研一上学期,云计算课程,老师希望我们能掌握基于 Spark、HDFS 和 MongoDB 的本地高效分布式数据处理和存储环境的搭建和技术使用。我们小组选的课题是豆瓣小组和用户数据。其中,我作为组长,负责编写 Spark Streaming 部分和聚类部分的代码。
时间很紧凑,一周内就要自学之前完全不熟悉的大数据处理领域,并且完成案例实现,这对于我来说是个不小的挑战。于是那一周我早起晚睡,日常窝在机房研究官方 Spark documentation,在写代码的过程中也遇到了许多坑,最终 I manage it! 不过当时没空写博客,现在寒假了,所以就把那时候我上台演示的课堂报告拿出来,其中记录了不少当时遇到的问题和一一破解的办法。在我课堂报告完,我的组员们偷偷瞟了一眼老师的计分表,发现是最高分,特别开心,努力没有白费。
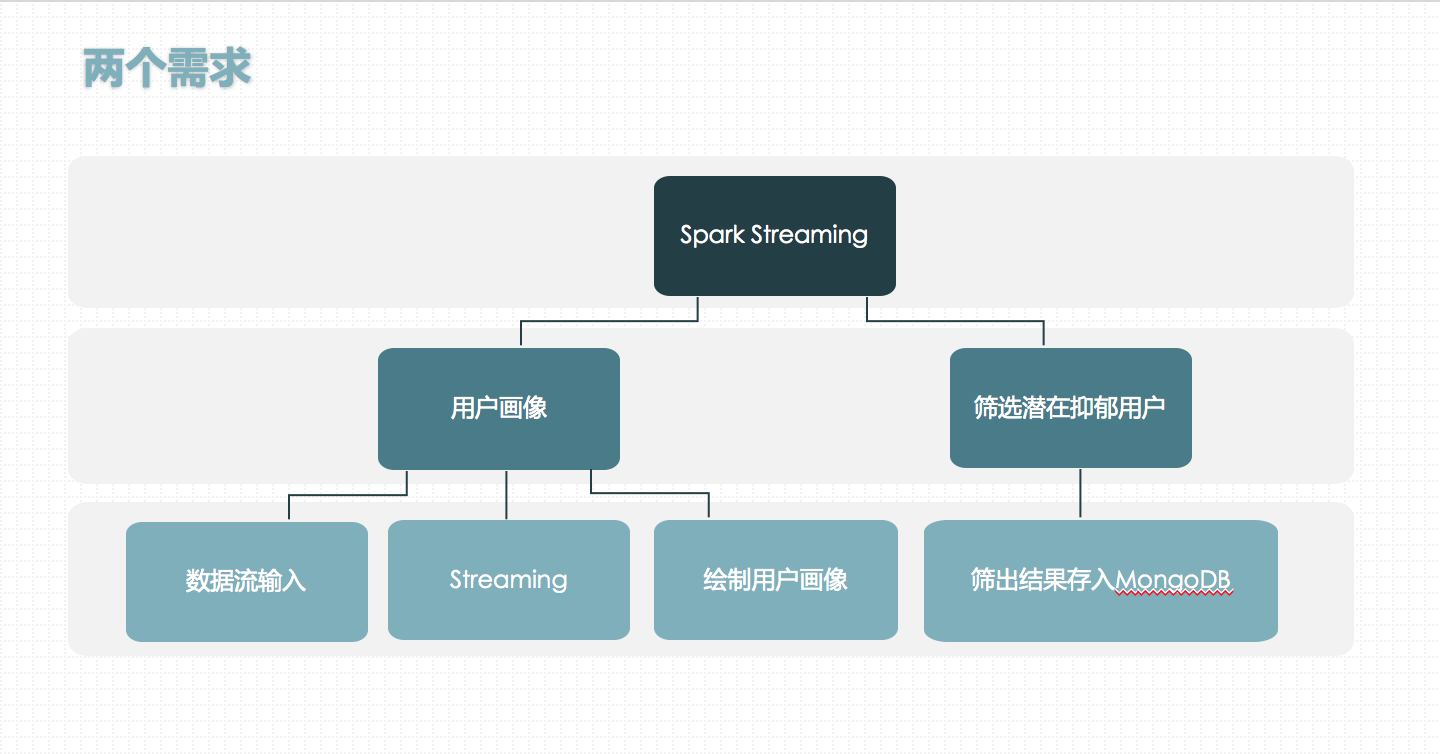
Spark streaming部分,老师的要求如下:
输入:每个时间戳的所有用户加入小组事件,按时间升序处理
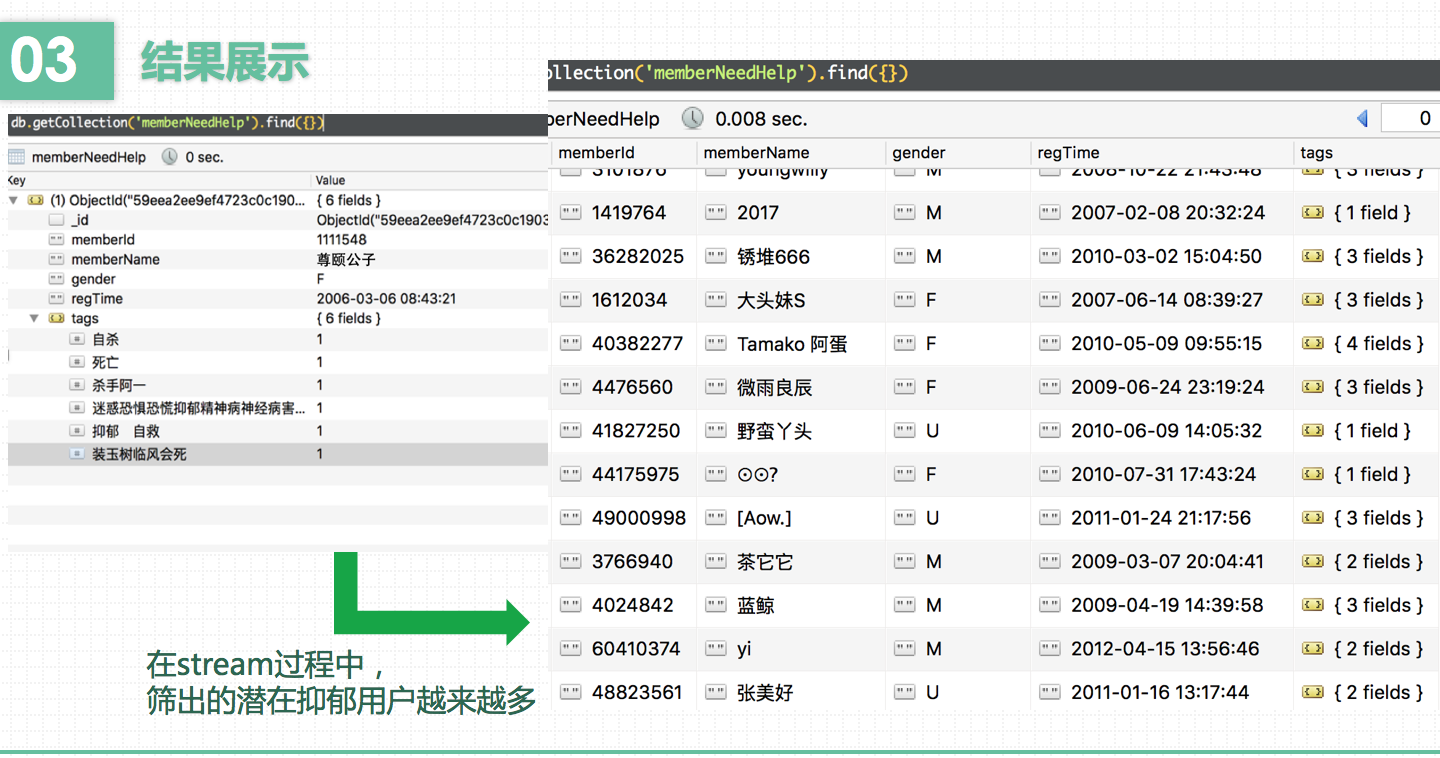
处理:对每个用户加入小组事件,更新用户画像,用户画像由一系列标签组成,标签可以直接用小组标签,比如说用户加入了第一个小组A,用户画像为小组A 的标签,然后用户加入了第二个小组,此时用户画像更新为小组A 的标签和小组B 的标签(实际的用户画像刻画挺复杂的,我们这里只是为了模拟一个流计算的场景),将用户结果展示:只要能展现出用户画像在不断变化即可,比如说可以在处理过程中给用户画像数据截个图,过一段事件后再截个图,可以看出用户画像有变化即可。
