Tensorflow2实现手写数字识别
0. MNIST数据集介绍
MNIST 数据集来自美国国家标准与技术研究所, National Institute of Standards and Technology (NIST). 训练集 (training set) 由来自 250 个不同人手写的数字构成, 其中 50% 是高中学生, 50% 来自人口普查局 (the Census Bureau) 的工作人员. 测试集(test set) 也是同样比例的手写数字数据.
MNIST 数据集可在MNIST获取, 它包含了四个部分:
- Training set images: train-images-idx3-ubyte.gz
(解压后 47 MB, 包含 60,000 个样本) - Training set labels: train-labels-idx1-ubyte.gz
(解压后 60 KB, 包含 60,000 个标签) - Test set images: t10k-images-idx3-ubyte.gz
( 解压后 7.8 MB, 包含 10,000 个样本) - Test set labels: t10k-labels-idx1-ubyte.gz
(解压后 10 KB, 包含 10,000 个标签)
这里Training set 和Test set 中的图片是28×28的灰度图,每个像素为[0, 255]中的一个数值。
而labels标签集中的值为[0, 9]中的一个数值,其标记了对应位置图片的手写数字。
例: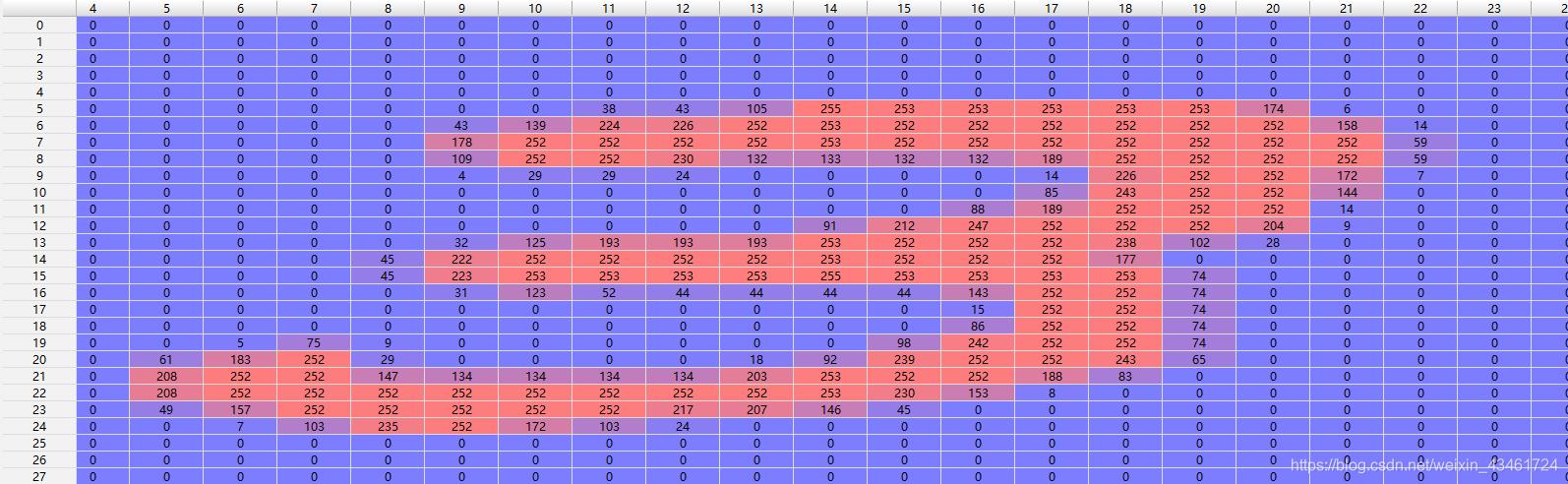
1. 代码细节
import tensorflow as tf
引入tensorflow模块 以tf为别名
batch_size = 128
le_r = 0.2
定义一个batch的大小和学习率大小
mnist = tf.keras.datasets.mnist
(ti, tl), (vi, vl) = mnist.load_data()
print('datasets:', ti.shape, tl.shape, vi.shape, vl.shape)
利用tensorflow内置函数导入MNIST数据集
并输出一下数据的维度:
datasets: (60000, 28, 28) (60000,)
(10000, 28, 28) (10000,)
def fun(a, b):
a = tf.cast(a, dtype=tf.float32)
b = tf.cast(b, dtype=tf.int64)
return tf.reshape(a, [-1, 28*28])/255.0, tf.one_hot(b, depth=10)
ti, tl = fun(ti, tl)
vi, _ = fun(vi, vl)
由于vi和ti的维度是[-1, 28, 28],我们希望把每个[28, 28]的样本铺平成[784]以便于输入网络,于是这里定义了一个名为fun的函数,分别对ti, tl 和vi进行数据预处 理(不需要处理vl)。 对输入做了简单的归一化处理,即除以255.0(数据中最大值-最小值)。并对标签做了one-hot编码处理。
预处理完后ti和vi的维度分别为[60000, 784]和[10000, 784] 。
例:
归一化后
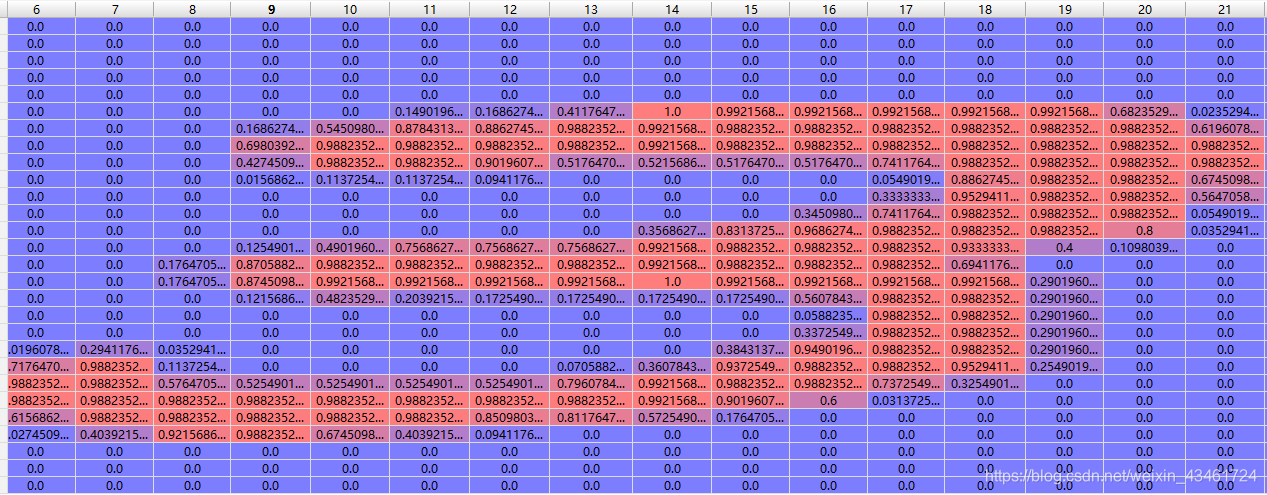
其对应的标签3会被拓展成[0, 0, 0, 1, 0, 0, 0, 0, 0]
关于数据预处理拓展:
d1 = tf.data.Dataset.from_tensor_slices((ti, tl)) # ti tl 自动转换为tensor
