引入模块
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets('MNIST_data',one_hot=True)#读入数据集,数据标签采用one_hot编码,也就是一个列向量,除了对应类别位置为1其余都为0
batch_size = 100#一个batch为100个数据
n_batch = mnist.train.num_examples//batch_size#一共n_batch个批次
x = tf.placeholder(tf.float32,[None,784])
y = tf.placeholder(tf.float32,[None,10])
keep_pro = tf.placeholder(tf.float32)#drop_out的概率
lr = tf.Variable(0.001,dtype=tf.float32)#学习率
w1 = tf.Variable(tf.truncated_normal([784,200],stddev=0.1))#第一层权重矩阵,初始化为均值为0标准差为0.1,第一层隐藏层设置200个神经元
b1 = tf.Variable(tf.zeros([200])+0.1)#第一层偏置初始化为0.1
z1 = tf.nn.relu(tf.matmul(x,w1)+b1)#用relu激活
z1_drop = tf.nn.dropout(z1,keep_pro)#drop_out
w2 = tf.Variable(tf.truncated_normal([200,100],stddev=0.1))
b2 = tf.Variable(tf.zeros([100])+.1)
z2 = tf.nn.relu(tf.matmul(z1_drop,w2)+b2)
z2_drop = tf.nn.dropout(z2,keep_pro)
w3 = tf.Variable(tf.truncated_normal([100,10],stddev=0.1))
b3 = tf.Variable(tf.zeros([10])+.1)
pre = tf.nn.softmax(tf.matmul(z2_drop,w3)+b3)#用softmax最为最后一层的激活函数以此来输出概率
#loss = tf.reduce_mean(tf.square(y-pre))#平均平方差损失
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y,logits=pre))#交叉熵损失
#train = tf.train.GradientDescentOptimizer(0.2).minimize(loss)#梯度下降法来做优化
train = tf.train.AdamOptimizer(lr).minimize(loss)#adam来做优化
correct_prediction = tf.equal(tf.argmax(y,1),tf.argmax(pre,1))#比较标签和预测值的类别是否相同
accuracy = tf.reduce_mean(tf.cast(correct_prediction,tf.float32))#计算准确率
#设三个列表来储存训练准确率和测试准确率
train_acc = 31*[0]
test_acc = 31*[0]
step = list(range(31))

with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for epoch in range(31):#训练31次
sess.run(tf.assign(lr,0.001*(0.95**epoch)))#学习率逐渐减小来防止在最优解处震荡幅度太大
for batch in range(n_batch):
batch_x,batch_y = mnist.train.next_batch(batch_size)#每次循环时选取下一个batch
sess.run(train,feed_dict={x:batch_x,y:batch_y,keep_pro:0.8})#drop_out概率设为0.8
train_acc[epoch] = sess.run(accuracy,
feed_dict={x:mnist.train.images,y:mnist.train.labels,keep_pro:1.0})#获得此时的训练集准确率
test_acc[epoch] = sess.run(accuracy,
feed_dict={x:mnist.test.images,y:mnist.test.labels,keep_pro:1.0})#获得此时的测试集准确率
print('epoch: '+str(epoch)+', test accuracy is: '+str(test_acc[epoch]))#输出结果
结果输出如下:
epoch: 0, test accuracy is: 0.941
epoch: 1, test accuracy is: 0.9542
epoch: 2, test accuracy is: 0.963
epoch: 3, test accuracy is: 0.9653
epoch: 4, test accuracy is: 0.9708
epoch: 5, test accuracy is: 0.9708
epoch: 6, test accuracy is: 0.9721
epoch: 7, test accuracy is: 0.9738
epoch: 8, test accuracy is: 0.9737
epoch: 9, test accuracy is: 0.9755
epoch: 10, test accuracy is: 0.9771
epoch: 11, test accuracy is: 0.9775
epoch: 12, test accuracy is: 0.9778
epoch: 13, test accuracy is: 0.9776
epoch: 14, test accuracy is: 0.9794
epoch: 15, test accuracy is: 0.9796
epoch: 16, test accuracy is: 0.9781
epoch: 17, test accuracy is: 0.9779
epoch: 18, test accuracy is: 0.9796
epoch: 19, test accuracy is: 0.9794
epoch: 20, test accuracy is: 0.9798
epoch: 21, test accuracy is: 0.9806
epoch: 22, test accuracy is: 0.9809
epoch: 23, test accuracy is: 0.9817
epoch: 24, test accuracy is: 0.98
epoch: 25, test accuracy is: 0.9803
epoch: 26, test accuracy is: 0.9804
epoch: 27, test accuracy is: 0.9809
epoch: 28, test accuracy is: 0.9814
epoch: 29, test accuracy is: 0.9814
epoch: 30, test accuracy is: 0.9815
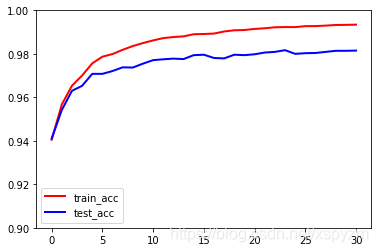
#绘制准确率随着训练次数的变化情况
import matplotlib.pyplot as plt
plt.figure()
plt.plot(step,train_acc,color='red',label='train_acc',linewidth=2)
plt.plot(step,test_acc,color='blue',label='test_acc',linewidth=2)
plt.ylim(0.9,1)
plt.legend()
plt.show()