机器学习的分类算法有多种,今天我们就来一起学习一下其中的一种——朴素贝叶斯。
朴素贝叶斯是贝叶斯决策理论的一部分,而贝叶斯决策理论的核心思想就是选择具有最高概率的决策。
比如,一个村子里有两个小偷A和B,p1表示村子失窃是A干的概率,p2表示村子失窃是B干的概率。现在如果村子失窃了,猜测是谁干的。
如果p1>p2,则认为是A干的,反之p1<p2,则认为是B干的。这就是贝叶斯决策理论的核心思想。
下面我们就用一个二分类问题的实际例子来体验朴素贝叶斯吧。
网站的留言大部分都有一个审批的程序,来判断一个留言是否为侮辱性留言,如果是则不让其在网站上显示。这就是一个典型的二分类实际问题,留言有侮辱性和非侮辱性两个分类。
要实现留言的分类程序,大致有以下两个必须解决的难点:
1.留言怎么在内存中存储,怎么表示?
2.怎么计算留言属于某个分类的概率?
下面我们来逐一探讨下这两个问题。对于一条具体的留言来说,除去标点符号,无非就是一些单词的集合。而有些单词在一个留言中出现了,但不一定会出现在其他留言中。我们可以将所有留言中出现的单词组合成一个词汇表,对于一条具体的某个留言,都对应一个标志数组,其对应索引值表示词汇表的词汇在这个留言中是否出现。
比如,留言1为“I Love You”, 留言2为“I Hate You”,此时留言1和留言2组成的词汇表为“I Love Hate You”,留言1对应的标志数组为[1,1,0,1],留言2对应的标志数组为[1,0,1,1]。
好了,让我们用代码实现这个功能吧。
#加载留言集合和留言标签
def loadDataSet():
messageList1=[['my', 'dog', 'has', 'flea', 'problems', 'help', 'please'],
['maybe', 'not', 'take', 'him', 'to', 'dog', 'park', 'stupid'],
['my', 'dalmation', 'is', 'so', 'cute', 'I', 'love', 'him'],
['stop', 'posting', 'stupid', 'worthless', 'garbage'],
['mr', 'licks', 'ate', 'my', 'steak', 'how', 'to', 'stop', 'him'],
['quit', 'buying', 'worthless', 'dog', 'food', 'stupid']]
messageClass1 = [0,1,0,1,0,1] #留言标签 1=侮辱性 0=非侮辱性
return messageList1,messageClass1
'''
创建词汇表
参数为留言集合
'''
def createVocaList(messageList1):
vocaList1 = set() #使用集合可以去掉重复的单词
for message in messageList1:
for word in message:
vocaList1.add(word)
vocaList1 = list(vocaList1)
vocaList1 = sorted(vocaList1) #单词排序
return vocaList1
'''
求留言对应的标志数组
参数为词汇表和某一条留言
'''
def messageToFlag(vocaList1,message):
flag = [0]*len(vocaList1)
for word in message:
if word in vocaList1:
flag[vocaList1.index(word)] = 1
else:
print(word+'不在此词汇表中')
return flag
上面的loadDataSet()函数创建了一些实验样本,返回的是6条留言集合和对应的分类。createVocaList()函数用于创建词汇表,输入参数为留言集合,返回的是一个无重复单词并按字母排序的词汇表。messageToFlag()函数用于求某一个具体留言对应的标志数组,参数为词汇表和某一个具体留言。
测试一下,输出词汇表和第一条留言对应的标志数组。
#测试 messageList , messageClss = loadDataSet() vocaList = createVocaList(messageList) print(vocaList) print(messageToFlag(vocaList,messageList[0]))
输出结果如下。
['I', 'ate', 'buying', 'cute', 'dalmation', 'dog', 'flea', 'food', 'garbage', 'has', 'help', 'him', 'how', 'is', 'licks', 'love', 'maybe', 'mr', 'my', 'not', 'park', 'please', 'posting', 'problems', 'quit', 'so', 'steak', 'stop', 'stupid', 'take', 'to', 'worthless'] [0, 0, 0, 0, 0, 1, 1, 0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 1, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0]
