文章目录
0.前言
我们大家想想目前与大数据相关的著名的开源组件有哪些呢?比如说最早期的批处理框架 Hadoop?流计算平台 Storm,火了一阵子的 Spark?异或其他领域数仓的 Hive,KV 存储的 HBase?这些都是非常著名的开源项目、我大概整理了一个图可供大家参考。而本章我们着重了解一下大数据领域的分布式实时数据处理老大哥Storm。虽然近年来 Apache Flink 成为了分布式实时数据处理领域的重要技术,并且在某些方面甚至超越了 Apache Storm。Flink 提供了更加高级的流处理和批处理功能,具有更好的性能和易用性。但是 Storm 仍然是一个非常有价值的技术,并且在各公司已经有了很深的技术沉淀和最佳实践,还支持着公司和客户的核心业务。Storm 具有更加灵活的编程模型和更加丰富的 API,可以满足各种实时数据处理的需求。Storm 也拥有一个庞大的社区和生态系统,支持各种数据源和数据处理工具的集成和扩展。因此,在选择实时数据处理技术时,应该根据具体需求进行综合评估,选择最适合自己的技术。本次我们分三个章节着重讲解一下。
1. 什么是 Apache Storm?
Apache Storm 是一个分布式实时计算系统,可以处理大规模实时数据流。它是一个开源项目,最初由 Twitter 开发并贡献给 Apache 软件基金会。Storm 提供了一个易于使用的编程模型,支持高效、可靠、可扩展的数据处理流程,广泛应用于实时数据分析、实时推荐、实时监控等领域。
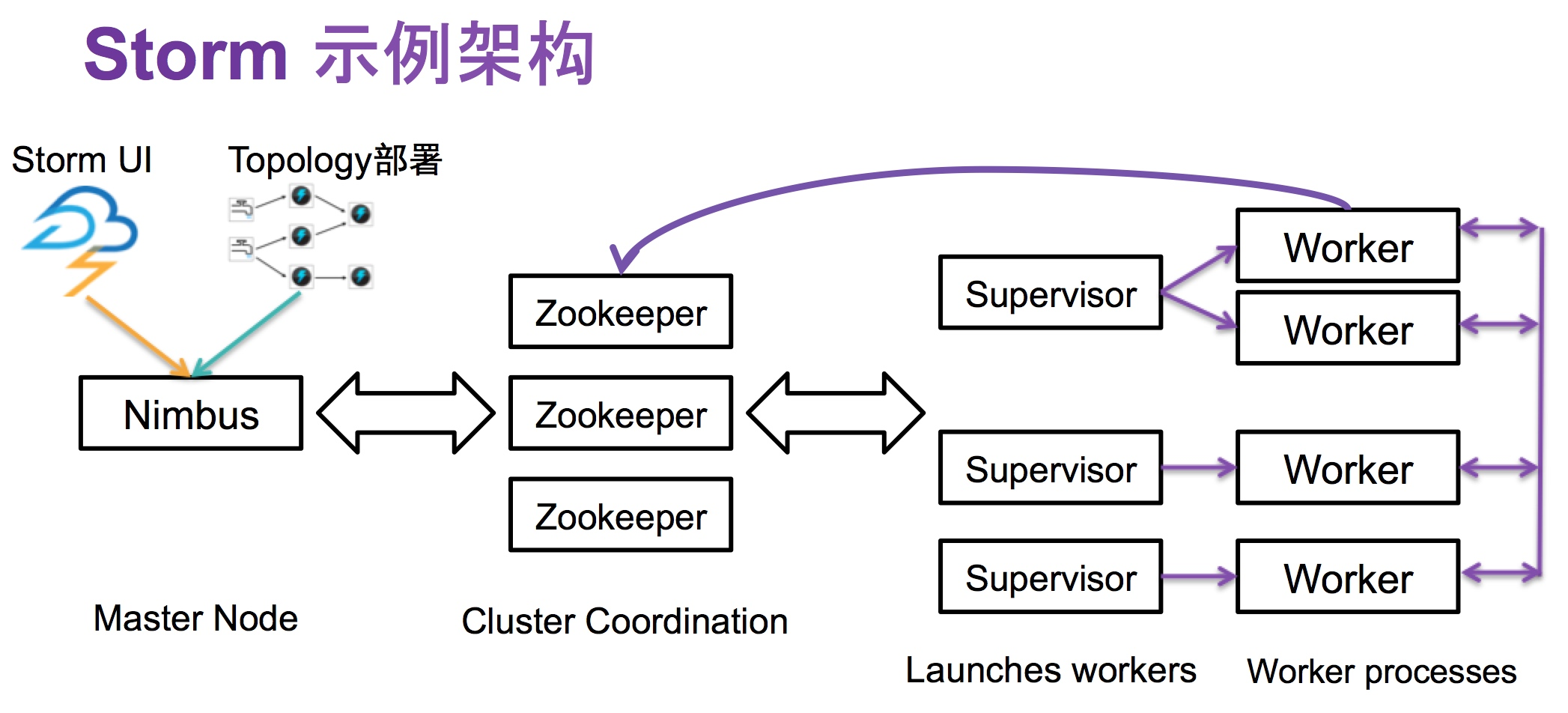
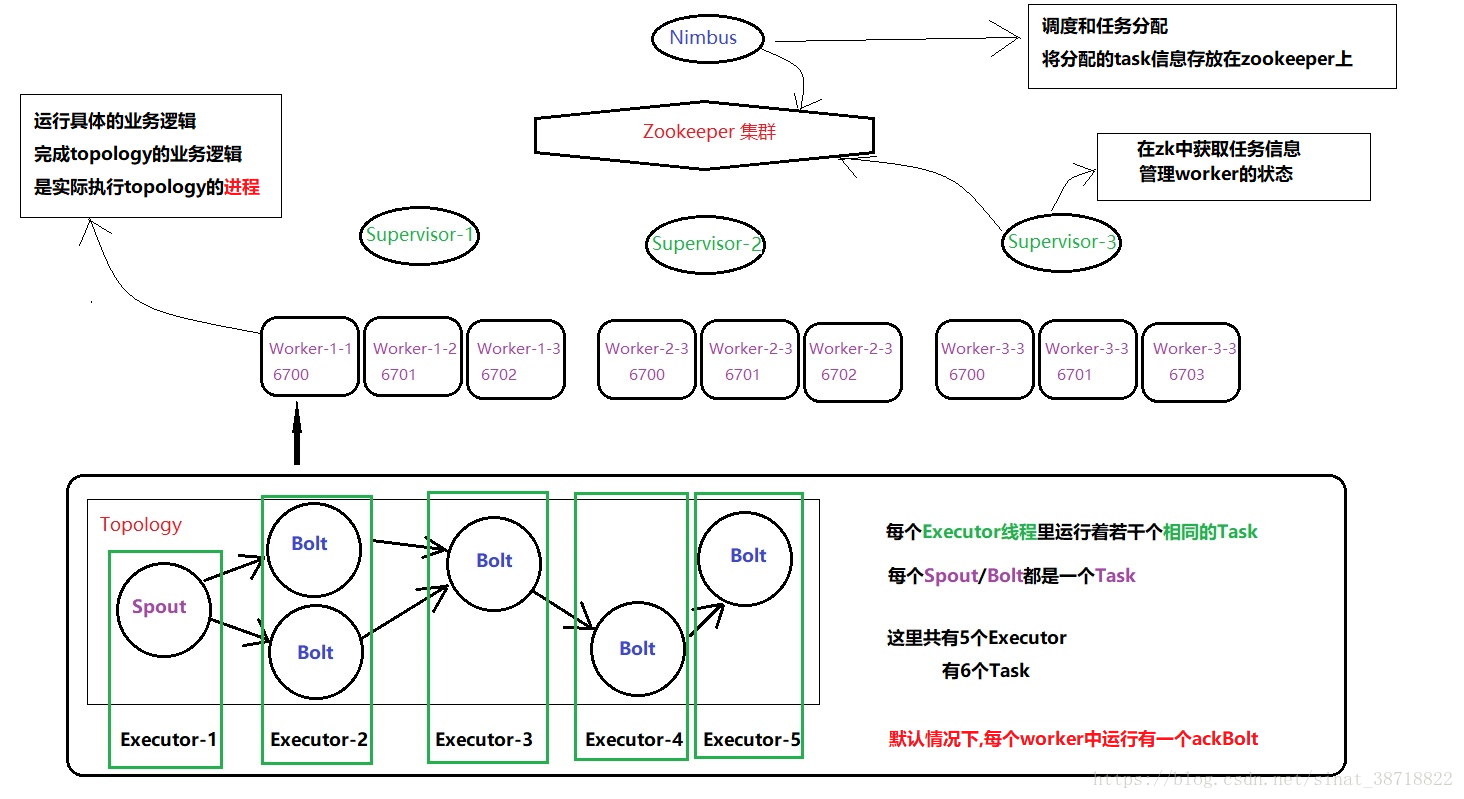
从图中我们梳理出以下的关系
- Nimbus 通过与 Zookeeper 的交互,管理 Storm 集群中的所有组件,包括 Supervisor 和 Worker。
- Zookeeper 维护着 Storm 集群的状态和元数据,包括 Topology 的元数据、Worker 的状态、Supervisor 的信息等。
- Supervisor 负责管理 Worker 进程,监控和维护 Worker 的状态和资源使用情况。
- Worker 运行在 Supervisor 中,处理 Tuple 并将处理后的数据发送给下游的 Bolt 或者输出到外部存储系统。

1.1. Nimbus
Nimbus 是 Storm 的主节点,负责 Topology 的分配和调度。Nimbus 接收到 Topology 的提交请求后,会对 Topology 进行编译、打包和分发,然后将任务分配给集群中的 Supervisor 和 Worker。Nimbus 还负责监控和管理整个 Storm 集群的运行状态,例如监控 Worker 的状态、处理故障和异常、维护 Topology 的元数据等。