d1 = d1.shuffle(10000).batch(batch_size)
调用tf.data.Dataset.from_tensor_slices()函数构造(ti, tl)的切片:shuffle()可以对数据进行乱序处理 .batch(batch_size)可以把数据划分成若干个batch_size大小的数据组并返回一个可迭代对象,用于遍历各个数据组。
w1 = tf.random.normal([784, 512])
b1 = tf.zeros([512], dtype=tf.float32)
w2 = tf.random.normal([512, 10])
b2 = tf.zeros([10], dtype=tf.float32)
构造第一层及第二层的权重矩阵w及其偏置b,将b初始化为0矩阵;将w按正态分布初始化。
这里由于输入的ti维度已经被处理为了[-1, 784],】’所以我们输入为784个节点,取中间隐藏层为512个节点,由于是10分类问题,输出取10个节点,代表数字0~9,节点输出越大表示为该数字的可能性越大。
关于权重初始化拓展:
之后是迭代数据集进行梯度下降优化并定周期输出网络在验证集上的准确率。
for epoch in range(10):
print('the {0} epoch began'.format(epoch))
d2 = iter(d1)
for steps, (x, y) in enumerate(d2):
with tf.GradientTape() as tape:
tape.watch([w1, b1, w2, b2]) # 可以去掉tf.variable()包装
h1 = x@w1 + b1
a1 = tf.nn.sigmoid(h1)
out1 = a1 @ w2 + b2
loss = tf.reduce_mean(tf.losses.categorical_crossentropy(y, out1, from_logits=True))
if steps % 100 == 0:
print(steps, 'finished')
grads = tape.gradient(loss, [w1, b1, w2, b2])
w1 = w1 - le_r*grads[0]
b1 = b1 - le_r*grads[1]
w2 = w2 - le_r*grads[2]
b2 = b2 - le_r*grads[3]
c1 = tf.nn.sigmoid(vi @ w1 + b1)
c2 = tf.nn.softmax(c1 @ w2 + b2, axis=1)
out2 = tf.cast(tf.argmax(c2, axis=1), dtype=tf.int64)
acc = tf.reduce_sum(tf.cast(tf.equal(out2, vl), tf.float32))/vl.shape[0]
print('the {0} epoch finished and the acc ={1}'.format(epoch+1, acc))
分开来看:
for epoch in range(10):
print('the {0} epoch began'.format(epoch))
d2 = iter(d1)
for steps, (x, y) in enumerate(d2):
首先是一共跑10个epoch即10次大循环,每一次大循环先把d2初始为d1的迭代器,然后再通过for循环迭代一遍d1,x, y除最后一个外的维度分别为[128, 784],[128, 10]。
with tf.GradientTape() as tape:
