MapReduce概述
- MapReduce(MR)本质上是一种用于数据处理的编程模型;MapReduce用于海量数据的计算,HDFS用于海量数据的存储(Hadoop Distributed File System,Hadoop分布式文件系统)。
- Hadoop MapReduce 是一个编程框架,Hadoop环境中,可运行用各种语言编写的MapReduce程序,用于创建在大型商用硬件集群上处理大量数据的应用程序,类似于JRE环境,可以在这个架构下开发应用程序。
- MapReduce 程序本质上并行,本质是通过并行计算提升算力。
- MapReduce是一种编程模型,用于通过集群上的并行分布式算法处理大型数据集。MapReduce会将任务分为小部分,将它们分配给不同系统来独立处理每个部分,在处理完所有零件并进行分析之后,将输出收集到一个位置,然后为给定问题输出数据集。
- MapReduce使用的基本信息单位是键值对。在通过MapReduce模型传递之前,所有结构化或非结构化数据都需要转换为键值对。
- MapReduce模型具有两个不同的功能,映射功能和归约功能。
- MapReduce 的工作模式主要分为 Map 阶段和还原阶段(shuffle阶段和reducer阶段)。
- 操作顺序始终为:Map -> Shuffle -> Reduce
- Map阶段:Map阶段是MapReduce框架中的关键步骤,映射器将为非结构化数据提供结构,映射器将一次处理一个键值对,一个输入可以产生任意数量的输出,Map函数将处理数据并生成几个小数据块。
- 还原阶段:shuffle阶段和reducer阶段一起称为还原阶段,Reducer将来自映射器的输出作为输入,并按照程序员的指定进行最终输出,此新输出将保存到HDFS。Reducer将从映射器中获取所有键-值对,并检查所有键与值的关联;将获取与单个键关联的所有值,并将提供任意数量的键值对的输出。
- MapReduce是顺序计算,为保障Reducer正常工作,Mapper必须完成执行,否则Reducer阶段将不会运行。
- 在 Hadoop 集群中,计算节点一般和存储节点相同,即 MapReduce 框架和 HDFS(Hadoop 分布式文件系统)均运行在同一组节点上。这种配置允许框架有效地调度已经存在数据的节点上的作业,使得跨集群的带宽具有较高的聚合度,能够有效利用资源。
MapReduce 工作原理
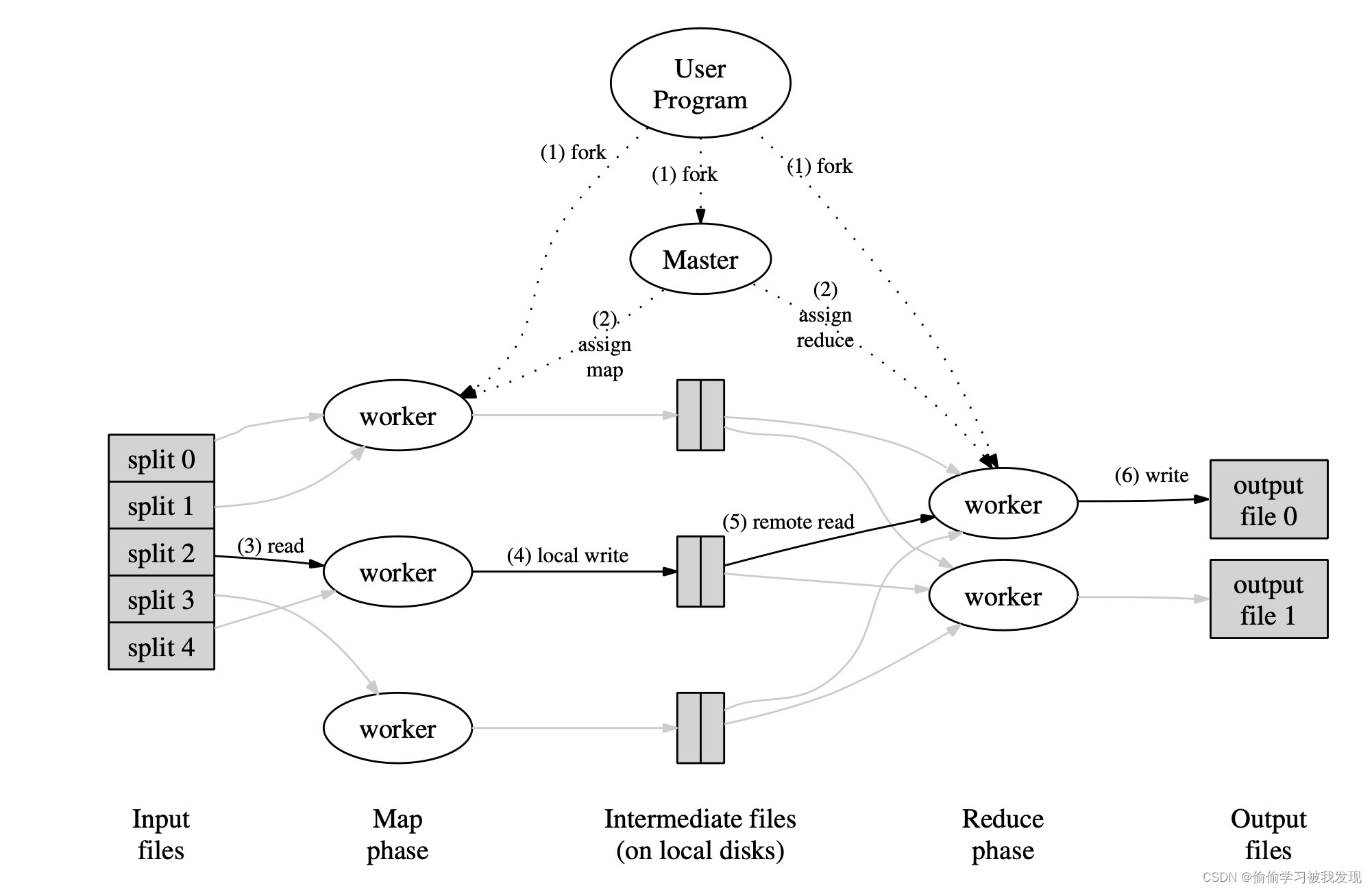
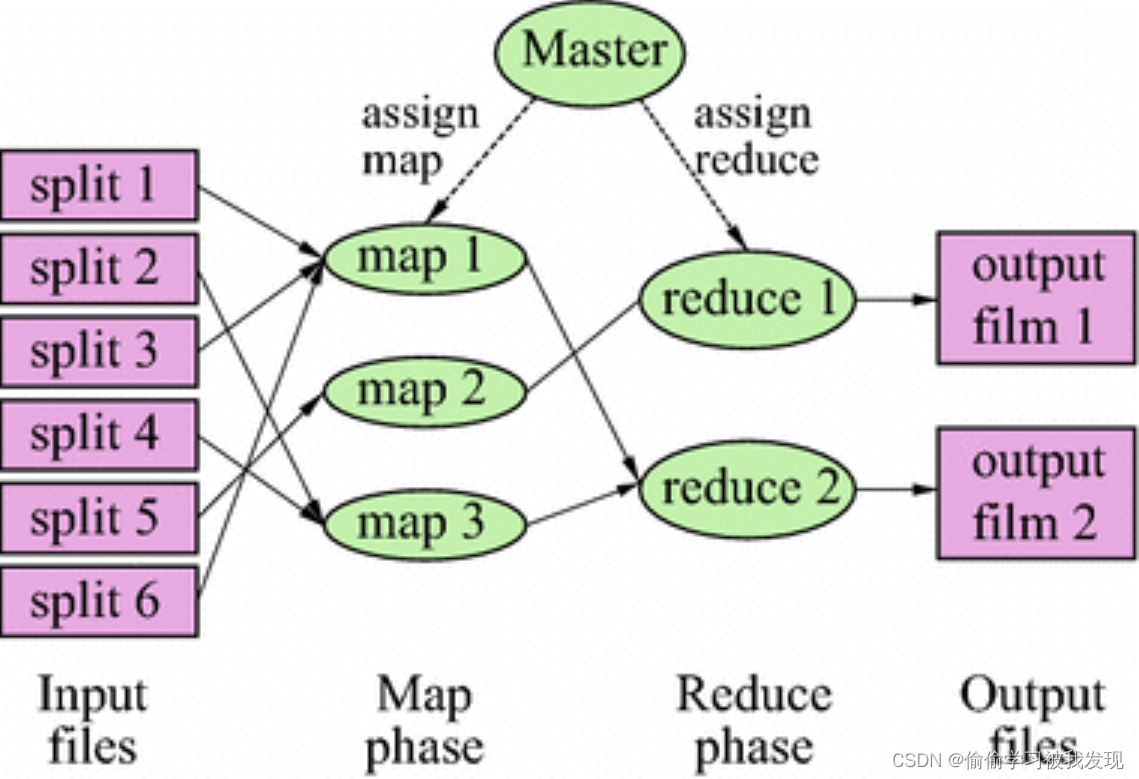