1.2. Zookeeper
Zookeeper 是 Storm 集群的分布式协调服务,负责管理集群中各个组件的状态和配置信息。Nimbus、Supervisor 和 Worker 都会将自己的状态和元数据注册到 Zookeeper 中,以便其他组件可以发现和访问它们。Zookeeper 还提供了分布式锁、协调和通知机制,能够保证 Storm 集群的高可用性和一致性。
1.3. Supervisor
Supervisor 是 Storm 集群中的工作节点,负责运行和管理 Worker 进程。每个 Supervisor 可以运行多个 Worker 进程,每个 Worker 进程运行一个或多个 Task。Supervisor 还负责监控 Worker 进程的状态和资源使用情况,例如 CPU、内存、磁盘等。
1.4. Worker
Worker 是 Storm 集群中的实际工作进程,负责具体的数据处理和传递工作。Worker 运行在 Supervisor 中,可以运行多个 Task。每个 Worker 负责处理一部分数据流,通过处理 Tuple 来实现实时数据处理和转换。Worker 还会将处理后的数据发送给下游的 Bolt 或者输出到外部存储系统。
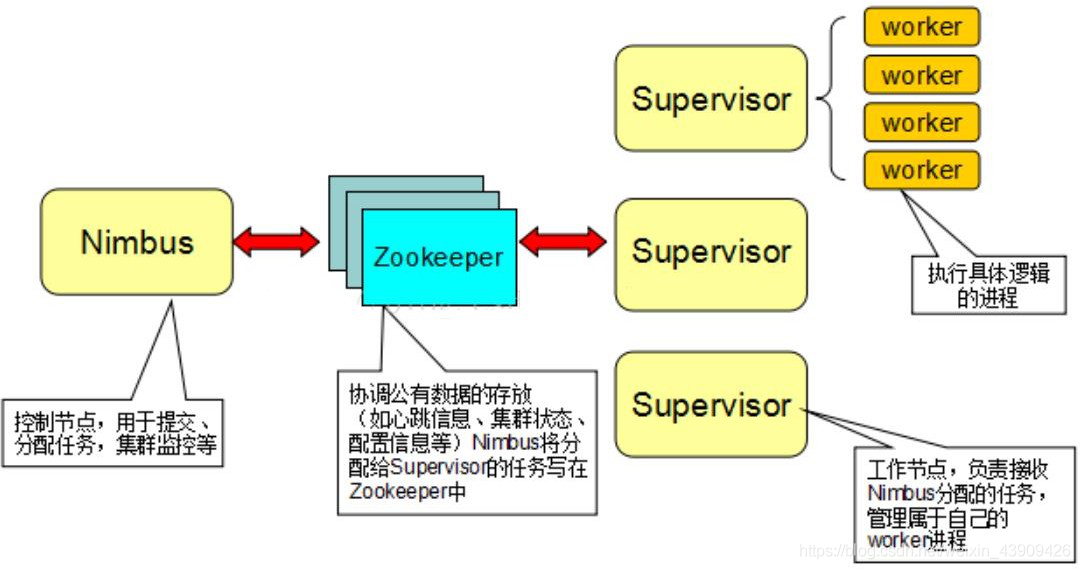
1.5 集群模式下各组件职责
2. 核心概念
Apache Storm 是一个分布式实时计算系统,具有以下核心概念:
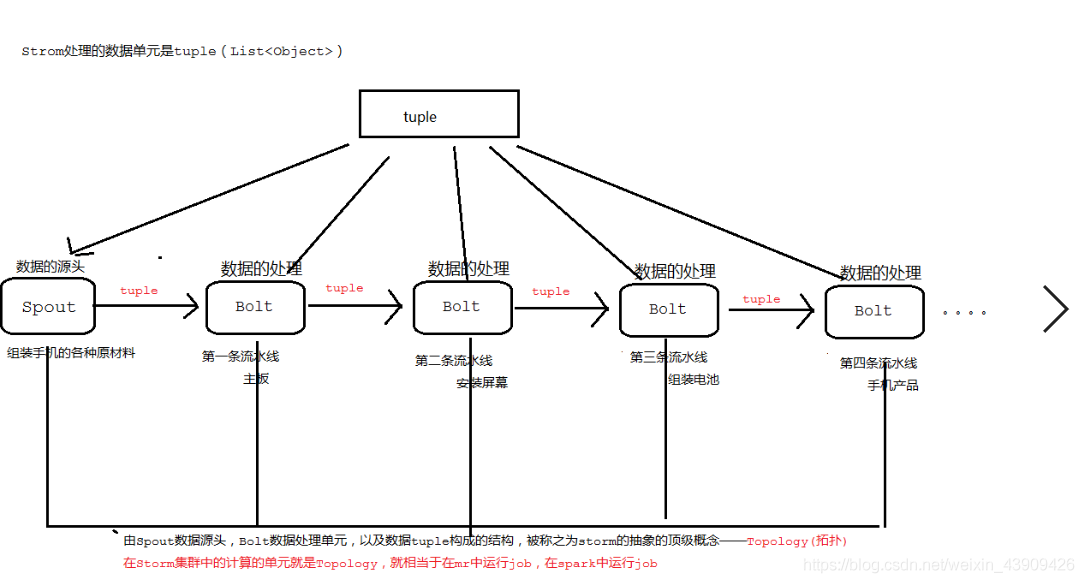
| 组件 | 描述 |
|---|---|
| Topology | Storm 中的最高级别的抽象概念,表示一个实时数据处理流程。Topology 由 Spout 和 Bolt 组成,可以看作是一个有向无环图(DAG),其中 Spout 是数据源,Bolt 是数据处理节点。 |
| Spout | 流的来源,也叫做源节点,。一般来说,Storm 接受来自原始数据源的输入数据,如 Twitter Streaming API、Apache Kafka 队列、Kestrel 队列等。否则,您可以编写 spout 从数据源读取数据。“ISpout”是实现spout的核心接口,具体接口有IRichSpout、BaseRichSpout、KafkaSpout等。负责从数据源中读取实时数据流,并将数据流发送给下游的 Bolt 节点。Spout 可以从文件、数据库、消息队列、网络等不同的数据源中读取数据,并通过可靠的方式将数据发送给 Bolt 节点。 |