下面是我的课堂报告。




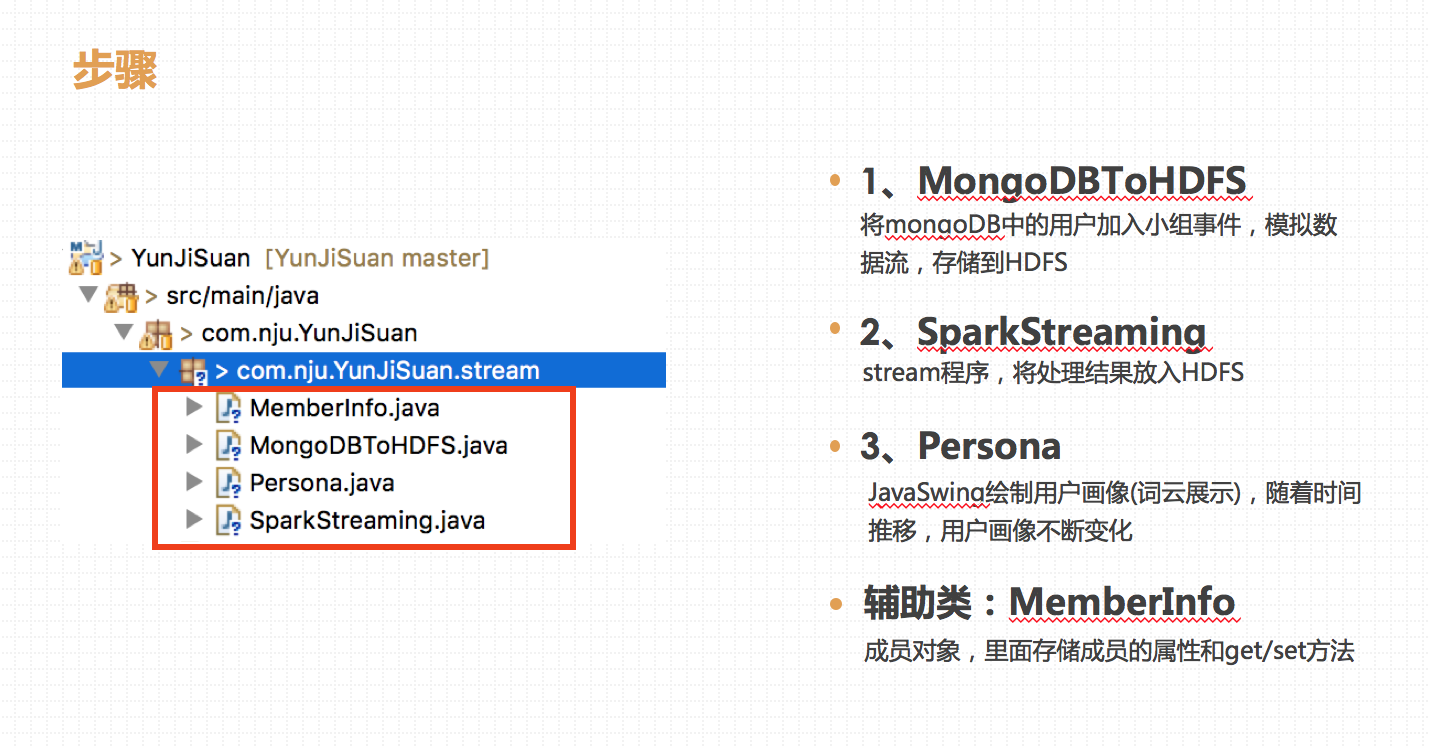
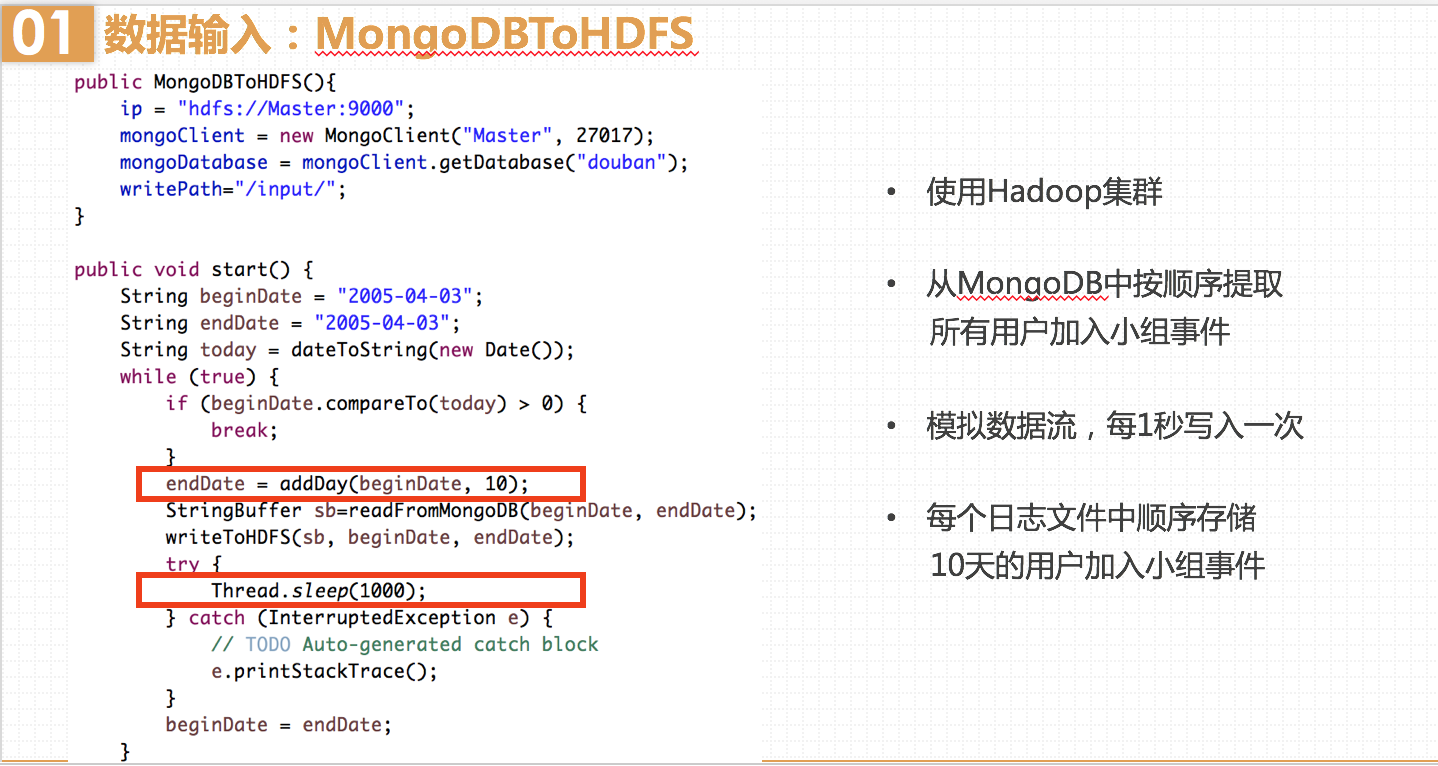
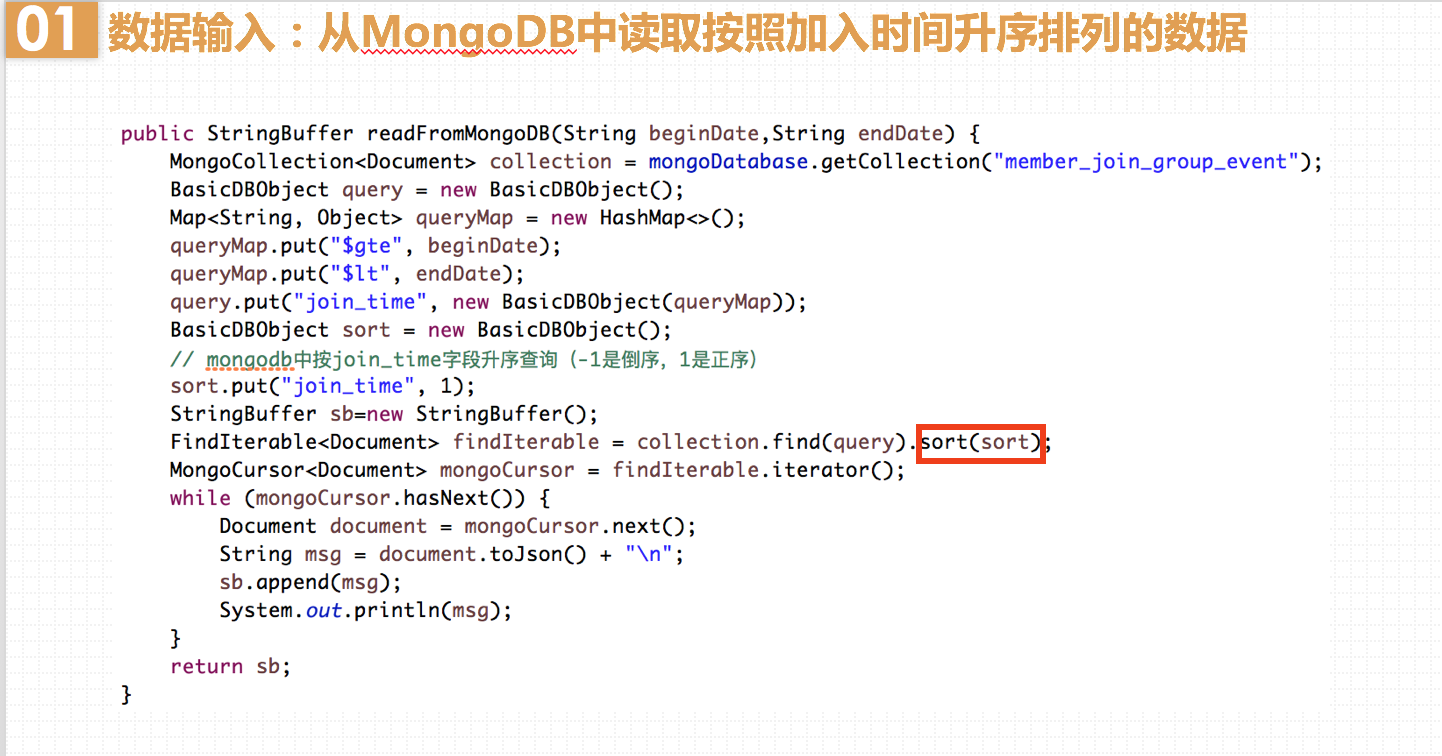
豆瓣网站是2005年4月3日成立的,所以我们的开始时间就选在2005年4月3日。
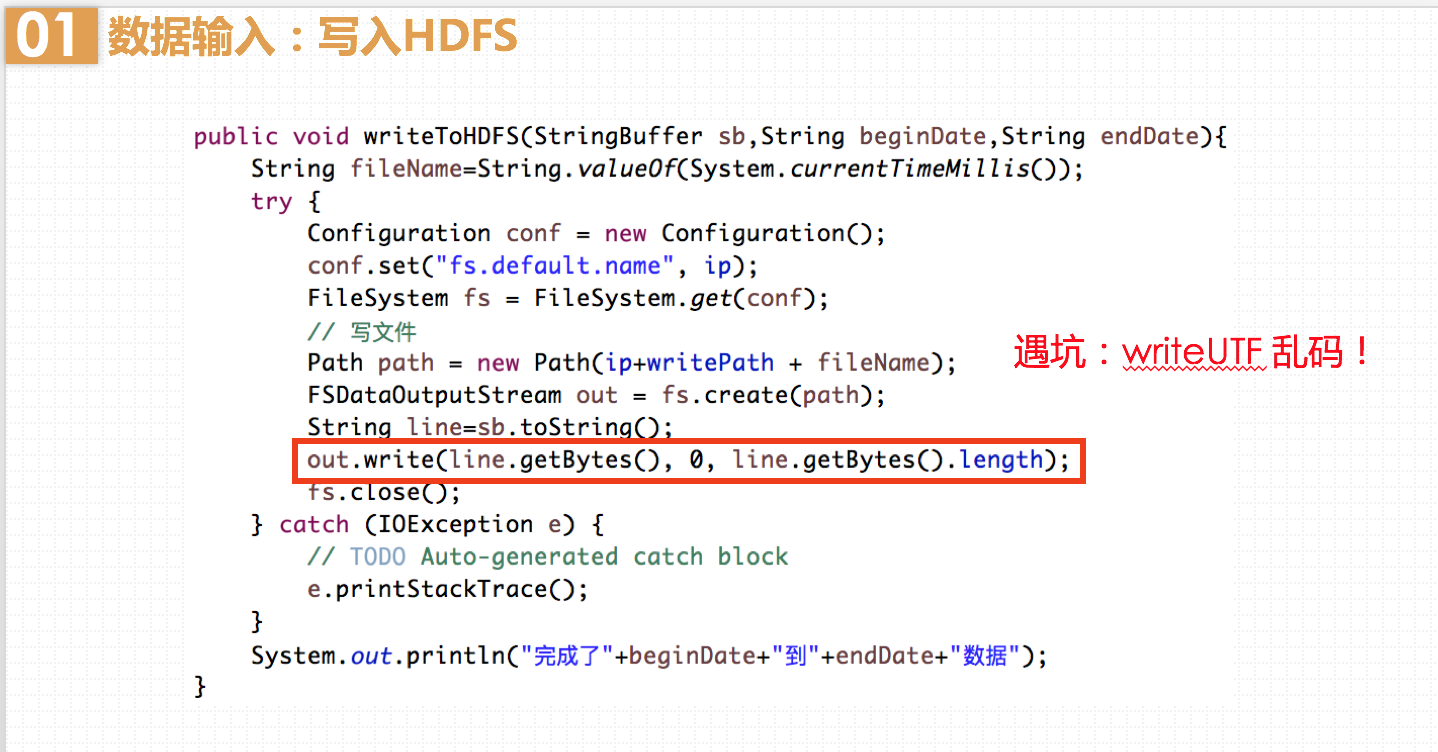
这里遇到了一个坑:我最初使用out.writeUTF()方法,发现写入的文件打开后是乱码。原来,StringBuffer最终生成的字符串中含有“\n”,而writeUTF()在写出一个UTF-8编码的字符串前面会加上2个字节的长度标识,以标识接下来的多少个字节是属于本次方法所写入的字节数。