马尔可夫模型
一个长度为N的序列 N 1 , N 2 , N 3 , . . . N N N_{1}, N_{2}, N_{3},...N_{N} N1,N2,N3,...NN,每个位置有k种可能的状态 S j ( 1 < = j < = k ) S_{j}(1<=j<=k) Sj(1<=j<=k),第t个位置的状态 q t q_{t} qt 取决于前t个位置的状态,概率表示为 p ( q t = S j ∣ q t − 1 = S i , q t − 2 = S k , . . . ) p(q_{t}=S_{j}|q_{t-1}=S_{i},q_{t-2}=S_{k},... ) p(qt=Sj∣qt−1=Si,qt−2=Sk,...)
例如天气的序列,晴朗,多云,阴天,雨天,晴朗。第n+1天的天气状态依赖于前n天的状态,该随机过程就是马尔可夫模型
隐马尔可夫模型
在马尔可夫模型中,每个状态代表了一种可观测事件,隐马尔可夫模型包含了一个与其对应的不可观测的隐藏状态。
例如有3个骰子,一个骰子有四个面称为D4,一个有6个面称为D6,还有一个有8个面称为D8。我们随机选择骰子投掷6次得到一个长度为6的序列,假设是 5,1,3,7,4,6。这是一个可观测序列,在隐马尔可夫模型中还有一个隐藏序列,在这个例子中可以是你每次选中的骰子序列,D6,D4,D4,D8,D6,D6,这个序列并不唯一,我们要做的就是找到联合概率最大的这么一个隐藏序列。
隐马尔科夫模型需要确定三个概率矩阵(概率值均用已有数据的频率代替)。
1.初始状态概率矩阵,所有统计序列第一个位置的状态的分布概率。通常记为 π = ( π 1 , π 2 , . . . , π k ) \pi=(\pi _{1},\pi _{2},...,\pi _{k}) π=(π1,π2,...,πk), π i \pi _{i} πi表示初始状态为 S i S _{i} Si的概率。
2.状态转移概率矩阵A,其中 a i j a_{ij} aij是该矩阵的第i行第j列,表示某一时刻状态是 S i S_{i} Si其下一状态是 S j S_{j} Sj的概率,即状态 S i S_{i} Si转向状态 S j S_{j} Sj的概率。
3.输出观测概率矩阵B,各个隐藏状态下每个观测值的概率 B i j B_{ij} Bij,表示第i个隐藏状态下第j种观测值的概率。(不好理解没关系,后边有分词的例子,就会很好理解~)
根据已有数据可以统计出这三个矩阵,即确定了一个HMM模型,就可以根据一个观测序列推测出其最大概率的隐藏序列。
HMM解决中文分词任务
中文分词任务就是给定一句汉语,将其中的词语分割开来。HMM其实也可以和分词任务联系起来,HMM中有一个隐藏序列,其实中文句子也可以给他设置一个隐藏序列,来表示分好词的结果。每个字对应一个隐藏状态,B代表这是一个词的开始位置,M代表这是一个词的中间位置(即不是开头也不是结尾),E代表这是一个词的结束位置,S代表这个字单独成词。例如:
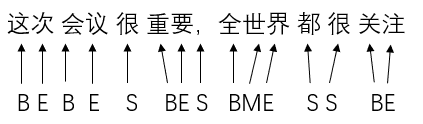
每一个字对应一个隐藏状态,利用HMM模型,根据给出的句子,得到其隐藏状态,显而易见,在隐藏状态是S和E的后边加上空格,则完成了分词任务。接下来讨论如何构建HMM模型。
首先需要有分好词的数据,例如这种格式的:

需要此数据集的私聊我,当然你也可以使用其他数据集。根据分好词的数据,生成与其对应的隐藏状态序列,例如这种:
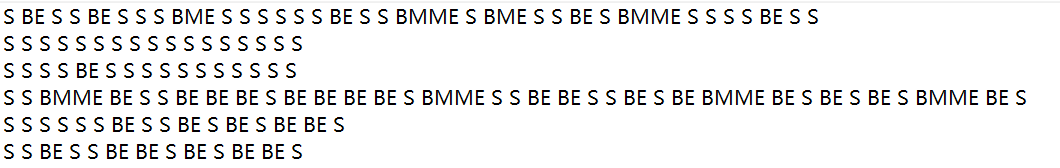
首先我们需要生成三个概率矩阵,初始矩阵,转移矩阵与发射矩阵,对应上述HMM模型介绍时的三个概率矩阵。
1.初始矩阵 π \pi π,就是所有统计数据的隐藏状态的最开始位置的一个概率分布情况,显然每个隐藏状态的开始位置状态只能是B或者S,例如总共就十条数据,有八条数据隐藏状态是以B开头的,有两条数据是以S开头的,则初始矩阵为[B:0.8,S:0.2,M:0,E:0]
2.转移矩阵A,就是有某个状态转移到另一个状态的一个概率矩阵,假设BMES状态对应的索引是B:0 M:1 S:2 E:3,遍历每一行数据,假设某一个数据为(S BE SS BE),S后边接了一个B,则转移矩阵中 A 20 A_{20} A20就需要+1,B矩阵所有位置均初始化为0,继续往后遍历,B后边接了一个E,则 A 03 A_{03} A03就需要+1,一直往后遍历,直到遍历完所有统计数据。最终的A矩阵, A i j A_{ij} Aij代表第i个状态转移到第j个状态的概率(用统计数据频率代替概率)