| Bolt | Bolts 是逻辑处理单元。Spout 将数据传递给 bolts 和 bolts 进程并产生一个新的输出流。Bolts 可以执行过滤、聚合、连接、与数据源和数据库交互的操作。Bolt 接收数据并发送到一个或多个 Bolt。“IBolt”是实现bolt的核心接口。一些常用的接口有 IRichBolt、IBasicBolt 等Topology 中的处理节点,负责对数据流进行实时处理和转换。Bolt 可以对数据流进行过滤、聚合、计算、转换等各种操作,并通过可靠的方式将处理后的数据发送给下游的 Bolt 节点或者输出到外部存储系统。 |
| Stream | 数据流的抽象概念,表示一组有序的数据记录。Stream 可以包含多个字段,每个字段可以是不同的数据类型。Stream 是 Topology 中 Spout 和 Bolt 之间的通信载体,可以传递实时数据流和元数据信息。 |
| Tuple | Storm 中的基本数据单元,表示一个有序的字段组成的数据记录。Tuple 可以看作是 Stream 中的一个数据元素,每个 Tuple 由多个字段组成,字段可以是不同的数据类型。Tuple 是 Storm 中数据处理和传递的基本单位。 |
| Task | Bolt 或者 Spout 在集群中的实例,负责具体的数据处理和传递工作。Topology 中的每个 Bolt 或者 Spout 都会被分配若干个 Task,每个 Task 负责处理一部分数据流。 |
| Worker | Storm 集群中的一个进程,负责启动和运行一个或多个 Task。每个 Worker 可以运行在独立的机器上,也可以运行在同一台机器上的不同进程中。 |
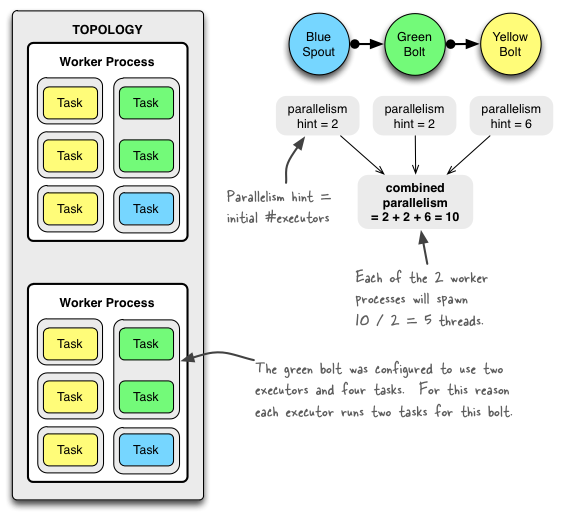
2.1基本架构和任务模型
根据下图,我们来理解一下Storm 核心组件的作用和关系。
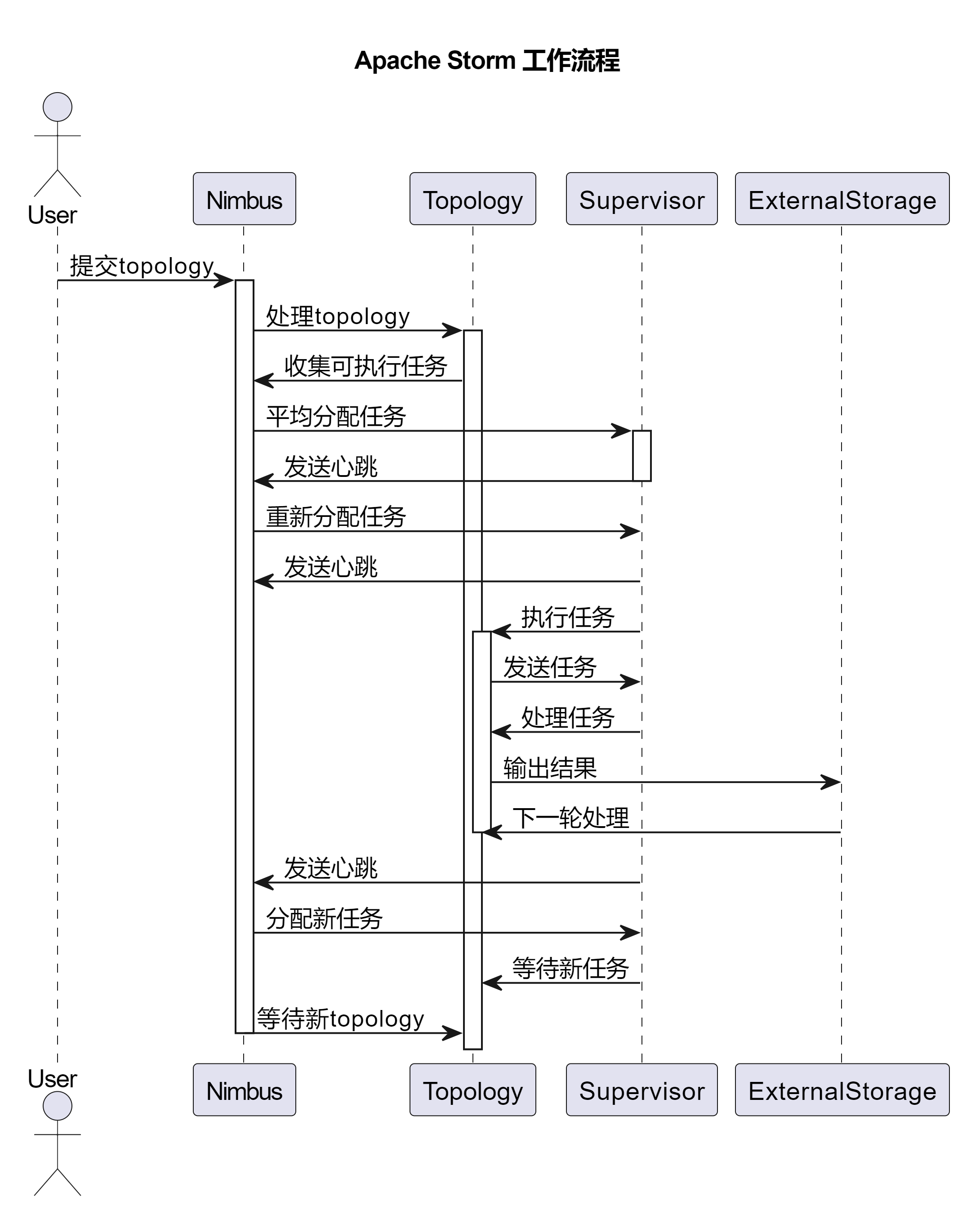
2.2 工作流程
3. 源码地址
源码地址 https://github.com/apache/storm
3.1. 代码结构
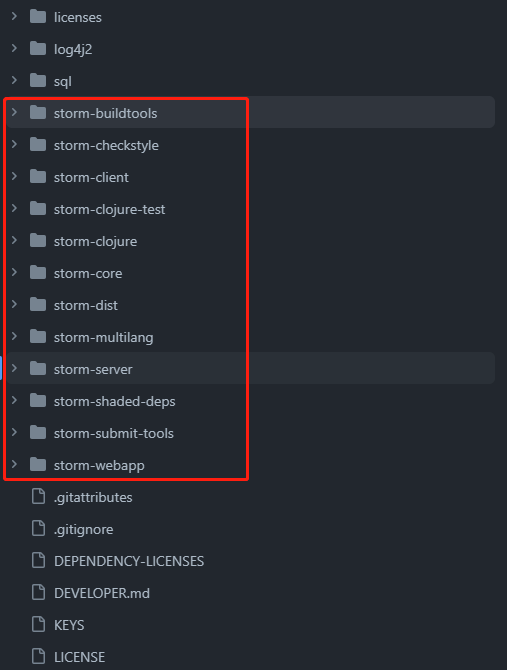
3.1. 核心模块介绍
| 目录 | 描述 |
|---|---|
| storm-buildtools | 构建和测试 Storm 项目的工具和脚本 |
| storm-checkstyle | 代码风格检查的 Checkstyle 配置文件和规则 |