一个 MapReduce 任务(Job)通常将输入的数据集分割成独立的块,这些块被 map 任务以完全并行的方式处理。框架对映射(map)的输出进行排序,然后将其输入到 reduce 任务中。通常,作业的输入和输出都存储在文件系统中。框架负责调度任务、监视任务并重新执行失败的任务。
上面说到,MapReduce 框架只对 <key, value> 键值对形式的键值对进行处理。
该框架会将任务的输入当成一组 <key, value> 键值对,最后也会生成一组 <key, value> 键值对作为结果。其中的 key 和 value 可以根据具体问题将其理解为不同的类型。
key 和 value 的类必须由框架来完成序列化,因此我们需要做的就是实现其中的可写接口(Writable)。此外,对于其中的一些关键类还必须实现 WritableComparable 接口,以便于框架对其进行排序。
一个 MapReduce 作业从输入到输出的过程中,经历了以下过程:
(输入的原始数据)<k1, v1> -> Map -> <k2, v2> -> Combine -> <k2, v2> -> Reduce -> <k3, v3>(输出的计算结果)。
ResourceManager
MapReduce 框架由单个主节点(Master)的 ResourceManager、每个从节点(Slave) NodeManager 和每个应用程序的 MRAppMaster组成。
在编程框架完善并打包之后,Hadoop 的作业客户端(job client)可以将作业(一般是 jar 包或者可执行文件)和配置项提交给 ResourceManager,ResourceManager负责将作业代码和配置项分发给从节点(Slave),之后ResourceManager负责作业的调度和监视,同时也向作业客户端提供状态和诊断信息。
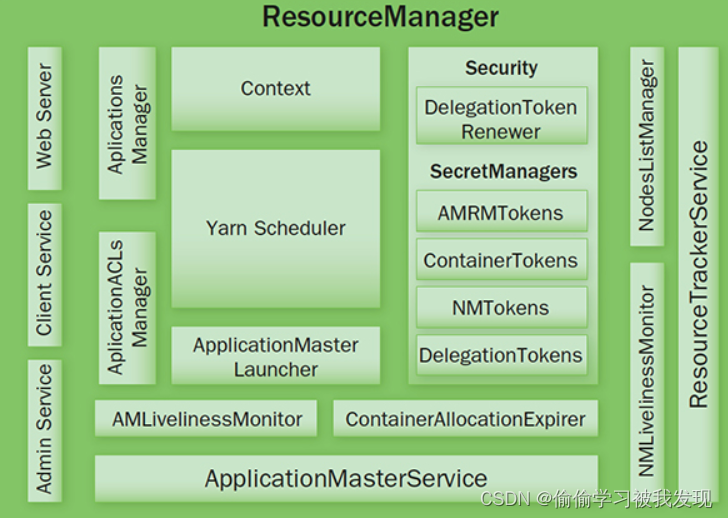
Client Service:应用提交、终止、输出信息(应用、队列、集群等的状态信息)。Adaminstration Service: 队列、节点、Client 权限管理。ApplicationMasterService: 注册、终止 ApplicationMaster, 获取 ApplicationMaster 的资源申请或取消的请求,并将其异步地传给 Scheduler, 单线程处理。ApplicationMaster Liveliness Monitor: 接收 ApplicationMaster 的心跳消息,如果某个 ApplicationMaster 在一定时间内没有发送心跳,则被任务失效,其资源将会被回收,然后 ResourceManager 会重新分配一个 ApplicationMaster 运行该应用(默认尝试 2 次)。