3.发射矩阵B,就是在每一个状态下,每一个字的概率。如同一个字,可能会在不同句子中对应隐藏状态不同,例如"天"这个字,“今天”,“天就对应的是E”,“天气”,"天"对应的就是B,对于某一个特定状态,比如B,在B状态对应的文字中,“我”这个字出现了3次,"你"这个字出现了2次,"他"这个字出现了5次,假设只出现了这三个字,则{B:{“我”:0.3,“你”:0.2,“他”:0.5},M:{…},S:{…},E:{…}},其他状态计算方式相同。则就得到了发射矩阵。
根据训练数据得到这三个矩阵,则训练完成
得到这三个矩阵后,我们就可以根据一个输入的句子,得到它的隐藏状态了。接下来详细介绍如何计算。
给定一个句子"今天天气真好",共六个字,对应六个隐藏状态,其隐藏状态序列的所有可能的结果共有 4 6 4^{6} 46种(4种状态,6个位置),我们可以计算这 4 6 4^{6} 46种结果的可能概率,选取概率最大的那个当作隐藏状态。那么如何计算呢?就要用到前边算出的三个矩阵。
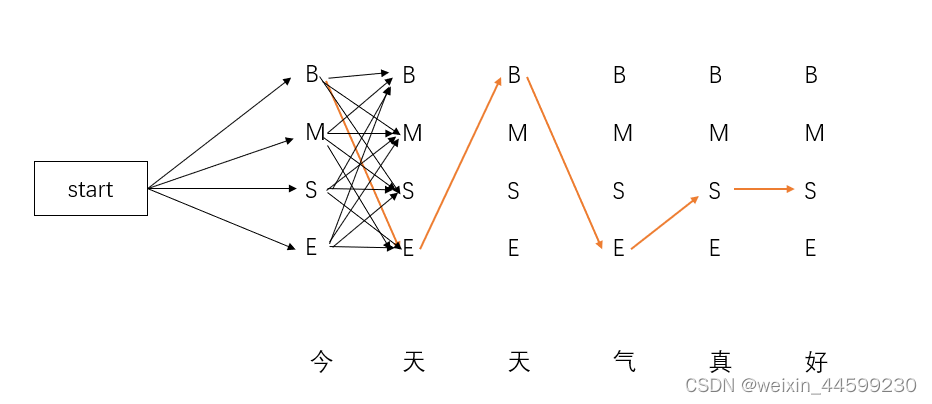
图中每两层之间都是全连接的,只画出了第一层与第二层之间的连接,后边就省略了。总共有 4 6 4^{6} 46个路径,计算出每条路径的概率即可。举个例子,计算图中红色箭头这条路径的概率,首先计算第一个状态是B的概率,就是初始矩阵中状态B的概率,然后下一个状态是E,然后找出转移矩阵中B转移到E的概率,然后找出发射矩阵中B状态下"今"这个字的概率,将这三个概率相乘就是BE的概率,后边还有路径没走完,还需继续连乘,接下来E后边是B,就需要再乘以转移矩阵中E转向B的概率,再乘以发射矩阵中E状态下"天"的概率,依次往后计算,到最后一个状态S,到此就计算完成这一条路径的联合概率,当计算完所有路径的概率后,就可以选择一个最优的路径。但是当句子长度变长后路径数会指数增加,计算效率低下,可以使用Viterbi算法来简化计算过程。
Viterbi(维特比)算法
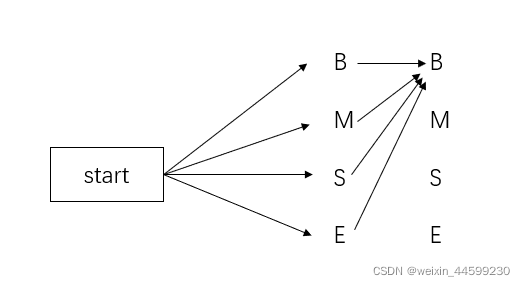
如图中所示,第二个状态是B,总共有四条路径到达这里,在当前时刻,就可以计算出一个最优概率,将其他三条路径舍弃。当然第二个状态是M,前边也有四条路径,也可以计算出一个最优的,舍弃其他三条路径。第二层舍弃完之后如下图
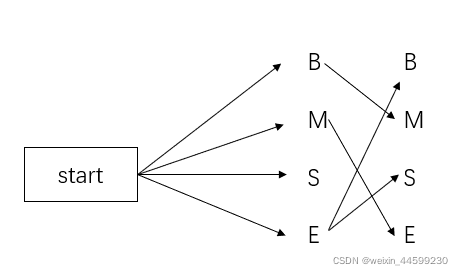
继续向后计算,第三个状态是B,前边又会有从第二层引过来的四条线
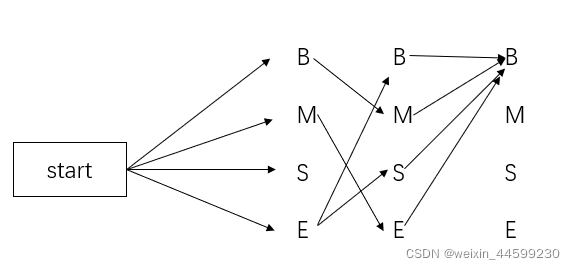
计算这四条路径中的最优路径时,不仅仅只考虑第二层到第三层,例如第二层B到第三层B的这条路径,不仅仅只计算第二层的,还需考虑第一层的状态,第二层的B是由第一层的E过来的,则需计算EBB的概率,考虑第二层M到第三层B的时候,第二层的M是由第一层的B来的,则需计算BMB的概率,这样计算完四条路经的概率后选取一个最优的路线,假设计算完之后如下图所示

依次往后计算,直到最后一层,也是如此计算,倒数第二层到最后一层,也是只剩下四条线,最终只需计算这四条线(这四条线需要与前边的状态连接一同计算联合概率)的一个概率,选择一个最优路径,比如计算出倒数第二层B到最后一层E的概率最大,由倒数第二层的B往前推,可以唯一确定一条路径,这条路径就是最终隐藏状态。假设某个句子就四个字,最终的路径图可以如图所示

得到该句子的隐藏状态,在隐藏状态是E和S的后边加上一个空格,分词任务就完成了。
python代码实现HMM
import pickle
from tqdm import tqdm
import numpy as np
import os
def make_label(text_str): # 从单词到label的转换, 如: 今天 ----> BE 麻辣肥牛: ---> BMME 的 ---> S
text_len = len(text_str)
if text_len == 1:
return "S"
return "B" + "M" * (text_len - 2) + "E" # 除了开头是 B, 结尾是 E,中间都是M
def text_to_state(file="all_train_text.txt"): # 将原始的语料库转换为 对应的状态文件
if os.path.exists("all_train_state.txt"): # 如果存在该文件, 就直接退出
return
all_data = open(file, "r", encoding="utf-8").read().split("\n") # 打开文件并按行切分到 all_data 中 , all_data 是一个list
with open("all_train_state.txt", "w", encoding="utf-8") as f: # 代开写入的文件