| storm-client | 与 Storm 集群通信的客户端 API |
| storm-clojure-test | 用于测试 Clojure 代码的测试工具和框架 |
| storm-clojure | Storm 中使用的 Clojure 代码 |
| storm-core | Storm 的核心功能和算法的实现代码 |
| storm-dist | 构建分发包的相关文件和配置 |
| storm-multilang | 与非JVM语言通信的多语言支持 |
| storm-server | 启动和管理 Storm 服务器的代码 |
| storm-shaded-deps | Storm 所需的各种第三方依赖的 shaded 版本 |
| storm-submit-tools | 提交和管理 Storm 拓扑的工具和脚本 |
| storm-webapp | Storm 的 Web UI 的代码和资源文件 |
4. Storm入门实例
说了那么多概念,我们来搞个代码来感受一下。我们假设有这样的一个场景,就比如CSDN的博文评价或者论坛帖子分析,核心场景是分析CSDN平台上用户对不同话题的情感倾向。
我们用java来实现.在控制台上,可以看到每个帖子及其情感倾向的输出结果。 这只是一个简单的情感分析示例,并且仅基于词语的出现与否进行判断。在实际应用中,情感分析通常会使用更复杂的算法和语言模型来进行更精确的情感判断。请大家不要上纲上线。
0.创建java工程并引入依赖
添加Storm的依赖。
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-core</artifactId>
<version>2.2.0</version>
</dependency>
1. 创建一个 Spout 类,用于生成随机的社交媒体帖子数据,并将其发送到拓扑中的下一个组件(Bolt):
public class SocialMediaSpout extends BaseRichSpout {
private SpoutOutputCollector collector;
@Override
public void open(Map<String, Object> conf, TopologyContext context, SpoutOutputCollector collector) {
this.collector = collector;
}
@Override
public void nextTuple() {
// 生成随机的社交媒体帖子数据
String post = generateRandomPost();