到此,我们解决了第一个难点。就是利用所有留言生成一个词汇表,接着就像查字典一样为每一个留言生成一个标志数组,这样就解决了留言的存储和表示问题。
现在我们来看看第二个问题,怎么计算留言属于哪个分类的概率。通过上面的分析,我们知道留言对应一个标志数组w,求留言属于哪个分类的概率即求P(ci|w)的值。从条件概率的计算公式,我们有如下计算P(ci|w)的方法。
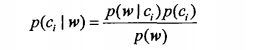
其中可以通过类别i(侮辱性或非侮辱性)的留言数除以留言总数得到P(ci)。我们假设单词是独立出现的,P(w|ci)可写成P(w1,w2,...,wn|ci),其中n为词汇表中单词个数。由于w1、w2、...、wn是独立的,所以P(w1,w2......wn|ci)为P(w1|ci)、P(w2|ci)、...、P(wn|ci)的乘积。P(wi|ci)可以通过分类i中对应词汇表的第wi个单词出现的次数除以分类i的单词总数计算得到。
下面代码就是求以上的概率。
'''
求P(c1):留言为侮辱性的概率
求P(wi|ci):分类i中对应词汇表的第wi个单词出现的概率
参数为留言对应的标志数组集合和留言分类标签
'''
def calcuProbability(messageFlag1,messageClass1):
messageNum = len(messageClass1) #留言总数
class1Probability = sum(messageClass1) / float(messageNum) #P(c1)
WordNum = len(messageFlag1[0]) #词汇表长度
pw0 = np.zeros(WordNum) #非侮辱性中词汇表各单词出现的次数
pw1 = np.zeros(WordNum) #侮辱性中词汇表各单词出现的次数
p0Num = 0 #非侮辱性的单词个数
p1Num = 0 #侮辱性的单词个数
for i in range(messageNum):
if messageClass1[i] == 1: #侮辱性留言
p1Num += sum(messageFlag1[i])
pw1 += messageFlag1[i]
else: #非侮辱性留言
p0Num += sum(messageFlag1[i])
pw0 += messageFlag1[i]
pw0 = pw0 / float(p0Num)
pw1 = pw1 / float(p1Num)
return pw0, pw1, class1Probability
测试一下。
#测试
messageList , messageClss = loadDataSet()
vocaList = createVocaList(messageList)
messageFlag = []
for message in messageList:
messageFlag.append(messageToFlag(vocaList,message))
p0, p1, c1 = calcuProbability(messageFlag,messageClss)
print(vocaList)
print(p0)
print(p1)
print(c1)
结果如下。
['I', 'ate', 'buying', 'cute', 'dalmation', 'dog', 'flea', 'food', 'garbage', 'has', 'help', 'him', 'how', 'is', 'licks', 'love', 'maybe', 'mr', 'my', 'not', 'park', 'please', 'posting', 'problems', 'quit', 'so', 'steak', 'stop', 'stupid', 'take', 'to', 'worthless'] [0.041666666666666664, 0.041666666666666664, 0.0, 0.041666666666666664, 0.041666666666666664, 0.041666666666666664, 0.041666666666666664, 0.0, 0.0, 0.041666666666666664, 0.041666666666666664, 0.083333333333333329, 0.041666666666666664, 0.041666666666666664, 0.041666666666666664, 0.041666666666666664, 0.0, 0.041666666666666664, 0.125, 0.0, 0.0, 0.041666666666666664, 0.0, 0.041666666666666664, 0.0, 0.041666666666666664, 0.041666666666666664, 0.041666666666666664, 0.0, 0.0, 0.041666666666666664, 0.0] [0.0, 0.0, 0.052631578947368418, 0.0, 0.0, 0.10526315789473684, 0.0, 0.052631578947368418, 0.052631578947368418, 0.0, 0.0, 0.052631578947368418, 0.0, 0.0, 0.0, 0.0, 0.052631578947368418, 0.0, 0.0, 0.052631578947368418, 0.052631578947368418, 0.0, 0.052631578947368418, 0.0, 0.052631578947368418, 0.0, 0.0, 0.052631578947368418, 0.15789473684210525, 0.052631578947368418, 0.052631578947368418, 0.10526315789473684] 0.5
