开始本节学习笔记之前,先说几句题外话。其实对于C语言深度解剖这本书来说,看完了有一段时间了,一直没有时间来写这篇博客。正巧还刚刚看完了国嵌唐老师的C语言视频,觉得两者是异曲同工,所以就把两者一起记录下来。等更新完这七章的学习笔记,再打算粗略的看看剩下的一些C语言的书籍。
本节知识:
 -
-
- #include <stdio.h>
- #include <stdlib.h>
- int main(void)
- {
- static int j=0;
- int k;
- void fun1()
- {
- j=0;
- j++;
- printf("fun1 %d\n",j);
- }
- void fun2()
- {
- static int i=0;
- //i=0;
- printf("fun2 %d\n",i);
- i++;
- }
- for(k=0;k<10;k++)
- {
- fun1();
- fun2();
- }
- return 1;
- }
- #include <stdio.h>
- #include <stdlib.h>
- void fun(int b[100])
- {
- printf("sizeof(b) is %d\n",sizeof(b));
- }
- int main(void)
- {
- int *p=NULL;
- int a[100];
- int b[100];
- printf("sizeof(p) is %d\n",sizeof(p));
- printf("sizeof(*p) is %d\n",sizeof(*p));
- printf("sizeof(a[100]) is %d\n",sizeof(a[100]));
- printf("sizeof(a) is %d\n",sizeof(a));
- printf("sizeof(&a) is %d\n",sizeof(&a));
- printf("sizeof(&a[0] is %d\n",sizeof(&a[0]));
- fun(b);
- return 1;
- }
a.对于bool类型的比较:FLASE都是0 TRUE不一定是1 所以应该用if(bool_num); if(!bool_num);


- cosnt int* func()
- {
- static int count = 0;
- count++;
- return &count;
- }
h.在看const修饰谁,谁不变的问题上,可以把类型去掉再看,代码如下:
- struct student
- {
- }*str;
- const str stu3;
- str const stu4;
str是一个类型 ,所以在去掉类型的时候,应该都变成const stu3和const stu4了,所以说应该是stu4和stu3这个指针不能被赋值。
12.关键字volatile:
volatile搞嵌入式的,一定都特别属性这个关键字,记得第一使用这个关键字的时候是在韦东山老师的,Arm裸机视频的时候。volatile是告诉编译不要对这个变量进行任何优化,直接在内存中进行取值。一般用在对寄存器进行赋值的时候,或修饰可能被多个线程访问的变量。
- #include <stdio.h>
- #include <stdlib.h>
- int main(void)
- {
- int a[5]={1,2,3,4,5};
- int *p=(int *)(&a+1); //数组指针 加一 进行正常的指针运算 走到数
- 组尾
- int *d=(int *)((int)a+1);//地址加一 不是指针运算
- //printf("%x\n",*((char *)((int)a+1)-1));
- /*因为是小端存储 高地址 0x00 0x00 0x00 0x02 0x00 0x00 0x00 0x01 低地址*/
- /*变成了 0x02 0x00 0x00 0x00 */