// 发送数据到下一个组件
collector.emit(new Values(post));
}
private String generateRandomPost() {
// 实现随机生成帖子的逻辑
// 返回生成的帖子内容
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("post"));
}
}
2. 创建一个 Bolt 类,用于处理帖子数据,并计算每个帖子的情感倾向:
public class SentimentAnalysisBolt extends BaseRichBolt {
private OutputCollector collector;
@Override
public void prepare(Map<String, Object> conf, TopologyContext context, OutputCollector collector) {
this.collector = collector;
}
@Override
public void execute(Tuple tuple) {
// 获取帖子数据
String post = tuple.getStringByField("post");
// 进行情感分析,计算情感倾向
double sentiment = analyzeSentiment(post);
// 发送情感倾向数据到下一个组件
collector.emit(new Values(post, sentiment));
// 确认处理成功
collector.ack(tuple);
}
private double analyzeSentiment(String post) {
// 实现情感分析的逻辑
// 返回计算得到的情感倾向值
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("post", "sentiment"));
}
}
3. 创建一个拓扑类,用于连接 Spout 和 Bolt,并设置拓扑的并发度:
public class SentimentAnalysisTopology {
public static void main(String[] args) throws Exception {
// 创建拓扑
TopologyBuilder builder = new TopologyBuilder();
// 设置 Spout 和 Bolt
builder.setSpout("socialMediaSpout", new SocialMediaSpout(), 2);
