了字典源上的负载随时间分布。我们例子中使用的值 LIFETIME(MIN 0 MAX 0) 意味着字典内容永远不会被更新 - 在我们的情况下很合适,因为我们的数据是静态的。
如果您的数据会被更新,并且您需要定期重新加载数据,则此行为可以通过返回行的invalidate_query参数来控制。如果此行的值在更新周期之间更改,ClickHouse知道必须重新获取数据。例如,这可以返回时间戳或行数。存在进一步的选项,以确保自上次更新以来只加载已更改的数据 - 请参见我们的文档,了解如何使用 update_field 的示例。
使用字典
尽管我们的字典已经创建,但它需要一个查询来将数据加载到内存中。这样做的最简单方法是发出一个简单的 dictGet 查询来检索单个值(将数据集加载到字典中作为一个副作用)或通过发出明确的 SYSTEM RELOAD DICTIONARY 命令。
SYSTEM RELOAD DICTIONARY stations_dict
0 rows in set. Elapsed: 0.561 sec.
SELECT dictGet(stations_dict, 'state', 'CA00116HFF6')
┌─dictGet(stations_dict, 'state', 'CA00116HFF6')─┐
│ BC │
└────────────────────────────────────────────────┘
1 row in set. Elapsed: 0.001 sec.上面的 dictGet 示例检索了国家代码 P0 的 station_id 值。
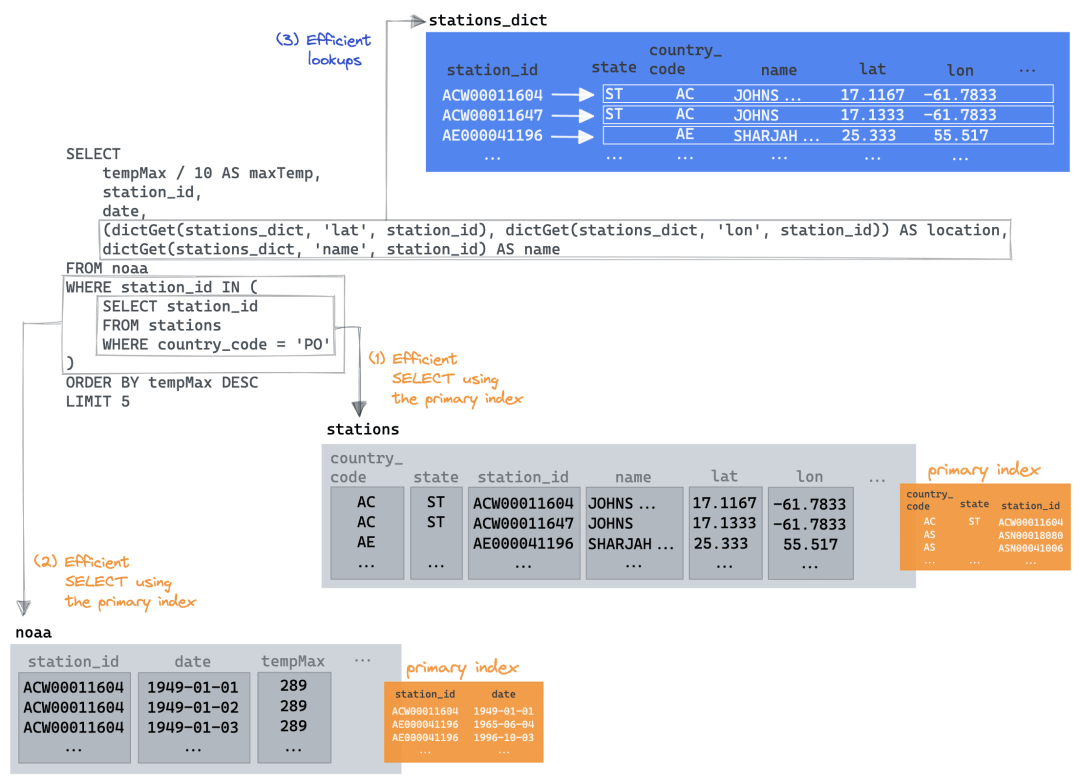
回到我们原来的Join查询,我们可以恢复我们的子查询,并仅为我们的location和name字段使用字典。
SELECT
tempMax / 10 AS maxTemp,
station_id,
date,
(dictGet(stations_dict, 'lat', station_id), dictGet(stations_dict, 'lon', station_id)) AS location,
dictGet(stations_dict, 'name', station_id) AS name
FROM noaa
WHERE station_id IN (
SELECT station_id
FROM stations
WHERE country_code = 'PO'
)
ORDER BY tempMax DESC
LIMIT 5
┌─maxTemp─┬─station_id──┬───────date─┬─location──────────┬─name───────────┐
│ 45.8 │ PO000008549 │ 1944-07-30 │ (40.2,-8.4167) │ COIMBRA │
│ 45.4 │ PO000008562 │ 2003-08-01 │ (38.0167,-7.8667) │ BEJA │
│ 45.2 │ PO000008562 │ 1995-07-23 │ (38.0167,-7.8667) │ BEJA │
│ 44.5 │ POM00008558 │ 2003-08-01 │ (38.533,-7.9) │ EVORA/C. COORD │
│ 44.2 │ POM00008558 │ 2022-07-13 │ (38.533,-7.9) │ EVORA/C. COORD │
└─────────┴─────────────┴────────────┴───────────────────┴────────────────┘
5 rows in set. Elapsed: 0.012 sec. Processed 522.48 thousand rows, 6.64 MB (44.90 million rows/s., 570.83 MB/s.)现在这就好多了!关键在于我们能够利用子查询优化,利用它的 country_code 主键,从中受益。然后,父查询能够限制 noaa 表读取,只返回那些返回的station ids,再次利用其主键来最小化数据读取。最后, dictGet 仅用于最后的5行,以检索name和location。我们在下面进行了可视化该过程:
经验丰富的字典用户可能会尝试其他方法。例如,我们可以:
-
删除子查询并使用 dictGet(stations_dict, 'country_code', station_id) = 'P0' 进行过滤。这没有更快(大约0.5秒),因为需要为每个station进行字典查找。我们在下面看到了一个类似的例子。
-
利用字典可以像表一样用于JOIN的事实(见下文)。这与上面的提议存在相同的挑战。
更复杂的事情
考虑下面这样一个查询:
使用美国滑雪度假村的列表和它们的相应位置,我们将其与最近5年内任何一个月雪量最多的前1000个气象站点进行join。通过按`geoDistance`进行排序,并限制结果距离小于20km,我们为每个度假村选择最佳结果,并按总雪量进行排序。请注意,我们还将度假村限制为海拔高于1800m的地方,作为滑雪条件好的一个宽泛指标。
SELECT
resort_name,
total_snow / 1000 AS total_snow_m,
resort_location,
month_year
FROM
(
WITH resorts AS
(
SELECT
resort_name,
state,
(lon, lat) AS resort_location,