可是它写入时却无法识别换行符,因此会导致标识的字节数不正确,使得最终文件为乱码。知道问题所在后,我改为write()方法就好了,该方法可以自定义写入输出流的从哪个偏移位置开始 和写入的长度,因此不会出错。
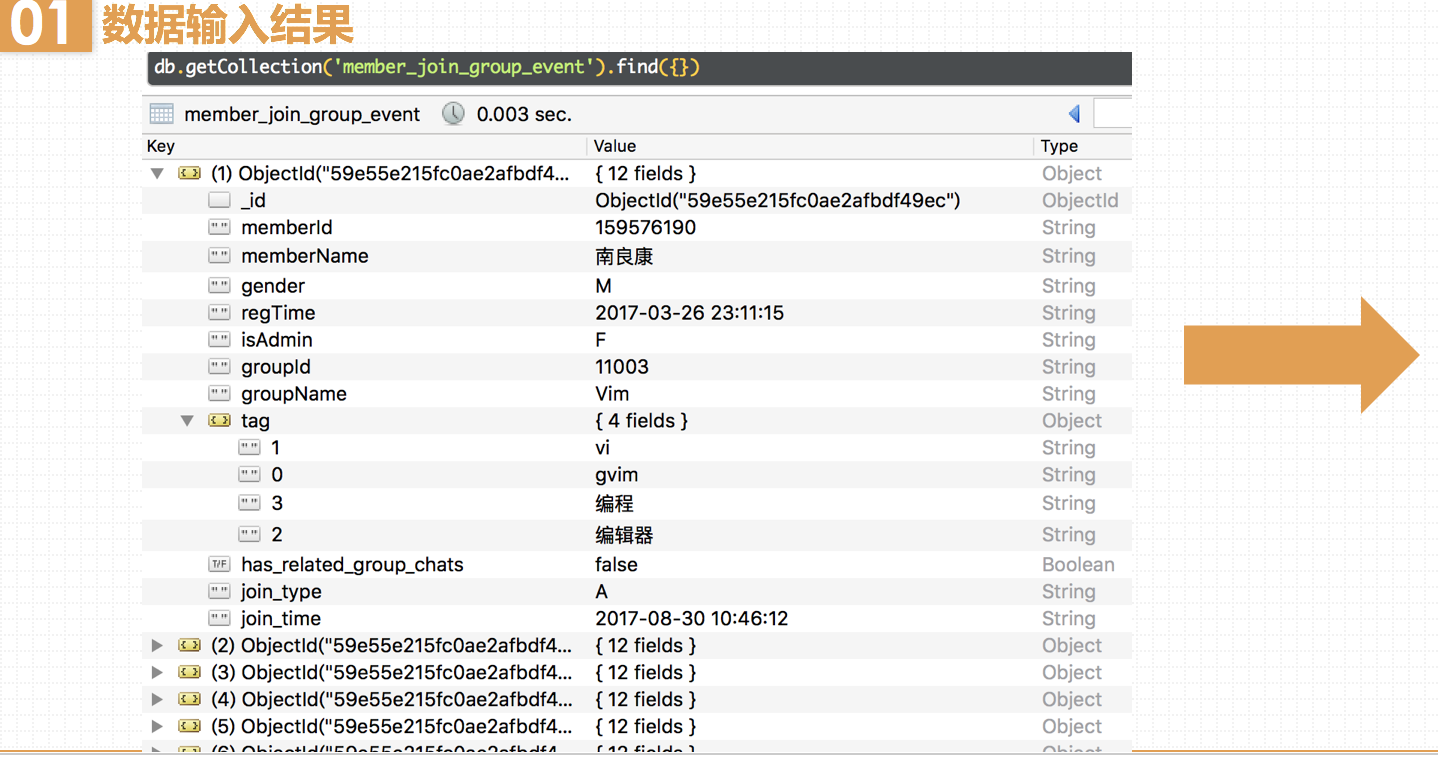
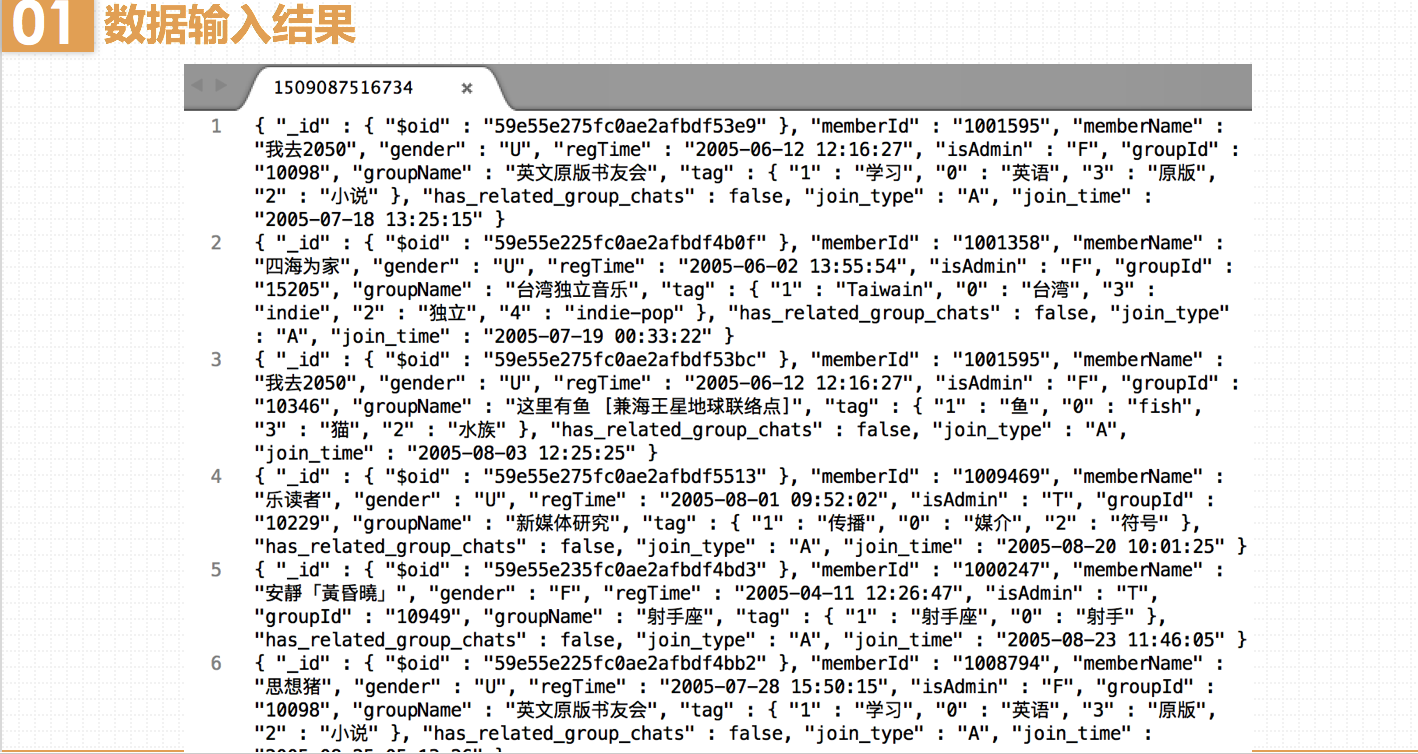

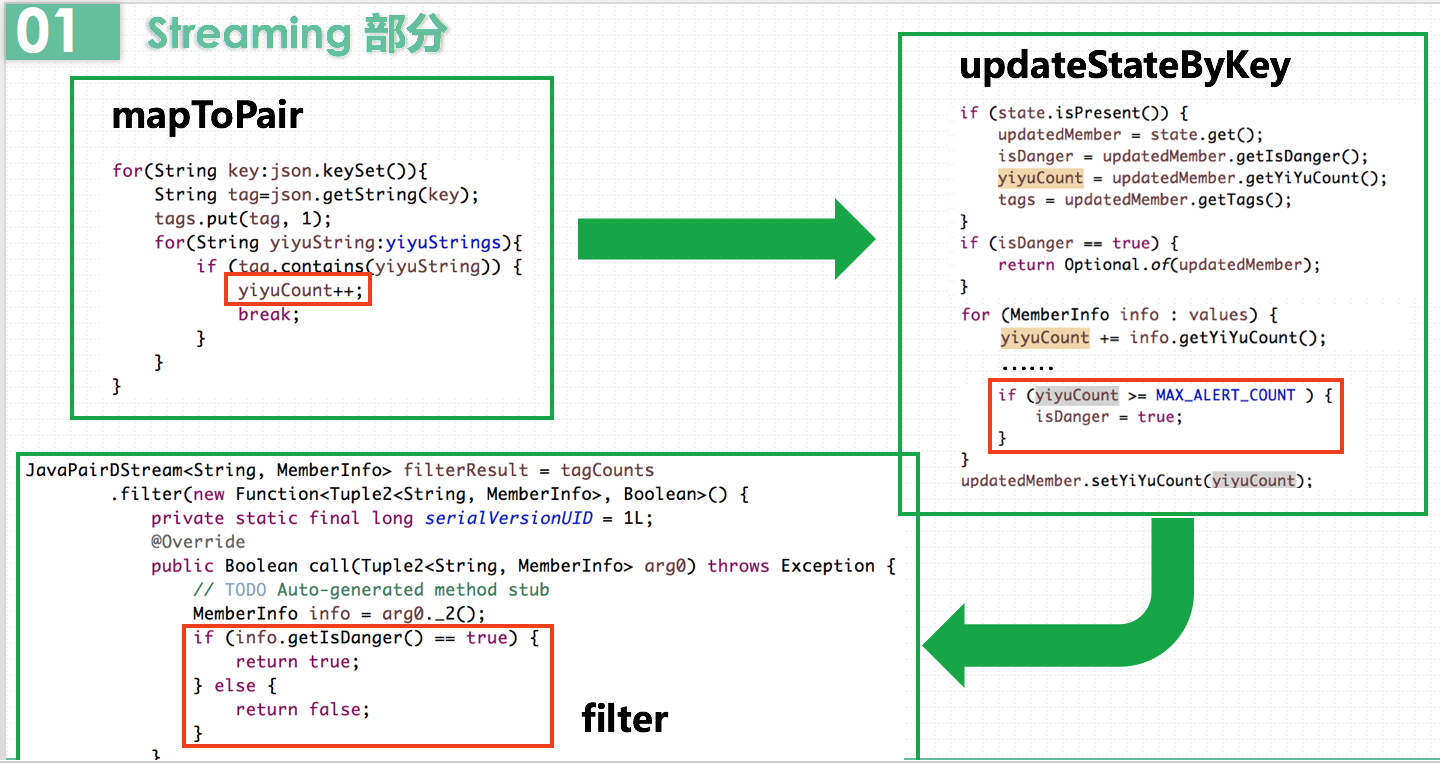
MemberInfo中有个成员属性tag,是map类型的,其中key存储该用户的标签,value存储该标签出现了多少次。
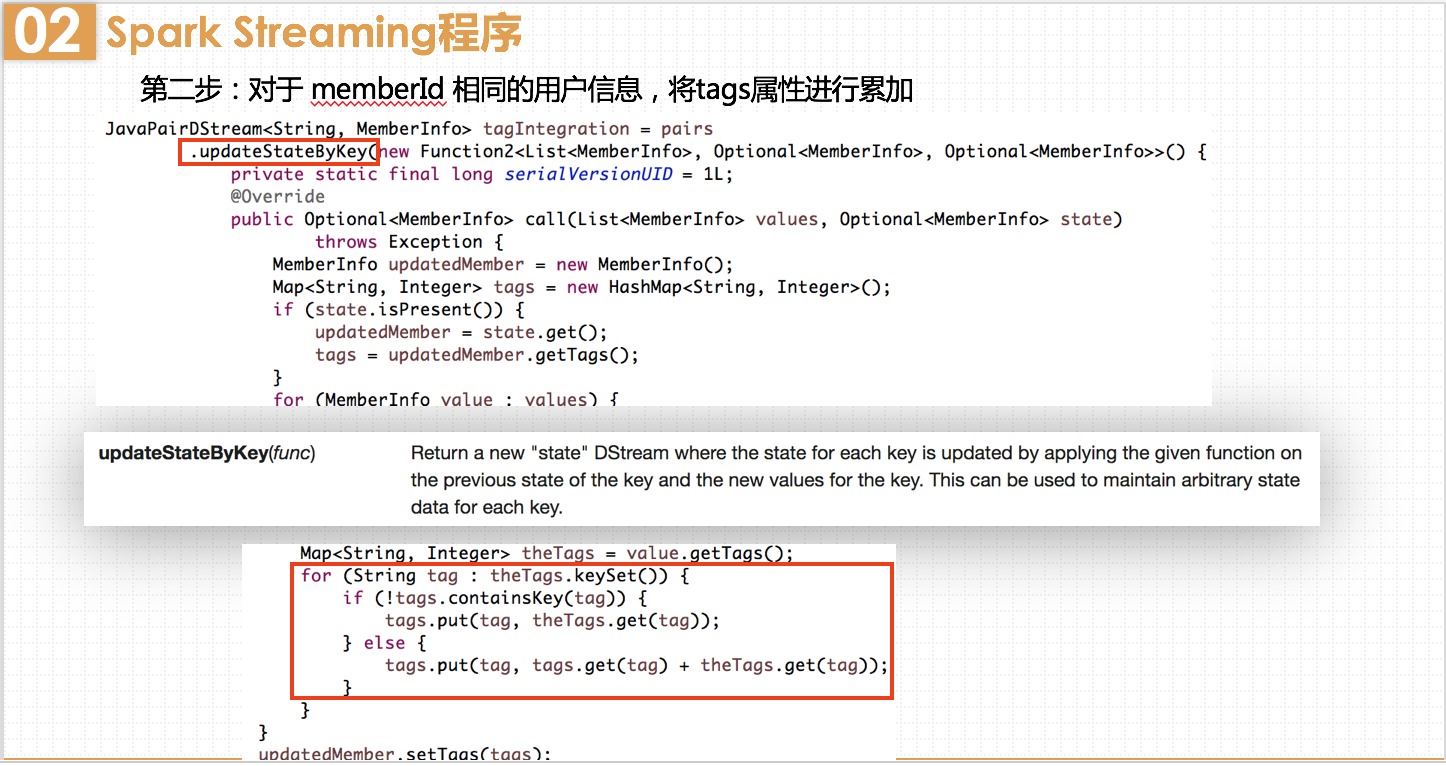