builder.setBolt("sentimentAnalysisBolt", new SentimentAnalysisBolt(), 4).shuffleGrouping("socialMediaSpout");
// 创建配置
Config config = new Config();
config.setDebug(true);
// 提交拓扑到 Storm 集群
StormSubmitter.submitTopology("sentiment-analysis-topology", config, builder.createTopology());
}
}
4.情感分析方法 analyzeSentiment
它接受一个字符串作为输入,并返回一个表示情感极性的整数值。具体实现如下:
首先定义了一个积极词汇数组和一个消极词汇数组,然后遍历输入文本中的每个单词。使用 Arrays.asList 方法将数组转换为 List,并使用 contains 方法检查单词是否在列表中。如果单词在积极词汇列表中,情感分数加1;如果单词在消极词汇列表中,情感分数减1。最后返回情感分数作为结果。
public class SentimentAnalyzer {
public static int analyzeSentiment(String text) {
String[] positiveWords = {
"开心", "真棒", "支持", "优秀", "好文", "厉害"};
String[] negativeWords = {
"三连", "互粉", "垃圾", "差" ,"废话"};
int sentimentScore = 0;
String[] words = text.split(" ");
for (String word : words) {
if (Arrays.asList(positiveWords).contains(word)) {
sentimentScore += 1;
} else if (Arrays.asList(negativeWords).contains(word)) {
sentimentScore -= 1;
}
}
return sentimentScore;
}
}
5. Apache Storm 与 Hadoop
Apache Storm 和 Hadoop 都是大数据处理领域的重要技术。但是,它们的设计目标和应用场景有所不同。Hadoop 是一个批处理系统,主要用于离线数据处理,例如批量的 MapReduce 任务和数据仓库。而 Storm 是一个实时计算系统,主要用于处理实时数据流,例如实时的流处理、实时的事件处理和实时的机器学习。
