(章节:标题一;1.1:标题二;1.1.1:标题三;...;知识点标题五
先自己总结,再摘抄书本内容作为解释。
第一章 关键字
什么是定义?什么是声明?它们有何区别?
定义声明最重要的区别:定义创建了对象并为这个对象分配了内存,声明没有分配内存。
举个例子:
A)int i;
B)extern int i;(关于 extern,后面解释)
A)是定义;B)是声明。
1.1 auto
编译器在默认的缺省情况下,所有变量都是 auto 的。
1.2,最快的关键字---- register
尽可能将变量存 CPU 内部寄存器,提高效率。
register:求编译器尽可能的将变量存在 CPU 内部寄存器中,而不是通过内存寻址访问以提高效率。注意是 尽可能,不是绝对。
注意:单个(整型)的值,长度小于或等于整型的长度;可能不存放在内存中,不能取址“&”。
1.2.1,皇帝身边的小太监----寄存器
CPU :皇帝;
寄存器:传话(数据)小太监;
大臣:内存(存储数据)。
好,那我们再联想到我们的 CPU。CPU 不就是我们的皇帝同志么?大臣就相当于我们的内存,数据从他这拿出来。那小太监就是我们的寄存器了(这里先不考虑 CPU 的高速缓存区)。数据从内存里拿出来先放到寄存器,然后 CPU 再从寄存器里读取数据来处理,处理完后同样把数据通过寄存器存放到内存里,CPU 不直接和内存打交道。这里要说明的一点是:小太监是主动的从大臣手里接过奏章,然后主动的交给皇帝同志,但寄存器没这么自觉,它从不主动干什么事。一个皇帝可能有好些小太监,那么一个 CPU 也可以有很多寄存器,不同型号的 CPU 拥有寄存器的数量不一样。
为啥要这么麻烦啊?速度!就是因为速度。寄存器其实就是一块一块小的存储空间,只不过其存取速度要比内存快得多。进水楼台先得月嘛,它离 CPU 很近,CPU 一伸手就拿到数据了,比在那么大的一块内存里去寻找某个地址上的数据是不是快多了?那有人问既然它速度那么快,那我们的内存硬盘都改成寄存器得了呗。我要说的是:你真有钱!
1.3,最名不符实的关键字----static
限制作用域 ;不要误以为关键字 static 很安静,其实它一点也不安静。这个关键字在 C 语言里主要有 两个作用。
1.3.1,修饰变量
静态全局变量:定义之处开始,到文件结尾处结束(仅限于变量被定义的文件中)。
静态局部变量:只能在这个函数里用。存储在静态区,值不被销毁,下次函数调用还能用。
静态局部变量,在函数体里面定义的,就只能在这个函数里用了,同一个文档中的其他函数也用不了。由于被 static 修饰的变量总是存在内存的静态区,所以即使这个函数运行结束,这个静态变量的值还是不会被销毁,函数下次使用时仍然能用到这个值。
例如:
1.‘j’静态全局变量可以在主函数输出,‘i’静态局部变量不可在主函数输出;
2.由于静态变量值不被销毁,下次函数调用仍然能使用,因此输出为
i 1 i 2 i 3 i 4 i 5 i 6 i 7 i 8 i 9 i 10
j:10
#include <iostream>
using namespace std;
static int j=0;
void fun1()
{
static int i = 0;
i++;
cout<<"i"<< i << endl;
}
void fun2()
{
//j = 0;
j++;
}
int main()
{
for (int k = 0; k < 10; k++)
{
fun1();
fun2();
}
cout << "j:" << j << endl;
return 0;
}1.3.2,修饰函数
修饰函数:作用域仅局限于本文件。(防止在别的文件中重名)
第二个作用:修饰函数。函数前加 static 使得函数成为静态函数。但此处“static”的含义不是指存储方式,而是指对函数的作用域仅局限于本文件(所以又称内部函数)。
使用内部函数的好处是:不同的人编写不同的函数时,不用担心自己定义的函数,是否会与其它文件中的函数同名。
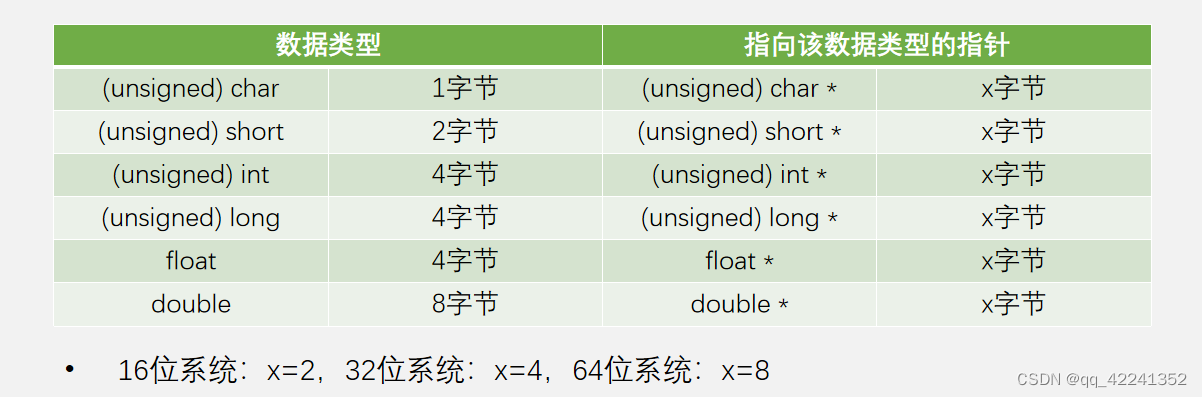
1.4,基本数据类型----short、int、long、char、float、double
1.4.1,数据类型与“模子”
short、int、long、char、float、double 这六个关键字代表 C 语言里的六种基本数据类型。其实就是个 模子。