在这里使用updateStateByKey而不是reduceByKey,是因为reduceByKey无状态,仅仅对当前批次的DStream数据按key做reduce操作,不能顾及到之前批次的数据和之后的数据。而updateStateByKey则有状态,会不断的把当前和历史的时间切片的RDD累加计算。由于用户画像需要用户历史加入小组的所有标签,所以这里使用有状态的updateStateByKey。
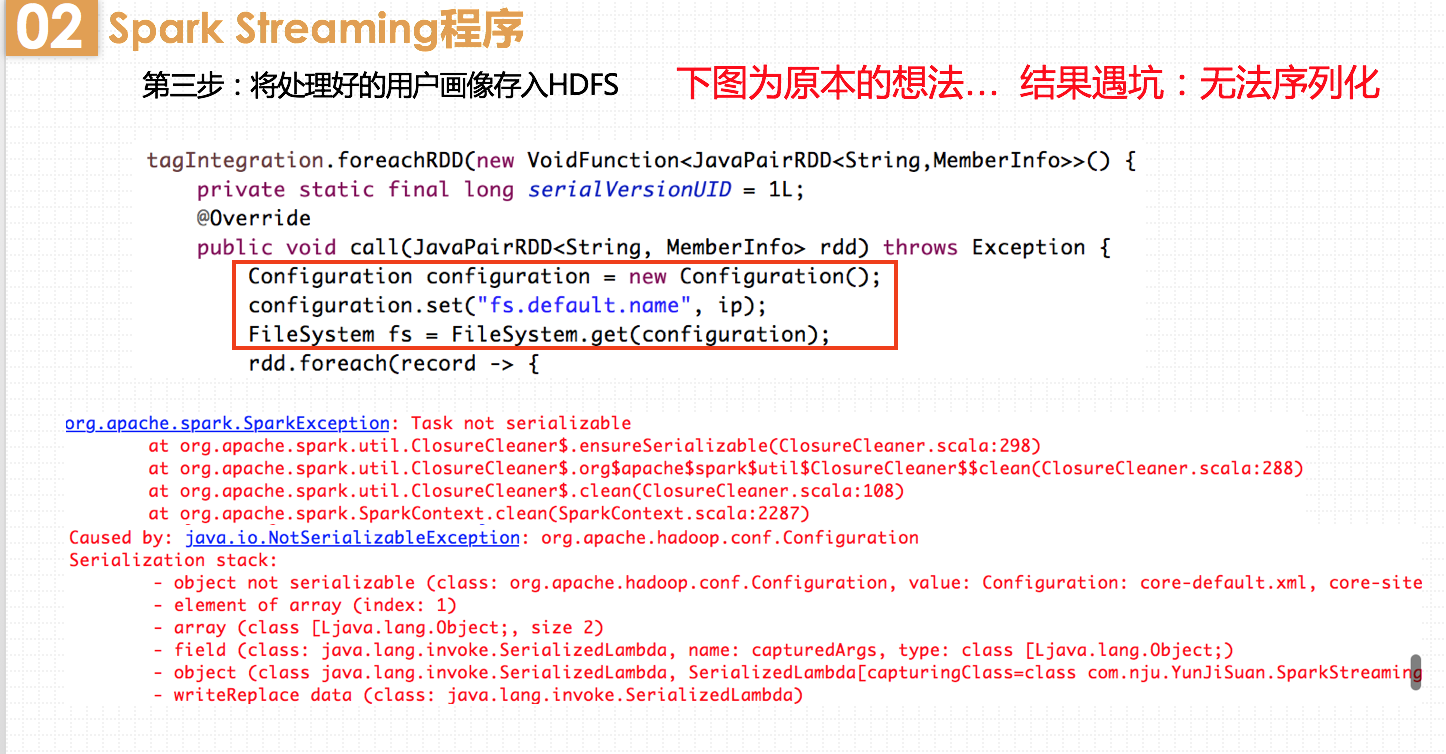
在这里我又遇到了一个坑。考虑到连接HDFS比较耗时,我一开始想把连接操作直接放在call方法的一开头,这样每一个record都能共享该连接。但是会报错无法序列化。