| Storm | Hadoop |
|---|---|
| 实时流处理 | 批量处理 |
| 无状态 | 有状态的 |
| 具有基于 ZooKeeper 协调的主/从架构。主节点称为nimbus和从节点称为supervisors. | 具有/不具有基于 ZooKeeper 的协调的主从架构。主节点是job tracker从节点是task tracker. |
| Storm 流式处理可以在集群上每秒访问数万条消息。 | Hadoop 分布式文件系统 (HDFS) 使用 MapReduce 框架来处理需要数分钟或数小时的大量数据。 |
| Storm Topology会一直运行,直到用户关闭或出现不可恢复的意外故障。 | MapReduce 作业按顺序执行并最终完成。 |
| 两者都是分布式和容错的 | |
| 如果 nimbus / supervisor 死了,重新启动会使其从停止的地方继续,因此不会受到任何影响。 | 如果 JobTracker 死了,所有正在运行的作业都将丢失。 |
6. Apache Storm 的用例
Apache Storm 可以用于处理各种实时数据流,包括社交媒体数据、物联网数据、金融数据、移动应用数据等。以下是一些常见的用例:
- 实时数据分析和决策:Storm 可以对海量实时数据进行分析和决策,例如实时交易监控、实时风控分析、实时广告投放等。
- 实时推荐和个性化服务:Storm 可以根据用户的实时行为和偏好,提供个性化的推荐和服务,例如实时新闻推荐、实时电影推荐等。
- 实时监控和预警:Storm 可以对实时数据流进行监控和预警,例如实时网络监控、实时系统监控等。
- 实时机器学习和模型训练:Storm 可以在实时数据流中更新机器学习模型和进行模型训练,例如实时预测和实时识别。
使用的公司
Twitter− Twitter 在其“发布者分析产品”系列中使用 Apache Storm。“发布者分析产品”处理 Twitter 平台中的每条推文和点击。Apache Storm 与 Twitter 基础架构深度集成。
NaviSite− NaviSite 正在将 Storm 用于事件日志监控/审计系统。系统中产生的每一条日志都会经过Storm。Storm 将根据配置的正则表达式集检查消息,如果匹配,则该特定消息将保存到数据库中。
Wego− Wego 是位于新加坡的旅游元搜索引擎。旅行相关数据来自世界各地不同时间的许多来源。Storm 帮助 Wego 搜索实时数据,解决并发问题并为最终用户找到最佳匹配。
来自网络
7. Apache Storm 的优点