现在我们联想一下,short、int、long、char、float、double 这六个东东是不是很像不同类型的藕煤器啊?拿着它们在内存上咔咔咔,不同大小的内存就分配好了,当然别忘了给它们取个好听的名字。在 32 位的系统上 short 咔出来的内存大小是 2 个 byte;int 咔出来的内存大小是4个byte;long咔出来的内存大小是4个byte;float咔出来的内存大小是4 个 byte;double 咔出来的内存大小是 8 个 byte;char 咔出来的内存大小是 1 个 byte。(注意这里指一般情况,可能不同的平台还会有所不同,具体平台可以用 sizeof 关键字测试一下)
1.4.2,变量的命名规则
1.5,最冤枉的关键字----sizeof
sizeof 是关键字不
1.5.2,sizeof(int)*p 表示什么意思?
sizeof(int)*p 表示:这里实际上sizeof(int)== 4,然后‘4*p = 16’,‘’
输出结果: i:16
#include <iostream>
using namespace std;
int main()
{
int p = 4;
//*p = NLLL;
int i = 10;
i = sizeof(int) *p;
cout << "i:" << i << endl;
return 0;
}留几个问题(讲解指针与数组时会详细讲解),32 位系统下:
int*p = NULL;
sizeof(p)的值是多少?
解:4字节;32位系统,指针统一4字节
sizeof(*p)呢?
解:4字节;int型数据4字节
int a[100];
sizeof (a) 的值是多少?
解:400字节;数组名是指向这个数组(数据结构)的指针,‘int’4字节,‘4*100=400’
注意:数组名的内涵在于其指代实体是一种数据结构,这种数据结构就是数组;数组名的外延在于其可以转换为指向其指代实体的指针。
sizeof(a[100])呢?//请尤其注意本例。
解:4字节;a[100]类似*(a+100),第100个元素的大小,一个‘int’型的数据。
sizeof(&a)呢?
解:4字节;数组的首地址,32位系统,指针4字节。
sizeof(&a[0])呢?
解:同上,4字节;&a[0]就是数组首地址(&a),32位系统,指针4字节。
int b[100];
void fun(int b[100])
{
sizeof(b);// sizeof (b) 的值是多少?
}
解:4字节;指针的好处:函数调用,传参传递指针时,就是传递指向这个内存区域的指针,减少数据复制。
代码与输出结果(为了方便辨别‘int’和指针的区别,我使用了‘char’。):
#include <iostream>
using namespace std;
void fun(int b[100])
{
sizeof(b);// sizeof (b) 的值是多少?
cout << "sizeof(b):" << sizeof(b)<< endl;
}
int main()
{
char *p = NULL;
cout << "sizeof(p):" << sizeof(p) << endl;
cout << "sizeof(*p):" << sizeof(*p) << endl;
char a[100] ;
cout << "sizeof(a):" << sizeof(a) << endl;
cout << "sizeof(a[100]):" << sizeof(a[100]) << endl;
cout << "sizeof(&a):" << sizeof(&a) << endl;
cout << "sizeof(&a[0]):" << sizeof(&a[0]) << endl;
char c = 'aaa';
cout << "char c = 'aaa'; sizeof(c):" << sizeof(c) << endl;
int b[100];
fun(b);
return 0;
}sizeof(p):4
sizeof(*p):1
sizeof(a):100
sizeof(a[100]):1
sizeof(&a):4
sizeof(&a[0]):4
char c = 'aaa'; sizeof(c):1
sizeof(b):4
1.4,signed、unsigned 关键字(原码、反码、补码)
我们知道计算机底层只认识 0、1.任何数据到了底层都会变计算转换成 0、1.那负数怎么
存储呢?肯定这个“-”号是无法存入内存的,怎么办?很好办,做个标记。把基本数据类型的最高位腾出来,用来存符号,同时约定如下:最高位如果是 1,表明这个数是负数,其值为除最高位以外的剩余位的值添上这个“-”号;如果最高位是 0,表明这个数是正数,其值为除最高位以外的剩余位的值。

