
论文名称:FreeU: Free Lunch in Diffusion U-Net
文章链接:https://arxiv.org/abs/2309.11497
代码仓库:https://github.com/ChenyangSi/FreeU
项目主页:https://chenyangsi.top/FreeU
机器学习领域中一个著名的基本原理就是“没有免费的午餐定理”,该定理指示我们:没有一种机器学习算法是适用于所有情况的,简单来说就是在构建算法时,有得必有失。本文介绍一篇来自南洋理工大学S-Lab的研究论文,本文的题目非常有趣:“扩散U-Net网络中的免费午餐”。作者在文中对U-Net架构在扩散过程中的基本原理进行了深入的探索,作者发现,U-Net的backbone网络主要来完成去噪过程,而其中的跳跃连接主要将高频特征引入解码器模块,从而导致整体模型忽略了从backbone中提取到的语义信息。因此本文提出了一种简单有效的方法,称为FreeU,FreeU的主要操作是重新权衡了U-Net的跳跃连接和backbone特征图对最终输出的贡献,而无需额外的训练或微调即可提高模型的生成图像质量,因此称为是“免费的午餐”。在实际操作时,只需要对现有的扩散模型,例如Stable Diffusion、DreamBooth、ModelScope、Rerender和ReVersion等加入几行即插即用的重加权代码就可以提高模型的综合性能。
01. 介绍
扩散模型在生成模型领域引入了一种新型生成范式,整体过程由扩散过程和去噪过程构成,在扩散过程中,向输入数据逐渐添加高斯噪声,而在去噪过程中,原始输入数据通过学习逆扩散操作将原始序列从噪声状态中恢复出来。通常,扩散模型会使用U-Net来迭代预测每个去噪步骤中要去除的噪声信号。目前也有一些工作开始从频率域的角度来分析扩散模型的去噪过程,本文提出使用傅立叶变换工具来进行观察扩散生成,下图展示了扩散生成过程中傅里叶逆变换后相关低频和高频空间域的变化情况,可以看出,低频分量在整个过程中表现除了较为柔和的变化率,而高频分量在整个去噪过程中表现出更明显的动态。

下图展示了与上图步骤对应的傅里叶对数振幅变化图,从图中可以分析得到:低频分量本质上体现了图像的全局结构和特征,可以理解为是一张图像的图像本质,因此在扩散过程中低频分量应该尽可能保持稳定。相反,高频成分包含图像中的边缘和纹理,这些更精细的细节对噪声非常敏感。

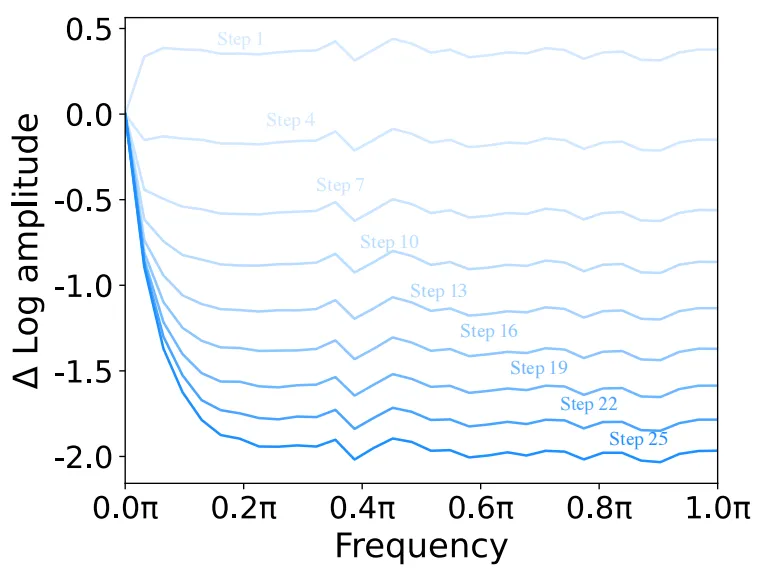
根据上述分析去噪过程中低频和高频分量之间的关系,本文从扩散U-Net的架构出发,作者发现U-Net中的跳跃连接会将高频特征不断引入解码器模块,这样会导致模型的backbone在推理时的去噪能力受到影响,从而导致生成异常图像细节,如下图第一行所示。