Resource Tracker Service: 注册节点, 接收各注册节点的心跳消息。NodeManagers Liveliness Monitor: 监控每个节点的心跳消息,如果长时间没有收到心跳消息,则认为该节点无效, 同时所有在该节点上的 Container 都标记成无效,也不会调度任务到该节点运行。ApplicationManager: 管理应用程序,记录和管理已完成的应用。ApplicationMaster Launcher: 一个应用提交后,负责与 NodeManager 交互,分配 Container 并加载 ApplicationMaster,也负责终止或销毁。YarnScheduler: 资源调度分配, 有 FIFO(with Priority),Fair,Capacity 方式。ContainerAllocationExpirer: 管理已分配但没有启用的 Container,超过一定时间则将其回收。
MPP与MapReduc区别
MPP和MapReduc的区别主要体现在计算方式上,MPP和MapReduce都是用于实现并行化处理的技术,但它们采用的并行化策略不同。
关于MPP理解
MPP(Massively Parallel Processing)即大规模并行处理,是一种在多个处理器间分配工作负载的并行计算模型,常用于传统的关系数据库管理系统中,以提高数据库处理的性能和吞吐量。MPP系统通常由成百上千个节点(节点指的是一组处理器和存储器)组成,每个节点都运行数据库的一个实例,各个节点之间通过高速网络互相通信,MPP系统会将数据表分片(通过切割表中的行),这些数据片会被分配到每个节点上,每个节点都有独立的存储器。
MPP系统的平行计算方式是将数据库划分为若干个子部分,设定若干个可供并行计算的操作,每个操作运行在一个节点上,从而并行地进行处理,由于MPP的数据是在不同节点分片存储,因此一般来说MPP的计算任务每一部分是和固定节点绑定的。
MapReduc是一种基于“映射(Map)”和“化简(Reduce)”的并行计算模型,主要用于海量数据的分布式处理。一般来说,MapReduce将大数据集分成若干个小数据块,并且将每个数据块分配给不同的计算节点来处理。每个节点都独立地对数据块进行“Map”操作,得到中间数据,然后将相同中间数据的部分发送到同一节点进行“Reduce”操作,最终将得到的数据合并起来,得到最终结果。
因此,MPP和MapReduce在并行计算中的采用策略不同,更应用于不同的领域。MPP主要用于传统的关系型数据库的大规模并行处理,适合相对简单的计算场景。MapReduce更适合分布式计算、海量数据的分析和处理,适用于更复杂、更庞大的场景。虽然两种技术都有其优缺点,但在不同的情况下,它们都有效地推动了计算的并行处理。