说明:-128 的八位原码、反码、补码 – Jacky's Blog (jackyu.cn)
八位原码里面第一位是符号位,剩下7位是数值位,2^7=128 算上负号 256 个数字,+0/-0各占一个,所以八位二进制原码表示十进制数的范围为 -127~127。
这谁顶得住啊,原题就是求 -128~127。
后来查了下,-128 没有原码和反码,(人为规定)补码为1000000(-0)。

-128的补码 + ‘-1’的补码
1000 0000
+1111 1111
=0111 1111 == ‘-129’的补码

-256的补码低8位为0,开始新一轮循环(针对下题)


例如:当 i 继续增加到 255 的时候,-256 的补码的低 8 位为 0。然后当 i 增加到 256 时,-257 的补码的低 8 位全为 1,即低八位的补码为 0xff,如此又开始一轮新的循环。
因此a[0]到 a[254]里面的值都不为 0,而 a[255]的值为 0。strlen 函数是计算字符串长度的,并不包含字符串最后的‘\0’。而判断一个字符串是否结束的标志就是看是否遇到‘\0’。如果遇到‘\0’,则认为本字符串结束。a[254]是字符串最后一位,因此strlen(a)=255
#include <iostream>
using namespace std;
int main()
{
char a[1000];
int i;
for (i = 0; i < 1000; i++)
{
a[i] = -1 - i;
}
printf("%d", strlen(a));
return 0;
}结果:255
1),按照我们上面的解释,那-0 和+0 在内存里面分别怎么存储?
-0:1000 0000 =》 1111 1111 =》 0000 0000
+0:0000 0000 =》 0000 0000 =》 0000 0000
补码的作用之一就是为了消除‘0’在计算机中有两种表达方式(+0,-0)。
还有就是+1 + ‘-1’ 正确计算。
2)int i = -20; unsigned j = 10; i+j 的值为多少?为什么?
-10,在运算时会隐含的进行类型转化,低类型向高类型转换,比如,float和double型的浮点数数进行运算,会自动将float型转换成double型,再进行运算。结果也是高类型的。
3), 下面的代码有什么问题?
unsigned i ;
for (i=9;i>=0;i--)
{
printf("%u\n",i);
}
定义了一个无符号的整形变量‘i’,程序先输出9-0然后因为无法为负数,会死循环。
并且我们知道-1的补码为32个1,i为无符号整形,所以其对应10进制数位:2^32 -1=4294967295。后续输出就是‘-1’~‘-∞’的补码。
注:类似上面那个 ‘strlen(a)=255’ 案例,溢出补码到 ‘/0’ 会到一个新循环,溢出了会一直根据条件判断补码形式并进行相应操作,
1.6,if、else 组合
1.6.1,bool 变量与“零值”进行比较