- printf("%x,%x",p[-1],*d); /* 第二个值就是这么存储的0x02 0x00 0x00 0x00 低地址处 所以就是2000000*/
- int a=0x11223344;
- char *p=(char *)((int)&a);
- printf("%x\n%x\n",*(p+0),p+0);
- printf("%x\n%x\n",*(p+1),p+1);
- return 0;
- }
- #include <stdio.h>
- #include <stdlib.h>
- union
- {
- int i;
- char a[2];
- }*p,u;
- int main(void)
- {
- p=&u;
- p->i=0x3839;
- printf("%x\n",p->i);
- printf("a0p=%x,a1p=%x\n",&(p->a[0]),&(p->a[1]));
- printf("a0=%x,a1=%x\n",p->a[0],p->a[1]);
- return 0;
- }
枚举enum其实就是 int类型,用来保存枚举常量的。enum枚举类型,这个才是真正的常量,定义常量一般用enum 。#define是宏定义是在预编译期间单纯的替换。#define宏定义无法调试,枚举常量是可以调试的。#define宏定义是无类型信息的,枚举类型是有类型信息的常量,是int型的。
a.typedef用于给一个已经存在的数据类型重新命名。
- typedef unsigned int int32;

typedef char* PCHAR; PCHAR p1,p2; //p1和p2都是 char*型
e.有一个知识点忘记了,嘿嘿,程序如下:
- typedef struct student
- {
- }str,*str1;
str1 abc; 就是定义一个struct student *类型
str abc; 就是定义一个struct student 类型
- 程序一:
- for(i=0; i<m; i++)
- {
- for(j=0; j<n; j++)
- {
- for(k=0; k<p; k++)
- {
- c[i][j] = a[i][k] * b[k][j];
- }
- }
- }
- 程序二:
- for(i=0; i<m; i++)
- {
- for(k=0; k<p; k++)
- {
- for(j=0; j<n; j++)
- {
- c[i][j] = a[i][k] * b[k][j];
- }
- }
- }

- #include <stdio.h>
- #include <stdlib.h>
- #include <string.h>
- int main()
- {
- char a[1000];
- int i;
- for(i=0; i<1000; i++)
- {
- a[i] = (-1-i);
- }
- while(a[i])
- {
- printf("%d\n",a[i]);
- i++;
- }
- printf("%d\n",strlen(a));
- return 0;
- }
本节遗留问题:
本节接触了,C语言中的三大蛋疼:符号优先级 ++i顺序点 贪心法 (其实这里面好多都是跟编译器有关的,而且有好多问题都是可以通过良好的编程习惯避免的)
本节知识点:
1.注释问题:
注释不能把关键字弄断,如:in/*注释*/t
注释不是简单的剔除,而是使用空格替换
编译器认为双引号括起来的内容都是字符串,双斜杠也不例外。如:char *p = "heh//jfeafe" //不起注释作用
2.接续符:
接续符\ ,常用于宏定义中
- #define SWAP(a,b) \
- { \
- int temp = a; \
- a = b; \
- b = temp; \
- }