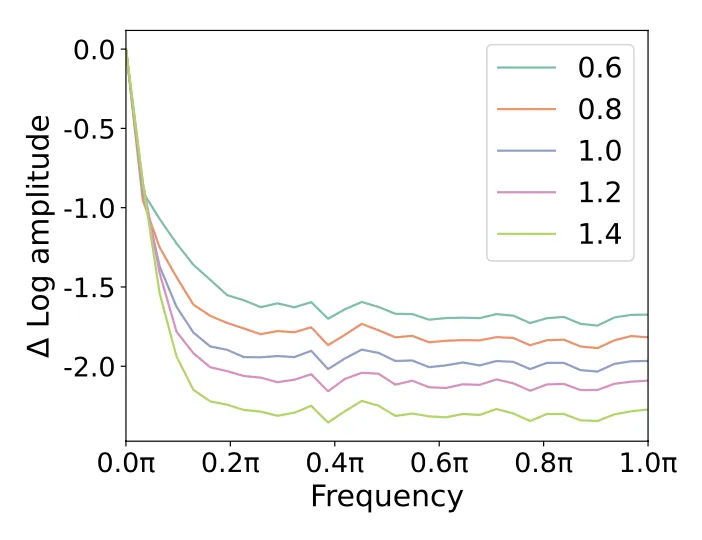
基于以上观察,本文提出了一种FreeU的调制策略,即在模型的扩散推理阶段,设计了两个专门的调制因子,其中一个因子称为backbone特征因子,用来放大backbone的特征图效应,从而加强去噪过程,同时为了防止去噪带来的过度纹理平滑,第二个因子被设计为跳连特征缩放因子,用来进行权衡调节。
02. 本文方法
2.1 扩散U-Net的架构
下图展示了扩散U-Net的主要框架,主要包括一个主要骨干网络,由编码器和解码器构成,以及促进编码器和解码器相应层之间信息传输的跳跃连接。
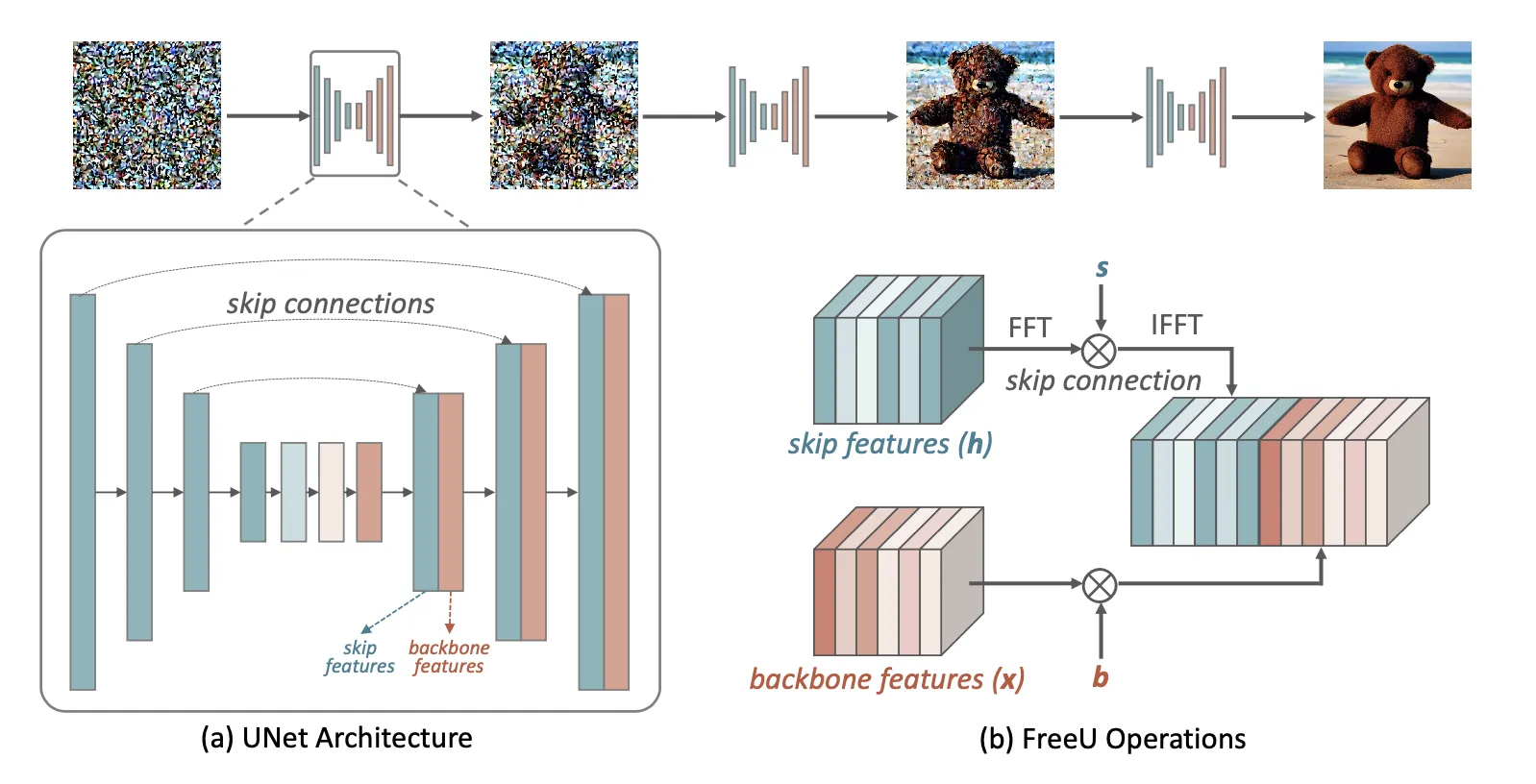



