paper: Mask-Free Video Instance Segmentation
github
一般模型学instance segmentation都是要有mask标注的,
不过mask标注既耗时又枯燥,所以paper中仅用目标框的标注来实现实例分割。
主要针对视频的实例分割。
之前也有box-supervised实例分割,不过是针对图像的,用在视频中精度不是很高,
作者分析视频的特点是图像是连续的,那就是说同一目标区域在连续的帧中应该属于一个mask label.
理论是时间连续性,一个视频是由多个图片组成的连续的画面,目标的变化也是渐变的。
t+1时刻的帧 与 t时刻对应的区域,像素如果属于同一目标或者背景,那么就应该有相同的mask.
这种找连续画面的对应区域,流行的是用光流法。
不过光流法面临2个问题:
1.不稳定,在有遮挡(找不到),没有明显的纹理(未定义),或者是只有一个边缘(模棱两可)时。
2. SOTA光流法用了深度网络,计算量内存量很大。
paper中定义了temporal KNN-patch loss(TK-loss)
简要介绍一下TK-loss,对于每一个目标patch, 在相邻帧找到matching score最高的前K个匹配。
对K个匹配都计算loss。
和光流法的区别是,光流法是1对1匹配,而TK-loss是1对K匹配。
K可以是0,比如遮挡的情况,也可以是K>=2, 比如天空,地面这种纹理不丰富的情况。
当K>=2时,可能多个patch都属于同一目标或者背景。
此方法计算量不大,而且没有需要学习的参数。
计算TK-loss有4个步骤,如下图
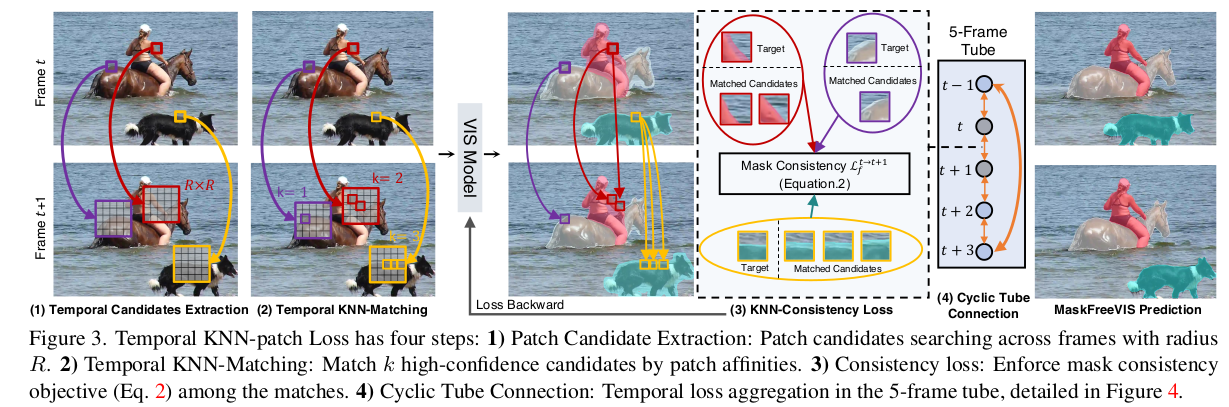
步骤1:
候选patch。
一个N * N的patch, 假设它的中心点坐标为p=(x, y), X p t X_{p}^t Xpt表示第 t 帧以p为中心点的N * N patch.
现要找到 t ^ \hat{t} t^ 帧与 X p t X_{p}^t Xpt对应的patch(中心点) 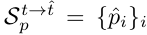
中心点的位置可在以p为中心,半径R内的区域选取(有点像模板匹配中的local search),
加速措施的所有target image同时做这个窗口搜索。
步骤2:
K个匹配。
匹配肯定要计算距离,paper中用的是L2距离,
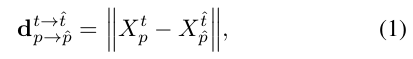
选取距离最小的K个匹配。
这K个匹配里面可能还有距离不够小的,这时用一个阈值再过滤一次,把距离>=阈值D的过滤掉。
剩下的就是要求的