'US' AS code
FROM url('https://gist.githubusercontent.com/Ewiseman/b251e5eaf70ca52a4b9b10dce9e635a4/raw/9f0100fe14169a058c451380edca3bda24d3f673/ski_resort_stats.csv', CSVWithNames)
)
SELECT
resort_name,
highest_snow.station_id,
geoDistance(resort_location.1, resort_location.2, station_location.1, station_location.2) / 1000 AS distance_km,
highest_snow.total_snow,
resort_location,
station_location,
month_year
FROM
(
SELECT
sum(snowfall) AS total_snow,
station_id,
any(location) AS station_location,
month_year,
substring(station_id, 1, 2) AS code
FROM noaa
WHERE (date > '2017-01-01') AND (code = 'US') AND (elevation > 1800)
GROUP BY
station_id,
toYYYYMM(date) AS month_year
ORDER BY total_snow DESC
LIMIT 1000
) AS highest_snow
INNER JOIN resorts ON highest_snow.code = resorts.code
WHERE distance_km < 20
ORDER BY
resort_name ASC,
total_snow DESC
LIMIT 1 BY
resort_name,
station_id
)
ORDER BY total_snow DESC
LIMIT 5在使用字典优化之前,我们先用实际的表替换包含度假村的CTE。这确保我们的数据在ClickHouse集群中是本地的,可以避免获取度假村的HTTP延迟。
CREATE TABLE resorts
(
`resort_name` LowCardinality(String),
`state` LowCardinality(String),
`lat` Nullable(Float64),
`lon` Nullable(Float64),
`code` LowCardinality(String)
)
ENGINE = MergeTree
ORDER BY state当我们填充这个表时,我们还有机会将state字段与stations表对齐(稍后我们会使用它)。度假村使用州名,而站点使用state代码。为了确保它们是一致的,我们可以在插入resorts表时将州名映射到代码。这为我们提供了另一个创建基于HTTP源的字典的机会。
CREATE DICTIONARY states
(
`name` String,
`code` String
)
PRIMARY KEY name
SOURCE(HTTP(URL 'https://gist.githubusercontent.com/gingerwizard/b0e7c190474c847fdf038e821692ce9c/raw/19fdac5a37e66f78d292bd8c0ee364ca7e6f9a57/states.csv' FORMAT 'CSVWithNames'))
LIFETIME(MIN 0 MAX 0)
LAYOUT(COMPLEX_KEY_HASHED_ARRAY())
SELECT *
FROM states
LIMIT 2
┌─name─────────┬─code─┐
│ Pennsylvania │ PA │
│ North Dakota │ ND │
└──────────────┴──────┘
2 rows in set. Elapsed: 0.001 sec.在插入时,我们可以使用 dictGet 函数将我们的州名映射到度假村的州代码。
INSERT INTO resorts SELECT
resort_name,
dictGet(states, 'code', state) AS state,
lat,
lon,
'US' AS code
FROM url('https://gist.githubusercontent.com/Ewiseman/b251e5eaf70ca52a4b9b10dce9e635a4/raw/9f0100fe14169a058c451380edca3bda24d3f673/ski_resort_stats.csv', CSVWithNames)
0 rows in set. Elapsed: 0.389 sec.现在,我们的原始查询显然更简单了。
SELECT
resort_name,
total_snow / 1000 AS total_snow_m,
resort_location,
month_year
FROM
(
SELECT
resort_name,
highest_snow.station_id,
geoDistance(lon, lat, station_location.1, station_location.2) / 1000 AS distance_km,
highest_snow.total_snow,