反斜杠同时有接续符和转义符两个用途,当接续符使用的时候,可以直接在程序中出现。当转义符使用的时候,必须是出现在字符串中。
接续符,也用与接续一个关键字,代码如下, 注意: 但是直接连接\两边不能有空格。
- #include <stdio.h>
- #include <stdlib.h>
- int main()
- {
- cha\
- r a = 12;
- return 0;
- }
3.逻辑运算符:有一个短路规则
4.最容易忘记规则的两个运算符:
三目运算符:(a?b:c) 当a的值为真的时候 返回b的值,否则返回c的值
逗号表达式:a,b 表达式的值为b的值
5.位运算:
对于左移和右移<< >>问题 :无符号的,和有符号左移,都是补0 ,对于有符号的在右移动的时候,正数补零,负数补什么跟编译器有关系。并且左移和右移的大小不能大于数据的长度,也不能小于0。
交换两个数,有一种不借助中间变量的方法,就是异或,代码如下:
- #include <stdio.h>
- #define SWAP1(a,b) \
- { \
- int temp = a; \
- a = b; \
- b = temp; \
- }
- #define SWAP2(a,b) \
- { \
- a = a + b; \
- b = a - b; \
- a = a - b; \
- }
- #define SWAP3(a,b) \
- { \
- a = a ^ b; \
- b = a ^ b; \
- a = a ^ b; \
- }
- int main()
- {
- int a = 1;
- int b = 2;
- SWAP1(a,b);
- SWAP2(a,b);
- SWAP3(a,b);
- return 0;
- }
6.i++,i--顺序点:
只有 i++ i--才有顺序点 就是什么时候开始加,什么时候开始减。真心对于顺序点 是搞不懂啊~~~ (++i)+(++i)+(++i) ,在gcc中是5+5+6(DEV C++) ,在vc中是6+6+6(vc++6.0) ,不同编译器顺序点不一样。这个例子的顺序点 在; 前。
a=((++i),(++i),(++i)) 它的顺序点在每个逗号前面完成计算。我觉得特殊的顺序点 是可以通过合理的顺序布局来避免的。
7.贪心法:
每一个符号应该尽可能多的包含字符
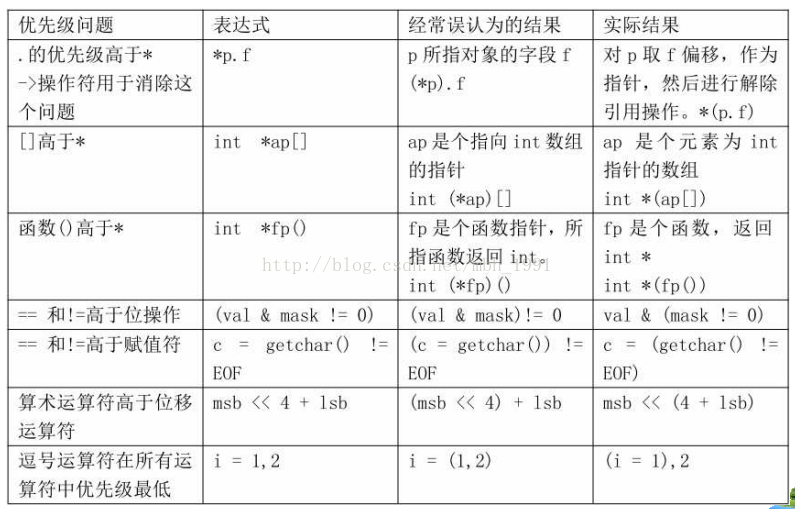
8.符号运算优先级问题:
个人觉得优先级不用记,好好的写括号吧~~~
给一个易错优先级表,如图:
9.c语言中的类型转换:
c语言中有两种转换类型,分别是:隐式转换和显示转换(强制类型转换)
隐式转换的规则:
a.算术运算中,低类型转换为高类型
b.赋值运算中,表达式的类型转换为左边变量的类型
c.函数调用时,实参转换成形参的类型
d.函数返回值,return表达式转换为返回值的类型

隐式转换的例子,代码如下:
- #include <stdio.h>
- int main()
- {
- int i = -2;
- unsigned int j = 1;
- if( (i + j) >= 0 )
- {
- printf("i+j>=0\n");
- }
- else
- {
- printf("i+j<0\n");
- }
- printf("i+j=%d\n", i + j);
- return 0;
- }
注意:在使用C语言的时候,应该特别注意数据的类型是否相同,尽量避免隐式转换带来的不必要的麻烦~~~
本节知识点:
1.编译过程的简介:
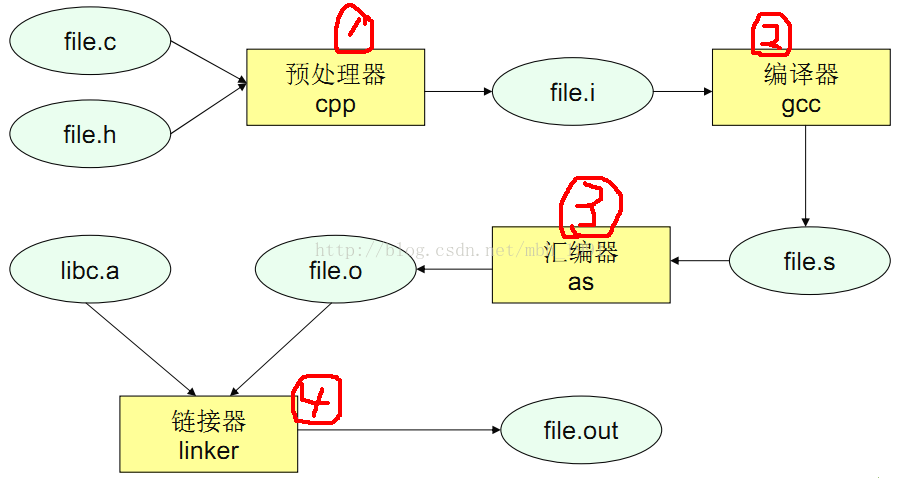
预编译:
a.处理所有的注释,以空格代替。
b.将所以#define删除,并展开所有的宏定义,字符串替换。
c.处理条件编译指令#if,#ifdef,#elif,#else,#endif
d.处理#include,并展开被包含的文件,把头文件中的声明,全部拷贝到文件中。