其中看‘buying’这个单词,在分类为非侮辱性留言中出现了0次,在侮辱性留言中出现了1次,所以概率分别为0和0.052631578947368418,计算正确。侮辱性留言出现的概率为0.5也计算正确。
接下来我们就进入最激动人心的环节——预测一条留言的分类。在预测之前我们还要解决两个小问题。大家有没有发现P(wi|ci)的值有许多是0,当进行多个P(wi|ci)相乘时,只要有一个是0,则结果为0。为了降低这种影响,我们可以把所有词出现的次数初始化为1,把分母初始化为2。
pw0 = np.ones(WordNum) #非侮辱性中词汇表各单词出现的次数 pw1 = np.ones(WordNum) #侮辱性中词汇表各单词出现的次数 p0Num = 2 #非侮辱性的单词个数 p1Num = 2 #侮辱性的单词个数
还有一个小问题就是P(wi|ci)的值一般都比较小,当多个较小的数相乘时可能出现下溢出情况。为了解决这个问题,可以采用取对数法。log(P(w1|ci)*P(w2|ci)、...、*P(wn|ci)) = log(P(w1|ci)) + log(P(w2|ci)) + ...+log(P(wn|ci))。取对数法不仅可以避免下溢出问题,并且对预测的结果不会有影响,这是因为取对数后的值和原先的值同变化。具体可参照下图。
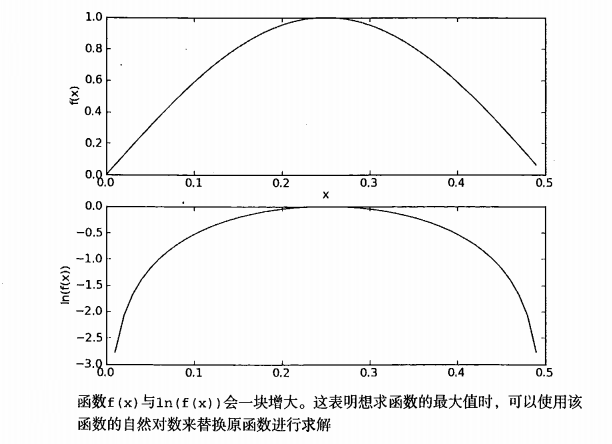
取对数法的Python代码如下。
pw0 = np.log(pw0 / float(p0Num)) pw1 = np.log(pw1 / float(p1Num))
好了,解决了两个小问题,下面我们就来预测一条留言的分类。由于留言分类只有两种,并且P(w)的值相同,故我们只要比较P(w|c0)*P(c0)和P(w|c1)*P(c1)的大小。根据取对数法,只要比较log(P(w|c0)*P(c0))和log(P(w|c1)*P(c1))的大小即可。log(P(w|c0)*P(c0)) = log(P(w1|c0)) + log(P(w2|c0)) + ...+log(P(wn|c0)) +log(P(c0)),log(P(w|c1)*P(c1)) = log(P(w1|c1)) + log(P(w2|c1)) + ...+log(P(wn|c1)) +log(P(c1))。
分类器的Python代码如下。
'''
求留言的分类
参数:inputVec 留言的标志数组
'''
def bayesClass(inputVec, pw0,pw1,class1Probability):
pr1 = sum(inputVec * pw1) + np.log(class1Probability)
pr0 = sum(inputVec * pw0) + np.log(1 - class1Probability)
if pr1>pr0:
return 1
else:
return 0
最后我们用两条留言测试一下,这两条留言的单词分别为 'love', 'my', 'dalmation' 和 'stupid', 'garbage'。
#测试
messageList , messageClss = loadDataSet()
vocaList = createVocaList(messageList)
messageFlag = []
for message in messageList:
messageFlag.append(messageToFlag(vocaList,message))
p0, p1, c1 = calcuProbability(messageFlag,messageClss)
testMessage1 = ['love', 'my', 'dalmation']
message1Flag = messageToFlag(vocaList,testMessage1)
print(testMessage1 , ' 的分类为' , bayesClass(message1Flag,p0,p1,c1))
testMessage2 = ['stupid', 'garbage']
message2Flag = messageToFlag(vocaList,testMessage2)
print(testMessage2 , ' 的分类为' , bayesClass(message2Flag,p0,p1,c1))
结果如下。
['love', 'my', 'dalmation'] 的分类为 0 ['stupid', 'garbage'] 的分类为 1
好了,到此,一个简单的朴素贝叶斯分类器完成了,有任何疑惑或指教请后台联系小编。
获取更多干货请关注微信公众号:追梦程序员。