tape.watch([w1, b1, w2, b2]) # 可以去掉tf.variable()包装
h1 = x@w1 + b1
a1 = tf.nn.sigmoid(h1) # [TensorShape([128, 500])
out1 = a1 @ w2 + b2
loss = tf.reduce_mean(tf.losses.categorical_crossentropy(y, out1, from_logits=True))
@表示矩阵相乘
这里借助了tensorflow强大的自动微分,tape.watch([w1, b1, w2, b2])表示记录w1, b1, w2, b2的梯度信息,如此就不用再为w1, b1, w2, b2包装一层tf.Variable()了。
a1为h2经过sigmoid()激活函数处理后的最终的隐藏层的输出。
最后定义一下损失函数,这个函数数值的大小刻画了我们最终输出的[-1, 10]的输出与标签[-1, 10]之间的偏离程度。这里可以用均方差不过效果好一点还是使用交叉熵函数作为损失函数。交叉熵函数可以比较准确地反应两个概率分布之间的差距。
这里因为我们没有对out输出做softmax处理使之符合概率分布的特征(相加为1)所以将from_logits置为True,这样会返回调用softmax_cross_entropy_with_logits_v2()在函数内帮我们进行softmax处理。
这里是tensorflow自动求导的一个示范,还可以通过嵌套求2阶导。
With tf.GradientTape() as tape:
Build computation graph
loss=fθ(x)
[w_grad] = tape.gradient(loss,[w])
if steps % 100 == 0:
print(steps, 'finished')
grads = tape.gradient(loss, [w1, b1, w2, b2])
w1 = w1 - le_r*grads[0]
b1 = b1 - le_r*grads[1]
w2 = w2 - le_r*grads[2]
b2 = b2 - le_r*grads[3]
grads = tape.gradient(loss, [w1, b1, w2, b2])取出w1, b1, w2, b2对loss(损失函数)的偏导数矩阵(grads = [dw1, db1, dw2, db2])
4、5、6、7行 向梯度减小的方向更新参数
每跑完100个batch(进行100次梯度下降)便输出一次完成信息
c1 = tf.nn.sigmoid(vi @ w1 + b1)
c2 = tf.nn.softmax(c1 @ w2 + b2, axis=1)
out2 = tf.cast(tf.argmax(c2, axis=1), dtype=tf.int64)
acc = tf.reduce_sum(tf.cast(tf.equal(out2, vl), tf.float32))/vl.shape[0]
print('the {0} epoch finished and the acc ={1}'.format(epoch+1, acc))
此时完成了1个epoch, c1, c2为验证集的前向传播过程。此时c2维度为[10000, 10],即每一行为一个验证集样本图片经过网络处理的输出,这里不需要把他进行softmax处理,我们只需要取出10个节点中输出值最大的节点的下标就可以知道这一个样本图片的预测值为多少了。
这里用tf.argmax()函数,可以取出每一行中最大的元素的下标。处理后的out2维度为[10000, ]也就是分别对应着10000个验证集图片的预测值。