1.6.2, float 变量与“零值”进行比较

1.6.3,指针变量与“零值”进行比较

1.6.4,else 到底与哪个 if 配对呢?
else始终与同一括号内最近的未匹配的 if 语句结合。始终与同一括号内最近的未匹配的 if 语句结合。
1.6.5,if 语句后面的分号
1.6.6,使用 if 语句的其他注意事项
非常重要的一点是,把正常情况的处理放在 if 后面,而不要放在 else 后面。当然这也符合把正常情况的处理放在前面的要求。
1.7,switch、case 组合
1.7.1,不要拿青龙偃月刀去削苹果
if、else 一般表示两个分支或是嵌套表示少量的分支,但如果分支很多的话……还是用
switch、case 组合吧。
1.7.2,case 关键字后面的值有什么要求吗?
记住:case 后面只能是整型或字符型的常量或常量表达式(想想字符型数据在内存里是怎么存的)。
1.7.3,case 语句的排列顺序
如果所有的 case 语句没有明显的重要性差别,那就按 A-B-C 或 1-2-3 等顺序排列 case
语句。
把正常情况放在前面,而把异常情况放在后面。
按执行频率排列 case 语句
把最常执行的情况放在前面,而把最不常执行的情况放在后面。
1.7.4,使用 case 语句的其他注意事项
简化每种情况对应的操作。
使得与每种情况相关的代码尽可能的精炼。
不要为了使用 case 语句而刻意制造一个变量。
case 语句应该用于处理简单的,容易分类的数据。如果你的数据并不简单,那可能使用if-
else if 的组合更好一些。
把 default 子句只用于检查真正的默认情况。
1.8,do、while、for 关键字
C 语言中循环语句有三种:while 循环、do-while 循环、for 循环。
while 循环:先判断 while 后面括号里的值,如果为真则执行其后面的代码;否则不执
行。while(1)表示死循环。
1.8.1,break 与 continue 的区别
break 关键字很重要,表示终止 本层循环。例子只有一层循环,当代码执行到break 时,循环便终止。
continue 表示终止 本次(本轮)循环。当代码执行到 continue 时,本轮循环终止,进入下一轮循环。
1.8.2,循环语句的注意点
在多重循环中,如果有可能,应当将最长的循环放在最内层,最短的循环放在最外层,以减少 CPU 跨切循环层的次数。
建议 for 语句的循环控制变量的取值采用“半开半闭区间”写法。

不能在 for 循环体内修改循环变量,防止循环失控。

循环要尽可能的短,要使代码清晰,一目了然。
把循环嵌套控制在 3 层以内。
1.9,goto 关键字
禁用。
1.10,void 关键字
void 的字面意思是“空类型”,void *则为“空类型指针”,void *可以指向任何类型的数据。void 几乎只有“注释”和限制程序的作用,因为从来没有人会定义一个 void 变量。
void 真正发挥的作用在于:
(1) 对函数返回的限定;
(2) 对函数参数的限定。
1.10.2,void 修饰函数返回值和参数
如果函数没有返回值,那么应声明为 void 类型
如果函数无参数,那么应声明其参数为 void
1.10.3,void 指针
千万小心又小心使用 void 指针类型。
如果函数的参数可以是任意类型指针,那么应声明其参数为 void *。
典型的如内存操作函数 memcpy 和 memset 的函数原型分别为:
void * memcpy(void *dest,constvoid *src,size_tlen);
void * memset ( void * buffer,intc,size_t num );
这样,任何类型的指针都可以传入 memcpy 和 memset 中,这也真实地体现了内存操作函数的意义,因为它操作的对象仅仅是一片内存,而不论这片内存是什么类型。
1.10.4,void 不能代表一个真实的变量
void 不能代表一个真实的变量。
void 的出现只是为了一种抽象的需要
1.10,return 关键字
return 用来终止一个函数并返回其后面跟着的值。
错误演示案例