for d_index, data in tqdm(enumerate(all_data)): # 逐行 遍历 , tqdm 是进度条提示 , data 是一篇文章, 有可能为空
if data: # 如果 data 不为空
state_ = ""
for w in data.split(" "): # 当前 文章按照空格切分, w是文章中的一个词语
if w: # 如果 w 不为空
state_ = state_ + make_label(w) + " " # 制作单个词语的label
if d_index != len(all_data) - 1: # 最后一行不要加 "\n" 其他行都加 "\n"
state_ = state_.strip() + "\n" # 每一行都去掉 最后的空格
f.write(state_) # 写入文件, state_ 是一个字符串
# 定义 HMM类, 其实最关键的就是三大矩阵
class HMM:
def __init__(self,file_text = "all_train_text.txt",file_state = "all_train_state.txt"):
self.all_states = open(file_state, "r", encoding="utf-8").read().split("\n")[:200] # 按行获取所有的状态
self.all_texts = open(file_text, "r", encoding="utf-8").read().split("\n")[:200] # 按行获取所有的文本
self.states_to_index = {
"B": 0, "M": 1, "S": 2, "E": 3} # 给每个状态定义一个索引, 以后可以根据状态获取索引
self.index_to_states = ["B", "M", "S", "E"] # 根据索引获取对应状态
self.len_states = len(self.states_to_index) # 状态长度 : 这里是4
self.init_matrix = np.zeros((self.len_states)) # 初始矩阵 : 1 * 4 , 对应的是 BMSE
self.transfer_matrix = np.zeros((self.len_states, self.len_states)) # 转移状态矩阵: 4 * 4 ,
# 发射矩阵, 使用的 2级 字典嵌套
# # 注意这里初始化了一个 total 键 , 存储当前状态出现的总次数, 为了后面的归一化使用
self.emit_matrix = {
"B":{
"total":0}, "M":{
"total":0}, "S":{
"total":0}, "E":{
"total":0}}
# 计算 初始矩阵
def cal_init_matrix(self, state):
self.init_matrix[self.states_to_index[state[0]]] += 1 # BMSE 四种状态, 对应状态出现 1次 就 +1
# 计算转移矩阵
def cal_transfer_matrix(self, states):
sta_join = "".join(states) # 状态转移 从当前状态转移到后一状态, 即 从 sta1 每一元素转移到 sta2 中
sta1 = sta_join[:-1]
sta2 = sta_join[1:]
for s1, s2 in zip(sta1, sta2): # 同时遍历 s1 , s2
self.transfer_matrix[self.states_to_index[s1],self.states_to_index[s2]] += 1
# 计算发射矩阵
def cal_emit_matrix(self, words, states):
for word, state in zip("".join(words), "".join(states)): # 先把words 和 states 拼接起来再遍历, 因为中间有空格
self.emit_matrix[state][word] = self.emit_matrix[state].get(word,0) + 1
self.emit_matrix[state]["total"] += 1 # 注意这里多添加了一个 total 键 , 存储当前状态出现的总次数, 为了后面的归一化使用
# 将矩阵归一化
def normalize(self):
self.init_matrix = self.init_matrix/np.sum(self.init_matrix)
self.transfer_matrix = self.transfer_matrix/np.sum(self.transfer_matrix,axis = 1,keepdims = True)