Apache Storm 具有以下好处:
- 实时性:Storm 可以处理实时数据流,并实现毫秒级的响应时间。
- 可靠性:Storm 提供了可靠的消息传递机制和故障恢复机制,能够保证数据处理的高可靠性。
- 可扩展性:Storm 可以通过水平扩展来支持大规模的数据处理流程,能够便捷地扩展节点数和集群规模。
- 易用性:Storm 提供了易于使用的编程模型和丰富的 API,能够简化开发和部署的过程。
- 生态系统:Storm 有一个庞大的开源生态系统,支持各种数据源和数据处理工具的集成和扩展。
通俗的讲
- Storm 是开源的、强大的和用户友好的。它可以在小公司和大公司中使用。
- Storm 容错、灵活、可靠,并且支持任何编程语言。
- 允许实时流处理。
- Storm 的速度快得令人难以置信,因为它具有强大的数据处理能力。
- Storm 通过线性添加资源,即使在负载增加的情况下也能保持性能。它具有高度可扩展性。
- Storm 在几秒或几分钟内执行数据刷新和端到端交付响应,具体取决于问题。它的延迟非常低。
- Storm 拥有运营智能。
- 即使集群中的任何连接节点死亡或消息丢失,Storm 也提供有保证的数据处理。
8. 参考文档
- Apache Storm 官方文档:https://storm.apache.org/releases/2.4.0/index.html
- Storm 启动指南:https://storm.apache.org/releases/2.2.0/Running-topologies-on-a-production-cluster.html
- Storm Topology 设计指南:https://storm.apache.org/releases/2.2.0/Understanding-the-parallelism-of-a-Storm-topology.html
- Storm 插件和外部集成:https://storm.apache.org/releases/2.2.0/External-Integrations.html
- Storm API 文档:https://storm.apache.org/releases/2.2.0/javadocs/index.html
- Storm 教程和示例:https://storm.apache.org/releases/2.2.0/Tutorials.html
- Storm 与其他大数据工具的集成指南:https://storm.apache.org/releases/2.2.0/Third-party-integrations.html