因为这里需要先序列化连接对象,然后将它从driver发送到worker中。而Configuration无法序列化,不能在机器之间传送。正确的解决办法是在worker中创建连接对象。但是问题又来了,总不能为每个record都创建一个连接对象,会有很大的资源和时间的开销。
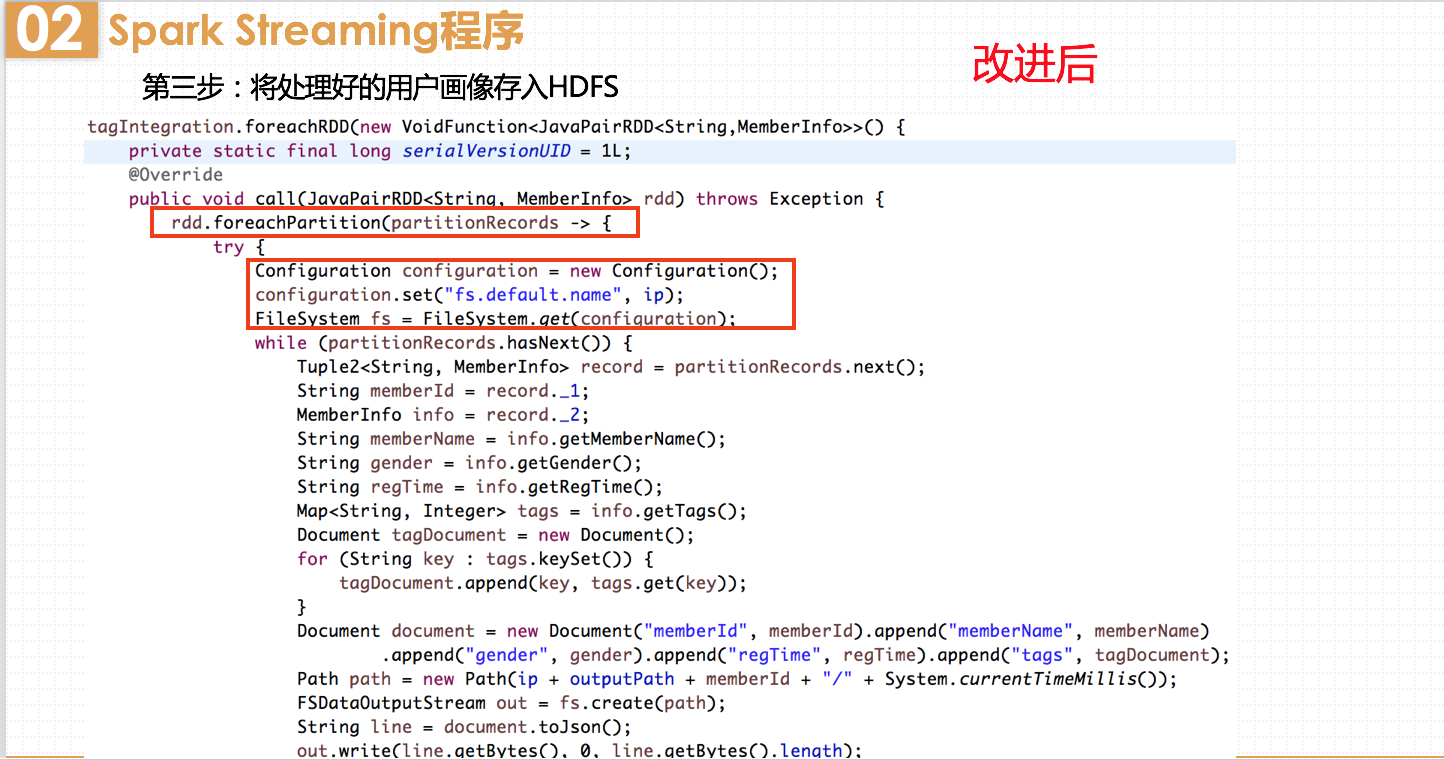
因此我这里采用了foreachPartition方法,为RDD的partition创建一个连接对象,用这个对象处理partition中的所有记录。
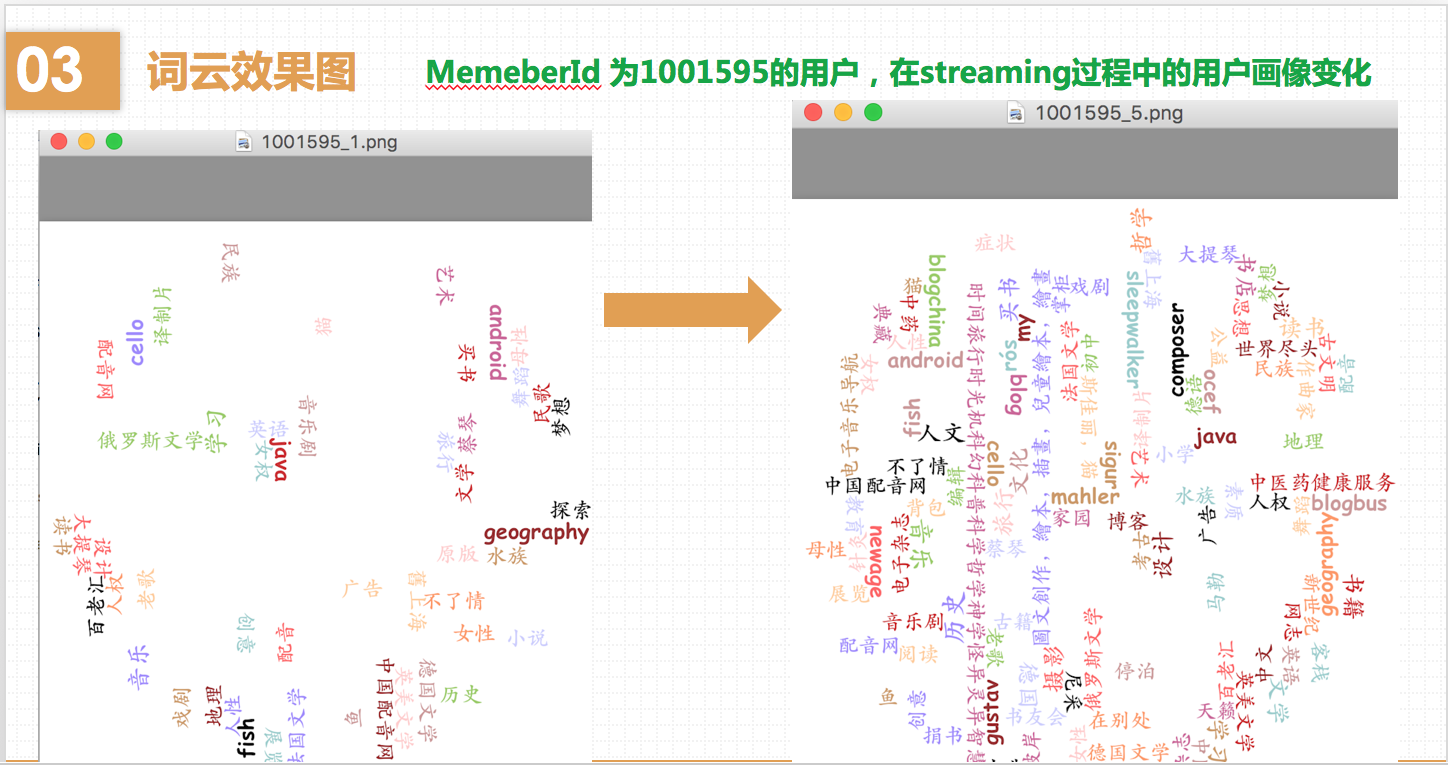
当某个标签出现频率比较多时,这个标签的字体也会变大。我这个例子的用户可能参加的小组标签比较均衡,不怎么能看出字体的不一样。