station_location,
month_year,
(lon, lat) AS resort_location
FROM
(
SELECT
sum(snowfall) AS total_snow,
station_id,
any(location) AS station_location,
month_year,
substring(station_id, 1, 2) AS code
FROM noaa
WHERE (date > '2017-01-01') AND (code = 'US') AND (elevation > 1800)
GROUP BY
station_id,
toYYYYMM(date) AS month_year
ORDER BY total_snow DESC
LIMIT 1000
) AS highest_snow
INNER JOIN resorts ON highest_snow.code = resorts.code
WHERE distance_km < 20
ORDER BY
resort_name ASC,
total_snow DESC
LIMIT 1 BY
resort_name,
station_id
)
ORDER BY total_snow DESC
LIMIT 5
┌─resort_name──────────┬─total_snow_m─┬─resort_location─┬─month_year─┐
│ Sugar Bowl, CA │ 7.799 │ (-120.3,39.27) │ 201902 │
│ Donner Ski Ranch, CA │ 7.799 │ (-120.34,39.31) │ 201902 │
│ Boreal, CA │ 7.799 │ (-120.35,39.33) │ 201902 │
│ Homewood, CA │ 4.926 │ (-120.17,39.08) │ 201902 │
│ Alpine Meadows, CA │ 4.926 │ (-120.22,39.17) │ 201902 │
└──────────────────────┴──────────────┴─────────────────┴────────────┘
5 rows in set. Elapsed: 0.673 sec. Processed 580.53 million rows, 4.85 GB (862.48 million rows/s., 7.21 GB/s.)注意执行时间,看看我们是否可以进一步改进。这个查询仍然假设location是反范式的到我们的天气测量noaa表上。现在,我们可以从 stations_dict 字典中读取这个字段。这也方便我们获取站点state,并使用这个状态与resorts表进行join,而不是使用code。这种连接更小,也更快,也就是说,我们不再是将所有站点与所有美国度假村join,而是仅限于同一个州的度假村。
我们的resorts表实际上很小(364条目)。尽管将其移动到字典可能不会为这个查询带来任何实际的性能优势,但考虑到其大小,它可能代表了存储数据的合理方法。我们选择 resort_name 作为我们的主键,因为这必须是唯一的,如前面所提到的。
CREATE DICTIONARY resorts_dict
(
`state` String,
`resort_name` String,
`lat` Nullable(Float64),
`lon` Nullable(Float64)
)
PRIMARY KEY resort_name
SOURCE(CLICKHOUSE(TABLE 'resorts'))
LIFETIME(MIN 0 MAX 0)
LAYOUT(COMPLEX_KEY_HASHED_ARRAY())现在,我们修改查询语句,尽可能使用 stations_dict ,并在 resorts_dict 上进行连接。注意我们仍然在 state 列上进行连接,尽管它在我们的resorts字典中不是主键。在这种情况下,我们使用JOIN语法,字典会像表一样被扫描。
SELECT
resort_name,
total_snow / 1000 AS total_snow_m,
resort_location,
month_year
FROM
(
SELECT
resort_name,
highest_snow.station_id,
geoDistance(resorts_dict.lon, resorts_dict.lat, station_lon, station_lat) / 1000 AS distance_km,
highest_snow.total_snow,
(resorts_dict.lon, resorts_dict.lat) AS resort_location,
month_year
FROM
(
SELECT
sum(snowfall) AS total_snow,
station_id,
dictGet(stations_dict, 'lat', station_id) AS station_lat,
dictGet(stations_dict, 'lon', station_id) AS station_lon,
month_year,
dictGet(stations_dict, 'state', station_id) AS state
FROM noaa
WHERE (date > '2017-01-01') AND (state != '') AND (elevation > 1800)