str 属于局部变量,位于栈内存中,在 Func 结束的时候被释放,所以返回 str 将导致错误。
return 语句不可返回指向“栈内存”的“指针”,因为该内存在函数体结束时被自动销毁。
1.11,const 关键字也许该被替换为 readolny
建议只读的变量
1.11.1,const 修饰的只读变量
定义 const 只读变量,具有不可变性。
在局部变量中,可以用指针越位访问并且修改(变量还是在栈区)
全局变量的情况下,使用 `const` 修饰的全局变量可能会被优化到常量区。不可更改。
1.11.2,节省空间,避免不必要的内存分配,同时提高效率
编译器通常不为普通 const 只读变量分配存储空间,而是将它们保存在符号表中,这使得它成为一个编译期间的值,没有了存储与读内存的操作,使得它的效率也很高。
1.11.3,修饰一般变量
一般常量是指简单类型的只读变量。
1.11.4,修饰数组
定义或说明一个只读数组可采用如下格式:
int const a[5]={1,2,3,4,5};或
const int a[5]={1,2,3,4,5};
1.11.5,修饰指针
const int * p; // p 可变,p 指向的对象不可变
int const * p; // p 可变,p 指向的对象不可变
int * const p; // p 不可变,p 指向的对象可变
const int * const p; //指针 p 和 p 指向的对象都不可变
在平时的授课中发现学生很难记住这几种情况。这里给出一个记忆和理解的方法:
先忽略类型名(编译器解析的时候也是忽略类型名),我们看 const 离哪个近。“近水楼台先得月”,离谁近就修饰谁。

1.11.6,修饰函数的参数
void Fun(const int i);
告诉编译器(注释) i 在函数体中的不能改变,从而防止了使用者的一些无意的或错误的修改。
1.11.7,修饰函数的返回值
const 修饰符也可以修饰函数的返回值,返回值不可被改变。例如:
const int Fun(void);
1.12,最易变的关键字----volatile
编译器对访问该变量的代码就不再进行优化,从而可以提供对特殊地址的稳定访问。
1.13,最会带帽子的关键字----extern
extern,外面的、外来的意思。extern 可以置于变量或者函数前,以标示变量或者函数的定义在别的文件中,下面的代码用到的这些变量或函数是外来的,不是本文件定义的,提示编译器遇到此变量和函数时在其他模块中寻找其定义。
1.14,struct 关键字
struct 是个神奇的关键字,它将一些相关联的数据打包成一个整体,方便使用。
在网络协议、通信控制、嵌入式系统、驱动开发等地方,我们经常要传送的不是简单的字节流(char 型数组),而是多种数据组合起来的一个整体,其表现形式是一个结构体。经验不足的开发人员往往将所有需要传送的内容依顺序保存在 char 型数组中,通过指针偏移的方法传送网络报文等信息。这样做编程复杂,易出错,而且一旦控制方式及通信协议有所变化,程序就要进行非常细致的修改,非常容易出错。这个时候只需要一个结构体就能搞定。
1.14.1,空结构体多大?
空结构体的大小就定位 1 个 byte。
1.15,union 关键字
union 关键字的用法与 struct 的用法非常类似。
union 维护足够的空间来置放多个数据成员中的“一种”,而不是为每一个数据成员配置空间,在 union 中所有的数据成员共用一个空间,同一时间只能储存其中一个数据成员,所有的数据成员具有相同的起始地址。

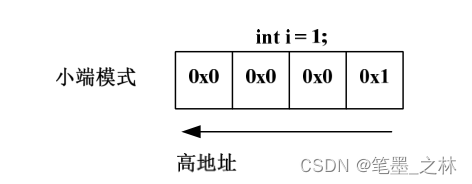
1.15.1,大小端模式对 union 类型数据的影响
大端模式(Big_endian):字数据的 高字节存储在 低地址中,而字数据的 低字节则存放
在 高地址 中。

小端模式(Little_endian):字数据的 高字节存储在 高地址中,而字数据的 低字节则存放
在 低地址 中。