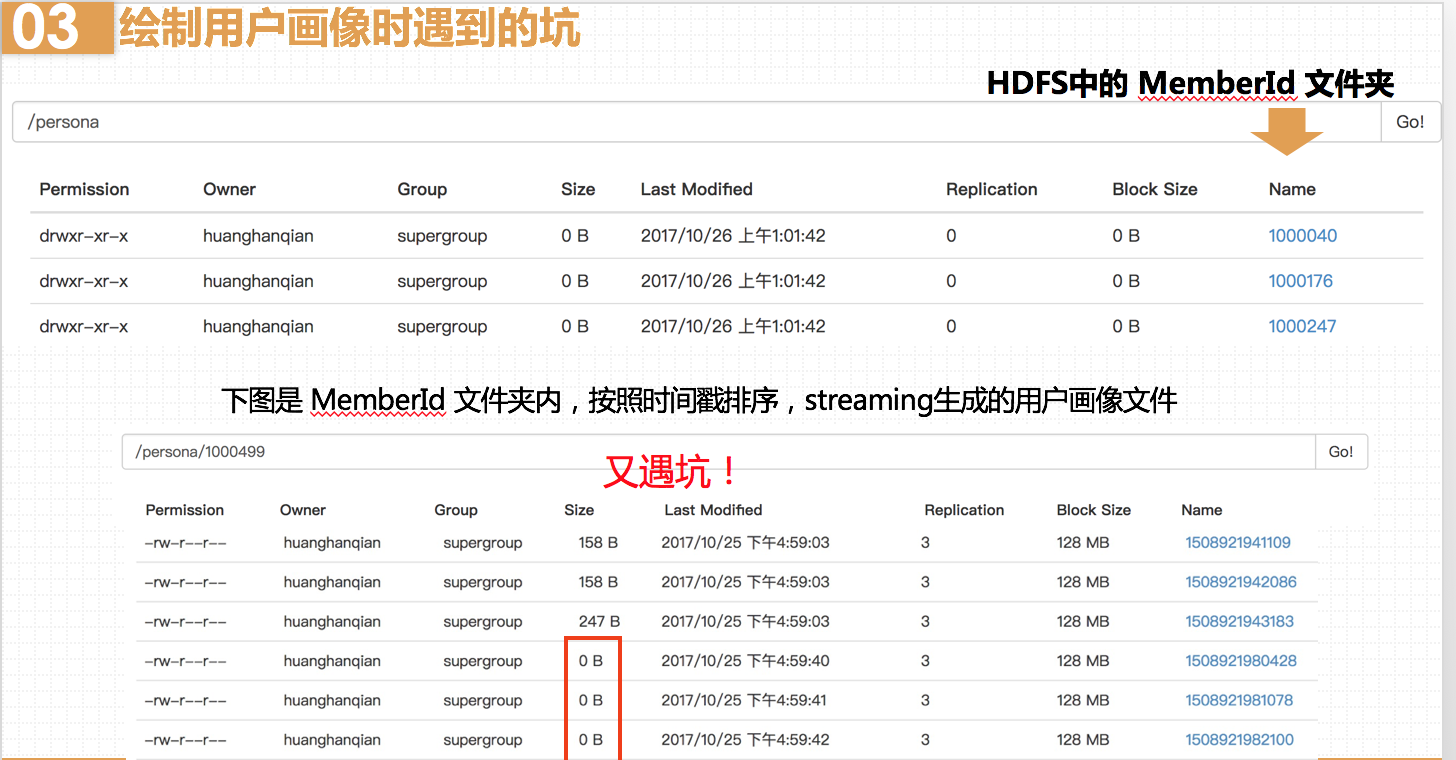
在stream过程中,随着时间推移,同一个用户的用户画像文件会越来越多。而我绘制当前时间点的用户画像,只需要取该用户文件夹下最新时间戳的文件进行绘制。我的做法是获取该文件夹下的所有文件,得到一个文件数组,该数组的最后一个元素就是最新文件。然而发现,HDFS写入时,是先创建文件,此时文件的size为0B,再过一段时间才写入。这样就导致我获取的最新文件为空,产生报错。
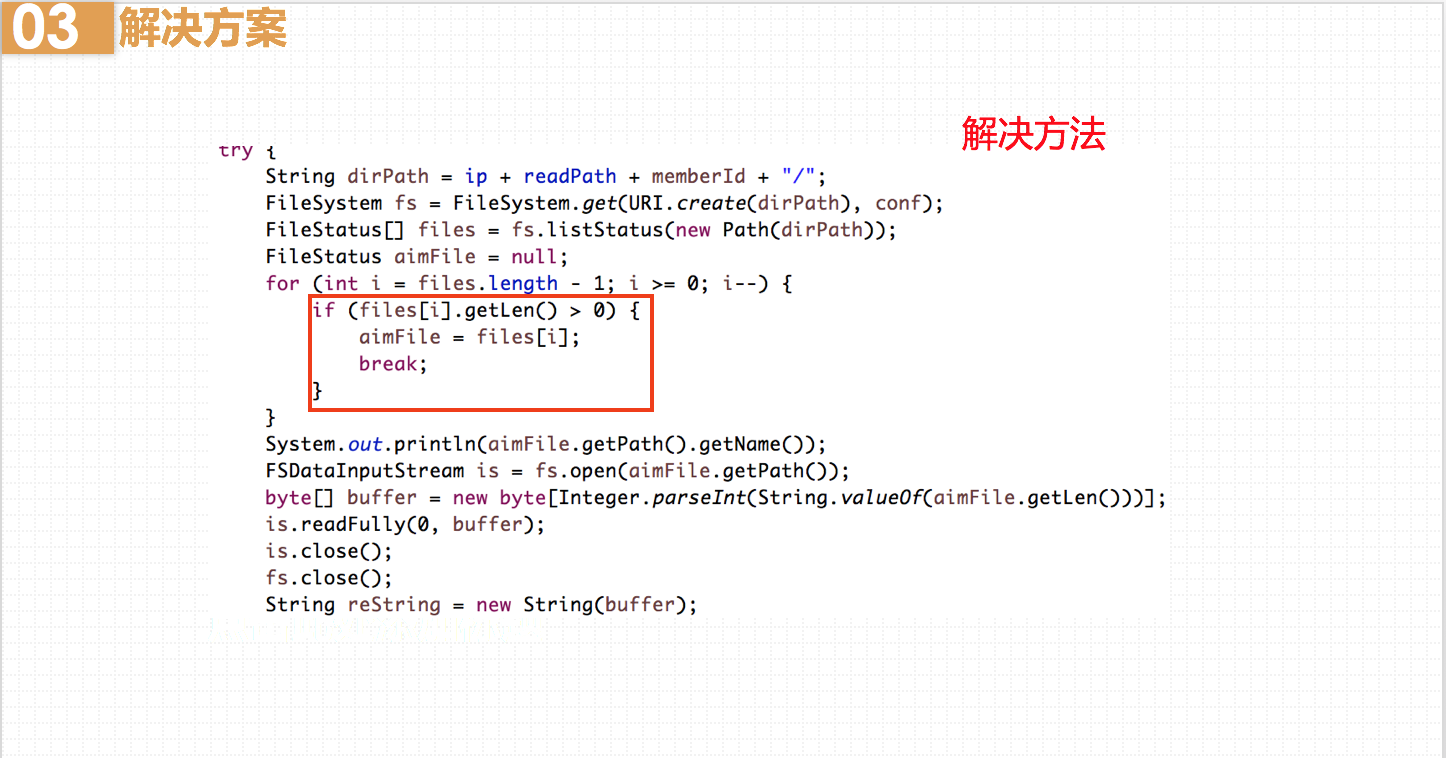
解决方案就是从文件大小入手,获取数组中最后一个FileStatus.getLen()不为0的文件,就是当前已写入完全的最新文件。



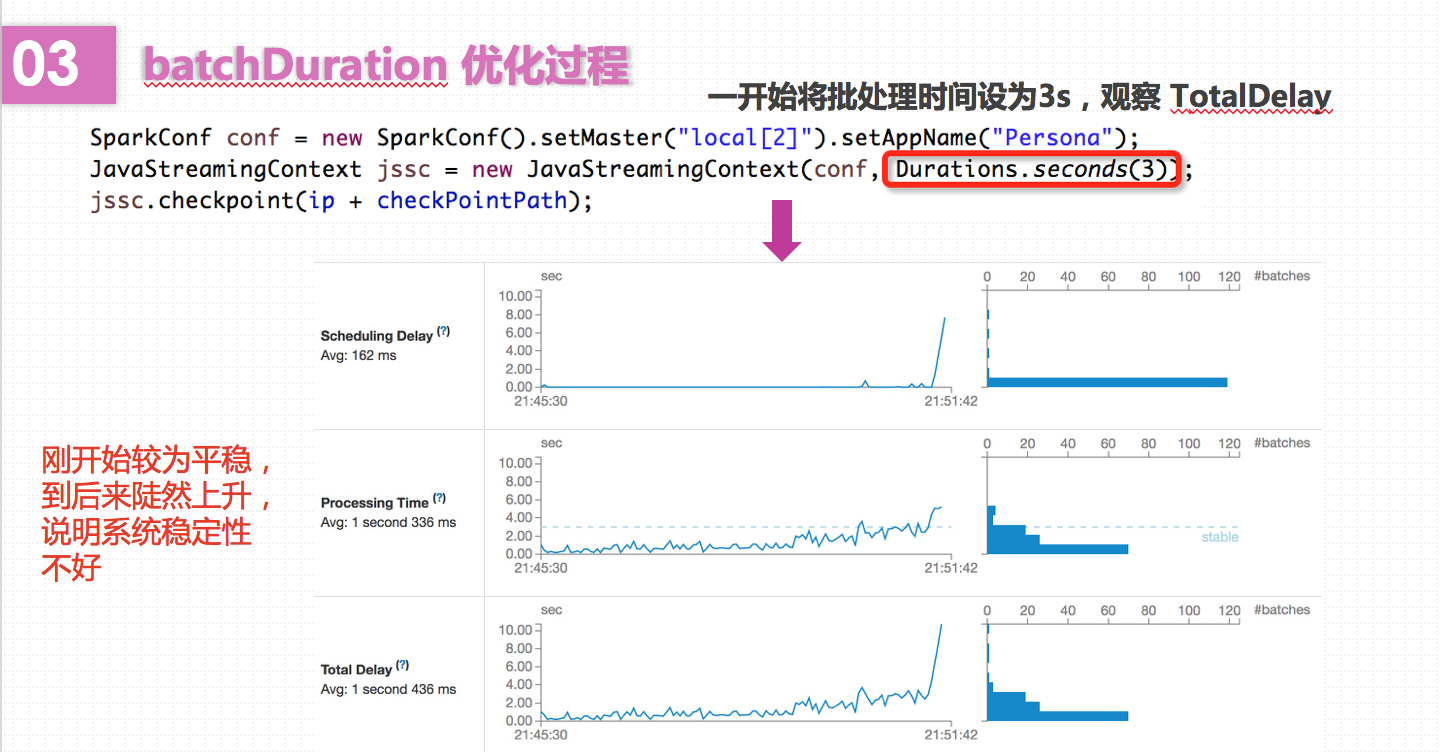