然后把out2与vl标签集进行比较,并把真假值转换为1或0后求和即为预测正确的图片数,之后再除以vl.shape[0]也就是10000,就可以得到预测的准确率了。

运行一下可以看到这个网络预测手写数字的准确率大概在91%左右,如果使用卷积网络可以取得更好的准确率。
2. 代码总览
import tensorflow as tf
batch_size = 128
le_r = 0.2
def fun(a, b):
a = tf.cast(a, dtype=tf.float32)
b = tf.cast(b, dtype=tf.int64)
return tf.reshape(a, [-1, 28*28])/255.0, tf.one_hot(b, depth=10)
mnist = tf.keras.datasets.mnist
(ti, tl), (vi, vl) = mnist.load_data()
print('datasets:', ti.shape, tl.shape, vi.shape, vl.shape)
ti, tl = fun(ti, tl)
vi, _ = fun(vi, vl)
d1 = tf.data.Dataset.from_tensor_slices((ti, tl)) # ti tl 自动转换为tensor
d1 = d1.shuffle(10000).batch(batch_size)
w1 = tf.random.normal([784, 512])
b1 = tf.zeros([512], dtype=tf.float32)
w2 = tf.random.normal([512, 10])
b2 = tf.zeros([10], dtype=tf.float32)
for epoch in range(10):
print('the {0} epoch began'.format(epoch))
d2 = iter(d1)
for steps, (x, y) in enumerate(d2):
with tf.GradientTape() as tape:
tape.watch([w1, b1, w2, b2]) # 可以去掉tf.variable()包装
h1 = x@w1 + b1
a1 = tf.nn.sigmoid(h1)
out1 = a1 @ w2 + b2
loss = tf.reduce_mean(tf.losses.categorical_crossentropy(y, out1, from_logits=True))
if steps % 100 == 0:
print(steps, 'finished')
grads = tape.gradient(loss, [w1, b1, w2, b2])
w1 = w1 - le_r*grads[0]
b1 = b1 - le_r*grads[1]
w2 = w2 - le_r*grads[2]
b2 = b2 - le_r*grads[3]
c1 = tf.nn.sigmoid(vi @ w1 + b1)
c2 = tf.nn.softmax(c1 @ w2 + b2, axis=1)
out2 = tf.cast(tf.argmax(c2, axis=1), dtype=tf.int64)
acc = tf.reduce_sum(tf.cast(tf.equal(out2, vl), tf.float32))/vl.shape[0]
print('the {0} epoch finished and the acc ={1}'.format(epoch+1, acc))