e.保留编译器需要使用的#pragma指令、
怎么样观察这些变化呢?最好的方法就是在GCC中,输入预处理指令,可以看看不同文件经过预处理后变成什么样了,预处理指令:gcc -E file.c -o file.i 注意:-C -E一起使用是预编译的时候保留注释。
编译:
a.对预处理文件进行一系列词法分析,语法分析和语义分析
词法分析:主要分析关键字,标示符,立即数等是否合法
语法分析:主要分析表达式是否遵循语法规则
语义分析:在语法分析的基础上进一步分析表达式是否合法
b.分析结束后进行代码优化生成相应的汇编代码文件 编译指令:gcc -S file.c -o file.s
汇编:
汇编器将汇编代码转变为机器可以执行的指令,每个汇编语句几乎都对应一条机器指令,其实机器指令就是机器码,就是2进制码。汇编指令:gcc -c file.c -o file.o 注意:-c是编译汇编不连接。
链接:
再把产生的.o文件,进行链接就可以生成可执行文件。连接指令:gcc file.o file1.o -o file 这句指令是链接file.o和file1.o两个编译并汇编的文件,并生成可执行文件file。
链接分两种:静态链接和动态链接,静态链接是在编译器完成的,动态链接是在运行期完成的。静态链接的指令是:gcc -static file.c -o file对于一些没有动态库的嵌入式系统,这是常用的。
一般要想通过一条指令生成可执行文件的指令是: gcc file.c -o file
资料:这里面说到了很多关于gcc的使用的问题,我提供一个gcc的学习资料,个人觉得还不错,也不长,就是一个txt文档,很全面。资源下载地址http://download.csdn.net/detail/qq418674358/6041183 Ps:嘿嘿,设了一个下载积分,因为真的是没分用了!希望大家见谅哈!
2.c语言中的预处理指令:#define、#undef(撤销已定义过的宏名)、#include、#if、#else、#elif、#endif、#ifdef、#ifndef、#line、#error、#pragma。还有一些ANSI标准C定义的宏:__LINE__、__FILE__、__DATA__、__TIME__、__STDC__。这样使用printf("%s\n",__TIME__); printf(__DATE__);
一个#undef的例子:
- #include <stdio.h>
- #include <stdlib.h>
- #include <string.h>
- #define X 2
- #define Y X*2
- #undef X
- #define X 3
- int main()
- {
- printf("%d\n",Y);
- return 0;
- }
这个输出的是6,说明了#undef的作用
3.宏定义字符串的时候:应该是 #define HELLO "hello world" 记住是双引号。还有就是一切宏都是不能有分号的,这个一定要切忌!!!
4.宏与函数的比较:
a.宏表达式在预编译期被处理,编译器不知道有宏表达式存在
b.宏表达式没有任何的"调用"开销
c.宏表达式中不能出现递归定义
5.为什么不在头文件中定义全局变量:
如果一个全局变量,想要在两个文件中,同时使用,那这两个文件中都应该#include这个头文件,这样的话就会出现重复定义的问题。其实是重名的问题,因为#include是分别在两个文件中展开的,试想一下,如果在两个文件中的开始部分,都写上int a = 10; 是不是也会报错。可能你会说那个#ifndef不是防止重复定义吗?是的 ,那是防止在同一个文件中,同时出现两次这个头文件。现在是两个文件中,所以都要展开的。全局变量就重名了!!!所以 对于全局变量,最好是定义在.c文件中,不要定义在头文件中。
6.#pargma pack 设置字符对齐,看后面一节专门写字符对齐问题的!!!