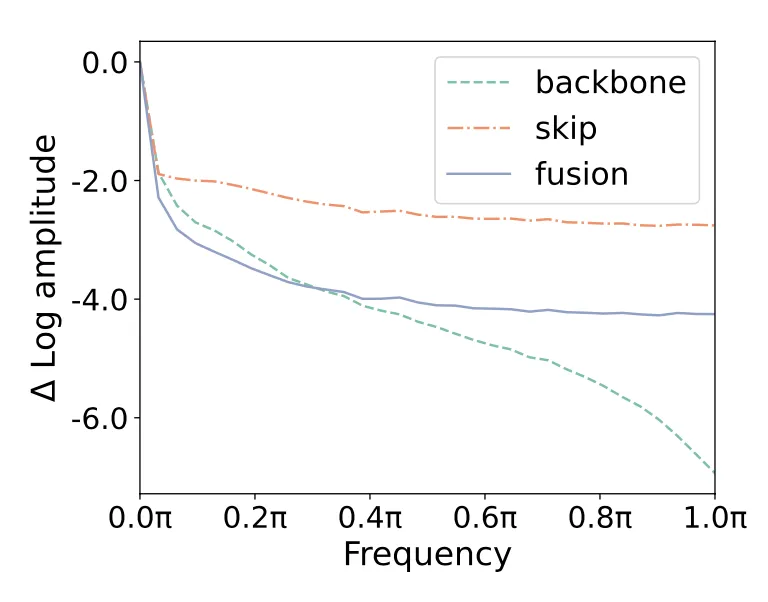
然而,跳跃连接可以将编码器的浅层特征块直接传递给解码器,由于这些特征都属于高频信息,作者猜测,在U-Net架构的训练过程中,这些高频特征的存在可能会加速解码器学习对噪声预测的能力。
2.2 扩散U-Net中的免费午餐