GROUP BY
station_id,
toYYYYMM(date) AS month_year
ORDER BY total_snow DESC
LIMIT 1000
) AS highest_snow
INNER JOIN resorts_dict ON highest_snow.state = resorts_dict.state
WHERE distance_km < 20
ORDER BY
resort_name ASC,
total_snow DESC
LIMIT 1 BY
resort_name,
station_id
)
ORDER BY total_snow DESC
LIMIT 5
┌─resort_name──────────┬─total_snow_m─┬─resort_location─┬─month_year─┐
│ Sugar Bowl, CA │ 7.799 │ (-120.3,39.27) │ 201902 │
│ Donner Ski Ranch, CA │ 7.799 │ (-120.34,39.31) │ 201902 │
│ Boreal, CA │ 7.799 │ (-120.35,39.33) │ 201902 │
│ Homewood, CA │ 4.926 │ (-120.17,39.08) │ 201902 │
│ Alpine Meadows, CA │ 4.926 │ (-120.22,39.17) │ 201902 │
└──────────────────────┴──────────────┴─────────────────┴────────────┘
5 rows in set. Elapsed: 0.170 sec. Processed 580.73 million rows, 2.87 GB (3.41 billion rows/s., 16.81 GB/s.)很好,速度提高了两倍以上!现在,细心的读者可能已经注意到我们跳过了一个可能的优化。我们完全可以用字典查找值来替换我们的海拔过滤条件 elevation > 1800 ,即 dictGet(blogs.stations_dict, 'elevation', station_id) > 1800 ,从而避免读取表吗?实际上,这会更慢,因为每一行都要进行字典查找,这比过滤有序的海拔数据要慢 - 后者受益于子句移到PREWHERE。在这种情况下,我们受益于海拔数据的反范式。这与我们在早期的查询中为了按 country_code 过滤而没有使用 dictGet 是类似的。
因此,这里的建议是要进行测试!如果dictGet需要应用于表中的大部分行,例如在条件中,那么您可能最好直接使用ClickHouse的原生数据结构和索引。
最终建议
-
我们所描述的字典布局完全存放在内存中。请注意它们的使用情况并测试任何布局更改。您可以使用system.dictionaries表和 bytes_allocated 列来跟踪它们的内存开销。此表还包括一个 last_exception 列,可用于诊断问题。
SELECT
*,
formatReadableSize(bytes_allocated) AS size
FROM system.dictionaries
LIMIT 1
FORMAT Vertical
Row 1:
──────
database: blogs
name: resorts_dict
uuid: 0f387514-85ed-4c25-bebb-d85ade1e149f
status: LOADED
origin: 0f387514-85ed-4c25-bebb-d85ade1e149f
type: ComplexHashedArray
key.names: ['resort_name']
key.types: ['String']
attribute.names: ['state','lat','lon']
attribute.types: ['String','Nullable(Float64)','Nullable(Float64)']
bytes_allocated: 30052
hierarchical_index_bytes_allocated: 0
query_count: 1820
hit_rate: 1
found_rate: 1
element_count: 364
load_factor: 0.7338709677419355
source: ClickHouse: blogs.resorts
lifetime_min: 0
lifetime_max: 0
loading_start_time: 2022-11-22 16:26:06
last_successful_update_time: 2022-11-22 16:26:06
loading_duration: 0.001
last_exception:
comment:
size: 29.35 KiB-
虽然dictGet很可能是您最常使用的字典功能,但还存在其他变体,其中dictGetOrDefault和dictHas尤为有用。另外,请注意类型特定的函数,例如dictGetFloat64。
-
flat字典的大小限制为500k条目。虽然这个限制可以扩展,但请将其视为考虑hashed布局的提醒。
结论
在这篇文章中,我们展示了如何保持数据符合范式有时可以带来更快的查询,尤其是使用字典时。我们提供了一些简单和复杂的例子,说明在哪些地方字典是有价值的,并得出了一些有用的建议。

联系我们
手机号:13910395701
满足您所有的在线分析列式数据库管理需求