Spark会每隔batchDuration时间去提交一次Job。如果这个值设置的过短,使得Job并不能在这期间完成处理,那么就会造成数据不断堆积,最终导致Spark Streaming发生阻塞。而且,一般对于batchDuration的设置不会小于500ms,因为过小会导致SparkStreaming频繁的提交作业,对整个streaming造成额外的负担。在这里,我根据SparkStreaming的可视化监控界面,观察Total Delay来进行batchDuration的调整。

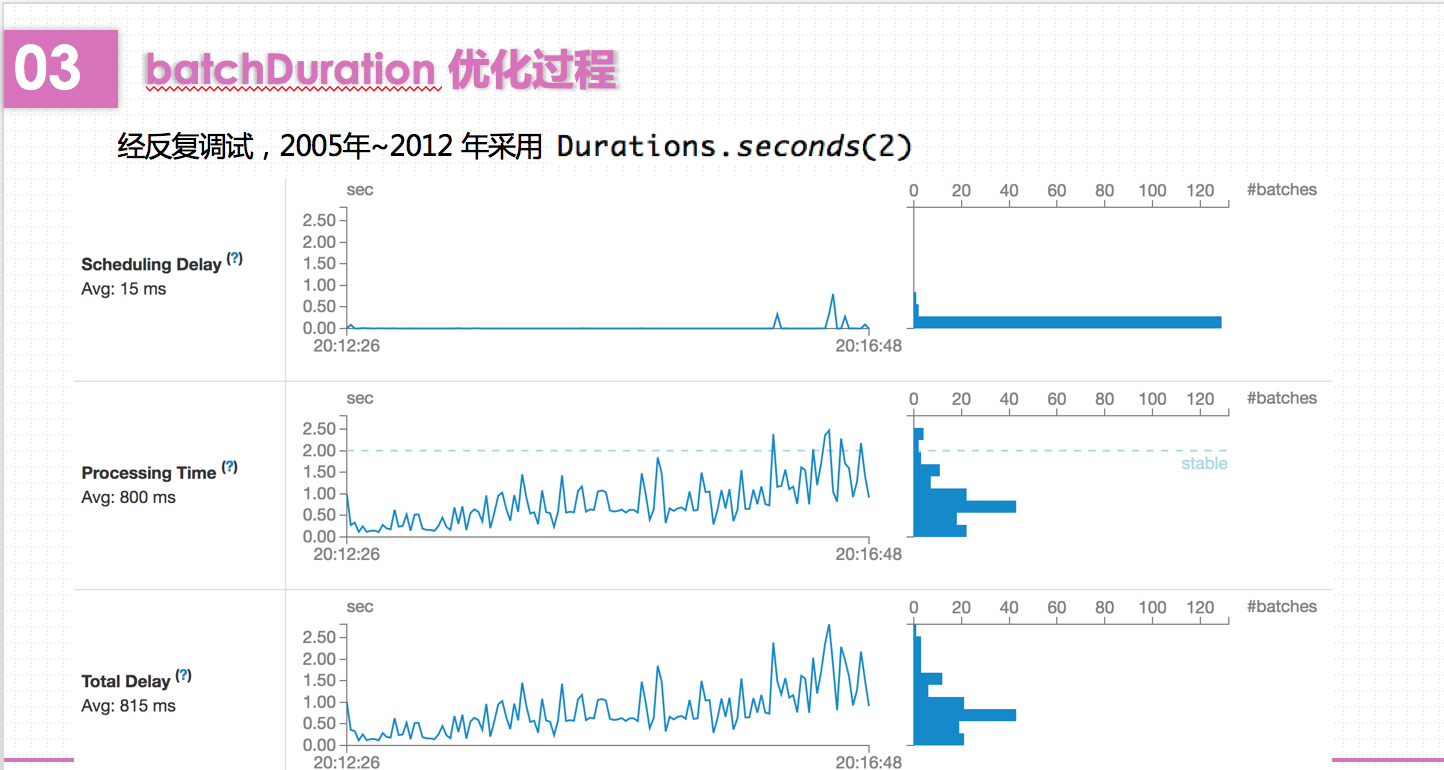
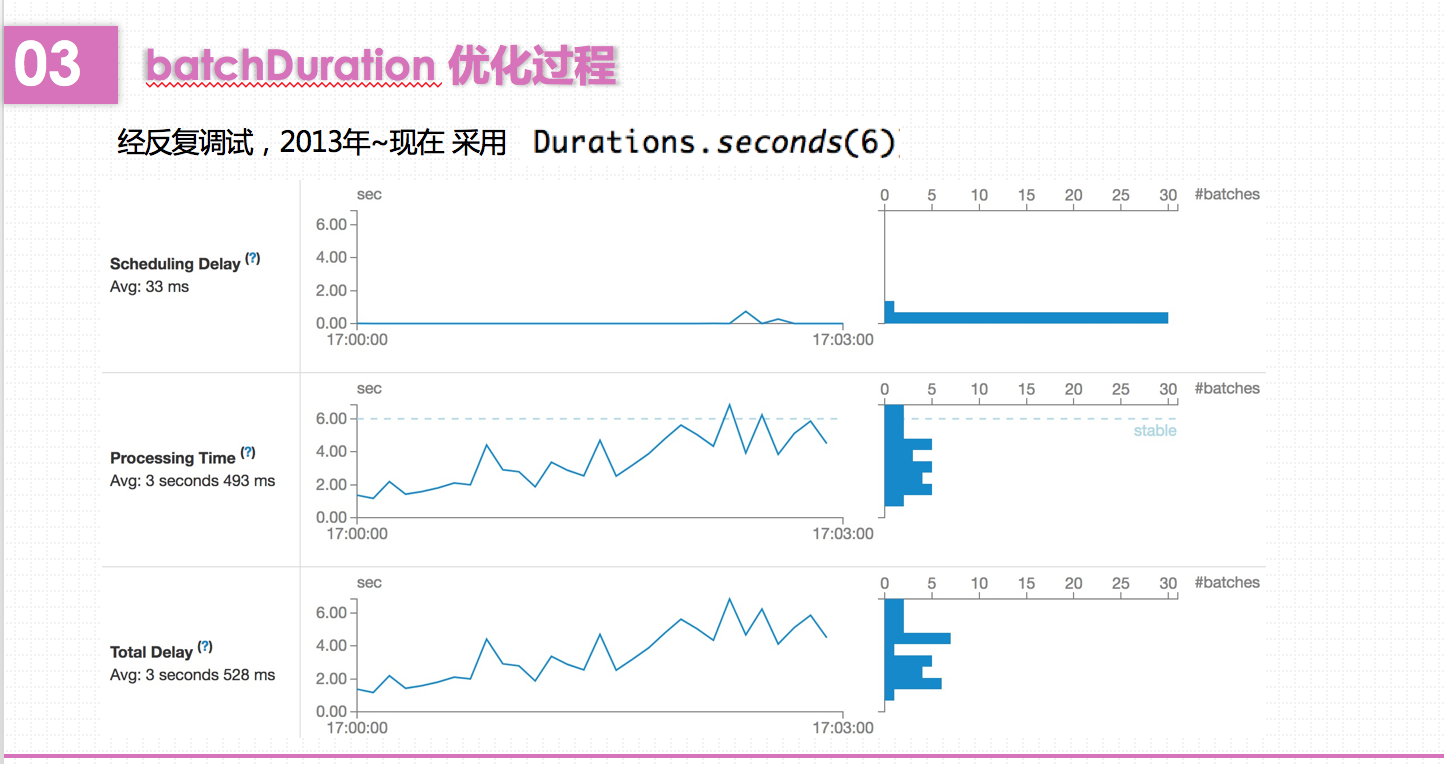

课堂报告就到此结束啦。