self.emit_matrix = {
state:{
word:t/word_times["total"]*1000 for word,t in word_times.items() if word != "total"} for state,word_times in self.emit_matrix.items()}
# 训练开始, 其实就是3个矩阵的求解过程
def train(self):
if os.path.exists("three_matrix.pkl"): # 如果已经存在参数了 就不训练了
self.init_matrix, self.transfer_matrix, self.emit_matrix = pickle.load(open("three_matrix.pkl","rb"))
return
for words, states in tqdm(zip(self.all_texts, self.all_states)): # 按行读取文件, 调用3个矩阵的求解函数
words = words.split(" ") # 在文件中 都是按照空格切分的
states = states.split(" ")
self.cal_init_matrix(states[0]) # 计算三大矩阵
self.cal_transfer_matrix(states)
self.cal_emit_matrix(words, states)
self.normalize() # 矩阵求完之后进行归一化
pickle.dump([self.init_matrix, self.transfer_matrix, self.emit_matrix], open("three_matrix.pkl", "wb")) # 保存参数
def viterbi_t( text, hmm):
states = hmm.index_to_states
emit_p = hmm.emit_matrix
trans_p = hmm.transfer_matrix
start_p = hmm.init_matrix
V = [{
}] #记录某时刻在某个状态结束的一个联合概率
path = {
} #记录当前最优的路径 path[y]表示以y结束的路径
#先考虑第一个位置
for y in states:
V[0][y] = start_p[hmm.states_to_index[y]] * emit_p[y].get(text[0], 0)
path[y] = [y]
for t in range(1, len(text)):
V.append({
})
newpath = {
}
# 检验训练的发射概率矩阵中是否有该字
neverSeen = text[t] not in emit_p['S'].keys() and \
text[t] not in emit_p['M'].keys() and \
text[t] not in emit_p['E'].keys() and \
text[t] not in emit_p['B'].keys()
for y in states:
emitP = emit_p[y].get(text[t], 0) if not neverSeen else 1.0 # 设置未知字单独成词
temp = []
for y0 in states:
if V[t - 1][y0] > 0:
temp.append((V[t - 1][y0] * trans_p[hmm.states_to_index[y0],hmm.states_to_index[y]] * emitP, y0))
(prob, state) = max(temp)
V[t][y] = prob
newpath[y] = path[state] + [y]
path = newpath
(prob, state) = max([(V[len(text) - 1][y], y) for y in states]) # 求最大概念的路径
result = "" # 拼接结果
for t,s in zip(text,path[state]):
result += t
if s == "S" or s == "E" : # 如果是 S 或者 E 就在后面添加空格
result += " "
return result
if __name__ == "__main__":
text_to_state()
text = "虽然一路上队伍里肃静无声"
hmm = HMM()
hmm.train()
result = viterbi_t(text,hmm)
print(result)