03. 实验效果
本文的实验主要侧重于评估FreeU在目前流行的图像生成任务上的效果,例如文本到图像生成(text-to-image)和文本到视频生成(text-to-video),此外,由于FreeU的一大亮点是其可以轻松插入到现有的预训练扩散模型中来提升性能,因此作者还选用了一些流行的下游模型进行了实验。
3.1 文本到图像生成
文本到图像生成作者使用了Stable Diffusion模型作为baseline,并且将FreeU集成在上面,下图展示了使用FreeU对SD模型增强后的效果。可以看到,将FreeU 可以改善SD在实体描绘和细粒度细节的效果。例如,当出现“正在拍摄一辆蓝色汽车”的提示时,FreeU会细化图像,消除屋顶的不规则性并增强周围结构的纹理复杂性。

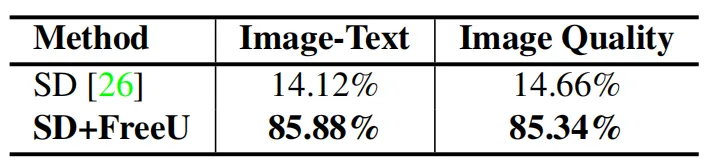
此外,作者还邀请了35名测试员来对图像质量和图像文本对齐情况进行评估。每个测试员都会收到一条文本提示和两张相应的合成图像,一张来自SD,另一张来自SD+FreeU。然后,测试员分别选择他们认为图像文本对齐和图像质量优异的图像,下图展示了最终的实验结果,可以看到测试员将大多数投票投给了SD+FreeU。
3.2 文本到视频生成
对于文本到视频合成,作者使用ModelScope[2]作为基础baseline,作者使用了与文本到图像合成类似的评估方法,从下表中显示的结果也表明大多数测试员更喜欢FreeU生成的视频。

3.3 下游模型实验
在这一部分,作者直接将FreeU嵌入到Dreambooth[3],这是一项发表在CVPR2023上的个性化文本到图像生成模型。如下图展示了使用FreeU的增强效果,其中DreamBooth模型很难根据提示“一张骑摩托车的人偶照片”来合理的生成人偶腿部的外观,而FreeU增强版本可以巧妙地解决这一问题。

此外,作者还评估了FreeU对Rerender[4]的影响,这是一种zero-shot文本引导视频转换模型。下图展示了改进效果,例如,当文本提示为“戴着太阳镜的狗”时,Reender会生成一个带有与“太阳镜”相关的视频,但是视频中有一些伪影。加入FreeU后可以有效的消除此类伪影,从而提高最终的生成效果。

04. 总结
本文引入了一种优雅简单但高效的FreeU扩散模型方法,FreeU深入刨析了现有扩散模型内部不同组件之间的交互关系,其主干网络主要用于去噪过程,而跳跃连接主要将高频特征引入解码器。作者使用了一种巧妙的重加权方式来对两个模块进行重新调制,从而在不产生额外计算成本的情况下提升模型性能。FreeU可以无缝集成到各种扩散基础模型及其下游模型中,来显著增强生成图像中的复杂细节同时提高整体的视觉保真度。
参考
[1] Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. In NeurIPS, 2020.
[2] Zhengxiong Luo, Dayou Chen, Yingya Zhang, Yan Huang, Liang Wang, Yujun Shen, Deli Zhao, Jingren Zhou, and Tieniu Tan. VideoFusion: Decomposed diffusion models for high-quality video generation. In CVPR, 2023.
[3] Nataniel Ruiz, Yuanzhen Li, Varun Jampani, Yael Pritch, Michael Rubinstein, and Kfir Aberman. Dreambooth: Finetuning text-to-image diffusion models for subject-driven generation. In CVPR, 2023.
[4] Shuai Yang, Yifan Zhou, Ziwei Liu, and Chen Change Loy. Rerender a video: Zero-shot text-guided video-to-video translation. arXiv preprint arXiv:2306.07954, 2023.
关于TechBeat人工智能社区
▼
TechBeat(www.techbeat.net)隶属于将门创投,是一个荟聚全球华人AI精英的成长社区。
我们希望为AI人才打造更专业的服务和体验,加速并陪伴其学习成长。
期待这里可以成为你学习AI前沿知识的高地,分享自己最新工作的沃土,在AI进阶之路上的升级打怪的根据地!
更多详细介绍>>TechBeat,一个荟聚全球华人AI精英的学习成长社区