7.#运算符(转换成字符串):
假如你希望在字符串中包含宏参数,那我们就用#号,它把语言符号转换成字符串。
#define SQR(x) printf("the "#x"lait %d\n",((x)*(x)));
SQR(8)
输出结果是:the 8 lait 64 这个#号必须使用在带参宏中
有个小例子:
- #include <stdio.h>
- #include <stdlib.h>
- #include <string.h>
- /*在字符串中 加入宏参用的*/
- #define SCAN(N,String) scanf("%"#N"s",String); //N是截取的个数 String是存储的字符串
- int main()
- {
- char dd[256];
- SCAN(3,dd) //记得没有分号哈 自定义 任意格式输入的scanf 截取输入的前三个
- printf("%s\n",dd);
- return 1;
- }
8.##运算符(粘合剂)
一般用于粘贴两个东西,一般是用作在给变量或函数命名的时候使用。如#define XNAME(n) x##n
XNAME(8)为8n 这个##号可以使用在带参宏或无参宏中
下面是一个##运算符的小例子,代码如下:
- #include <stdio.h>
- #include <stdlib.h>
- #include <string.h>
- #define BL1 bb##ll##1
- #define BL(N) bbll##N
- int main()
- {
- int BL1=10;
- int BL(4)=15;
- printf("%d\n",bbll1);
- printf("%d\n",bbll4);
- return 1;
- }
注意:#号和##号都必须只能在宏定义中使用,不能使用在其他地方
9.其实预编译这块还有一些,不常用到的预编译指令,也是盲点,但是不难理解,用到的时候查查就好。比如说#line、#error、#warning等。
很多人都觉得内存对齐这个问题很难,很不好算,总算错,其实我想说只要你画一画就没那么难了。好了,进入正题。
本节知识点:
1.结构体为什么要内存对齐(也叫字节对齐):
其实我们都知道,结构体只是一些数据的集合,它本身什么都没有。我们所谓的结构体地址,其实就是结构体第一个元素的地址。这样,如果结构体各个元素之间不存在内存对齐问题,他们都挨着排放的。对于32位机,32位编译器(这是目前常见的环境,其他环境也会有内存对齐问题),就很可能操作一个问题,就是当你想要去访问结构体中的一个数据的时候,需要你操作两次数据总线,因为这个数据卡在中间,如图:
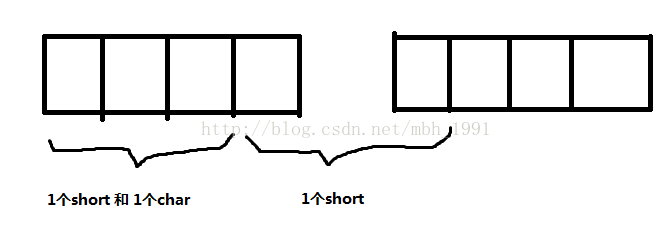
在上图中,对于第2个short数据进行访问的时候,在32位机器上就要操作两次数据总线。这样会非常影响数据读写的效率,所以就引入了内存对齐的问题。
另外一层不太重要的原因是:某些硬件平台只能从规定的地址处取某些特定类型的数据,否则会抛出硬件异常。
2.内存对齐的规则:
a.第一个成员起始于0偏移处
b.每个成员按其类型大小和指定对齐参数n中较小的一个进行对齐
c.结构体总长度必须为所有对齐参数的整数倍
d.对于数组,可以拆开看做n个数组元素
3.来几个小例子,画画图,有助于理解:
第一个例子,代码如下:
- #include <stdio.h>
- struct _tag_str1
- {
- char a;
- int b;
- short c;
- }str1;
- struct _tag_str2
- {
- char a;
- short c;
- int b;
- }str2;
- int main()
- {
- printf("sizeof str1 %d\n",sizeof(str1));
- printf("sizeof str2 %d\n",sizeof(str2));
- return 0;
- }
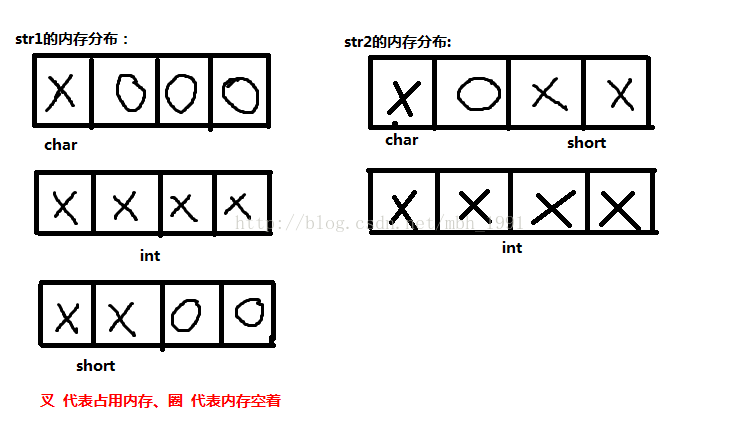
看图很自然就知道了str1为12个字节,str2为8个字节。
第二个例子,上面的那个例子有好多问题还没有考虑到,比如说上面的那个例子在8字节对齐,和4字节对齐的情况都是一样的。结构体中嵌套结构体的内存对齐怎么算,所以就有了这个例子,代码如下:
- #include <stdio.h>
- #pragma pack(8)
- //#pragma pack(4)
- struct S1
- {
- short a;
- long b;
- };
- struct S2
- {
- char c;
- struct S1 d;
- double e;
- };
- #pragma pack()