步骤3:
一致性loss。
当匹配的patch不属于一个mask时,就会带来损失。
令 M p t M_{p}^t Mpt为预测的二值mask值(0,1), 位置p, 第 t 帧。
如果(p,t) 与它的对应patch 不一致,就会有loss.
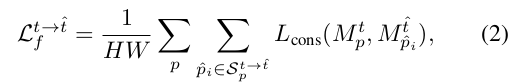
其中
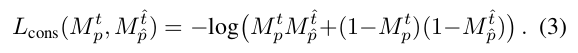
可以看出,在匹配点的mask值都是0或都是1时,log里面是1,整体的loss是0,也就是说匹配点一致时不会带来损失。
步骤4:
Cyclic Tube连接
tube是指包含了一个时间序列的帧数的管道,设有T帧。
每次要计算一个tube里面所有帧的loss. 用循环(cyclic)的方式。
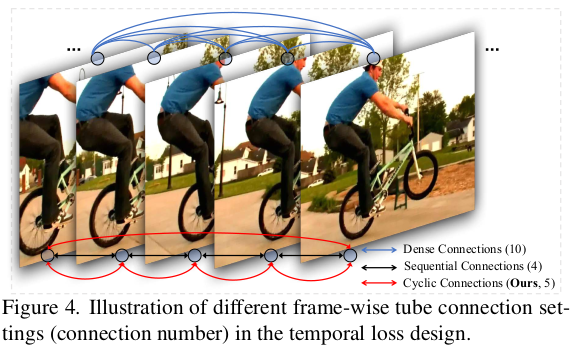
这里一个时间通道用5帧,shuffle过。
蓝色表示两两帧之间都计算loss。
红色是cyclic连接,最后一帧和第一帧计算loss, 其他的计算相邻帧的loss.
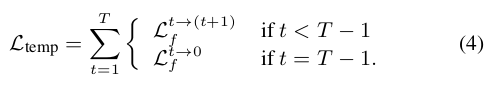
训练
以往的实例分割训练都需要mask的标注,paper中不用mask标注,只用box 标注。
那么就不能像计算mask loss那样用到预测mask和gt mask.
作者用了BoxInst中的两个损失函数来替代mask loss.
box映射损失 L p r o j L_{proj} Lproj和相邻像素的损失 L p a i r L_{pair} Lpair.
其中映射损失为

用的是dice loss, 因为作者发现cross-entropy会导致大的object损失比小的object要大。
这里计算loss时忽略标签。
相邻像素的损失 L p a i r L_{pair} Lpair主要依据是认为同一帧颜色相近的相邻像素应该属于同一物体。
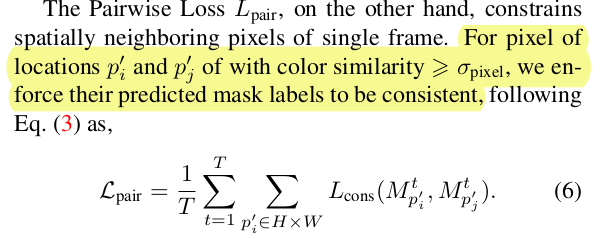
不过一张图像上那么多点,公式上看pi是属于目标框内的点,不过pj怎么选呢,这里没说。
BoxInst中指出是周围的8个点(要间隔一个点)。

BoxInst中loss就是简单地把2者结合起来:
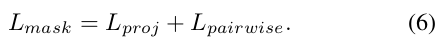
而paper中作者加了一个权重,得到空间loss:
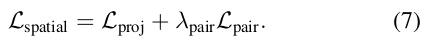
还有一个时间上的loss, 就是前面提到的TK-loss. 把空间loss和时间loss结合起来得到最终的损失函数:
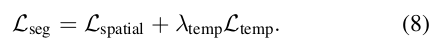
回忆一下TK-loss L t e m p L_{temp} Ltemp,
取T帧的时间通道,计算相邻两帧的loss, 最后一帧和第一帧计算loss.
loss如下:
遍历一帧图像内所有点,设其中一点为p,找半径R范围内的点作为匹配点的候补,以每个点为中心求N * N patch的L2距离。
找到前K个距离最小的候补点,去掉距离<D的候补点,剩下的就是匹配点。
然后计算匹配点的mask是否一致。
一帧所有的点算完后,按cyclic的顺序计算一个时间通道内所有帧的loss叠加.
L t e m p L_{temp} Ltemp的算法流程如下:

总结
把实例分割方法中的mask loss替换成paper中的 L s e g L_{seg} Lseg,就能实现只有box标注下的video实例分割。
所以,认为本文其实是改进了BoxInst损失函数,考虑video图片连续性的特点,在BoxInst的基础上加上了时间损失 L t e m p L_{temp} Ltemp。
paper中的时间损失 L t e m p L_{temp} Ltemp是针对video场景的 ,如果单纯是图片的实例分割,图片没有连续性,就不适用。
实验数据参照paper