目录
一、写入
1.1 安装 xlwt
安装指令:pip install xlwt
安装完成,导入xlwt后,xlwt中有一个函数,Workbook()
Workbook()函数以变量进行储存
rt xlwt
excel = xlwt.Workbook()1.2 增加sheet页
1.2.1 新建sheet页
excel.add_sheet(参数1,参数2)
参数1:sheet页名称
参数2:是否允许覆盖,默认为false(可不写)
# excel.add_sheet("login") # 登录sheet页
# 并把该sheet页赋值给一个变量
sheet = excel.add_sheet("login")此时,需要往sheet页中写入内容
1.2.2 sheet页写入数据
存储sheet页的变量.write(行,列,内容)
行和列的序号从 0 开始
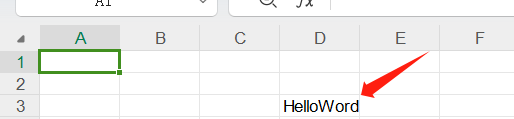
例如:在第二行第三列的单元格中输入 HelloWord
excel.write(2,3,"HelloWord") # 这是错误的写法,会报错没有这个write方法
sheet.write(2,3,"HelloWord")在完成写入后,需要对excel进行保存
1.2.3 excel保存
excel.save(参数1)
参数1:保存的文件路径,确定到文件名,路径为绝对路径
excel文件的后缀有两个格式:xls、xlsx
excel.save("D:/Test/test01.xlsx")这里创建一个excel表格在D盘Test目录下,把上面sheet页的数据写入到该表格中
1.2.4 完整代码
# coding=utf-8
import xlwt
excel = xlwt.Workbook()
sheet = excel.add_sheet("login")
sheet.write(2, 3, "HelloWord") # 序号从0开始
excel.save("D:/Test/test01.xlsx")
1.2.5 同一坐标,重复写入
如果在第二行第三列的位置中,再次进行一次输入
sheet.write(2, 3, "HelloWord")
sheet.write(2, 3, "Python")那么则会出现一个单元格覆盖错误的问题,以及单元格的覆盖写入是否OK
如果需要允许覆盖写入,就需要在sheet页后面,添加允许覆盖写入的参数
sheet页变量 = excel.add_sheet("sheet页名",cell_overwrite_ok=true)
sheet = excel.add_sheet("login", cell_overwrite_ok=True)完整代码
sheet = excel.add_sheet("login", cell_overwrite_ok=True)
sheet.write(2, 3, "HelloWord")
sheet.write(2, 3, "Python")
二、读取
2.1 安装读取模块
执行指令:pip install xlrd
安装完xlrd后,需要进行导入,然后进行读取文件
import xlrd
xlrd.open_workbook("读取的文件名称")文件的名称可以用变量进行存储
import xlrd
filename = "D:/Test/test01.xlsx"
excel = xlrd.open_workbook(filename)2.2 读取sheet页
读取sheet页,可以通过名称和序号进行读取,但是建议通过名称进行读取,序号可能会因其他原因发生改变
2.2.1 序号读取shee页
序号读取语法:excel.sheet_by_index(序号)
序号从0开始
可以测试打印一下
# 读取sheet页
sheet = excel.sheet_by_index(1)
print(sheet)运行,发生报错:list index out of range
报错:我提供的序号已经超出了这个sheet的序号
打开写操作的excel表,底部是只有一个sheet

那么,序号应该是从 0 开始
sheet = excel.sheet_by_index(0)
print(sheet)打印结果:Sheet 0:
2.2.2 通过sheet页的名称读取sheet页
语法:excel.sheet_by_name("sheet名")
# 通过名称的方式获取sheet页
sheet = excel.sheet_by_name("login")
print(sheet)
# 打印结果:Sheet 0:<login>2.2.3 打印出表格中数据最远的行数和列数

2.2.3.1 打印最远行数
执行语句:sheet.nrows
# 通过名称的方式获取sheet页
sheet = excel.sheet_by_name("login")
print(sheet.nrows) # 第八行此处的行和列则从1开始
2.2.3.2 打印列数(用得不多)
语法:sheet.ncols
sheet = excel.sheet_by_name("login")
print(sheet.ncols) # 52.2.4 循环获取行的数据
循环的范围是:sheet.nrows
函数
1、sheet.row_values(i):获取每一行的值,每一次随着i的值发生变化,读取到的数据被list类型存储
执行循环,并把sheet.row_values(i)获取到的数据存入变量rv中
打印值和type
nr = sheet.nrows
for i in range(nr): # 8行循环八次
# 每次循环,拿到一行的数据
rv = sheet.row_values(i)
print(rv, type(rv))
"""
['', '', '', '', ''] <class 'list'>
['', '', '', '', ''] <class 'list'>
['', '', '', 'Python', ''] <class 'list'>
['', '', '', '', ''] <class 'list'>
['', '', '', 'Hello', 'Vue'] <class 'list'>
['', '', '', '', ''] <class 'list'>
['', '', '', '', ''] <class 'list'>
['', 'World', '', '', ''] <class 'list'>
""" 如果表单元格中,有数字存在,则修改为文本格式,右键-->单元格格式-->文本-->确定
手机号、数值、日期等也excek中转为文本类型
↑以上内容为单行读取
↓行内单独提取索引值
在上述内容中,通过循环sheet页的最大值,获取到每一行的数据,此时,也可以直接去通过索引赋值
nr = sheet.nrows
for i in range(nr): # 8行循环八次
# 每次循环,拿到一行的数据
rv = sheet.row_values(i)
a, b, c, d, e = rv[0], rv[1], rv[2], rv[3], rv[4]
print(f"{a},{b},{c},{d},{e}")
"""
,,,,
,,,,
,,,Python,
,,,,
,,,Hello,Vue
,,,,
,,,,
,World,,,
""" 三、修改
3.1 安装修改模块
指令:pip install xlutils
导入修改的模块
from xlutils.copy import copy
# 导入的是xlutils中的copy模块要进行修改模块,就需要先读取,再修改
再添加读取模块
# 1、导入修改模块
from xlutils.copy import copy
# 2、导入读取模块,读取文件
import xlrd
filename = "D:/Test/test01.xlsx"
excel = xlrd.open_workbook(filename)而要进行的修改操作,是把原有的sheet页进行copy后,再新的表进行修改
3.2 copy读取到的sheet页并修改

# 复制
new_excel = copy(excel)
# 读取到修改以后的excel,赋值到新的变量去修改内容
sheet = new_excel.get_sheet(0)
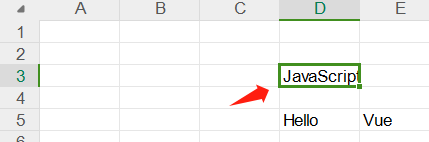
# 在获取到的序列写入新的内容(修改Python的值)
sheet.write(2, 3, "JavaScript")
# 保存,以新的excel保存
# 如果是原地址,则是保存,否则是另存为
new_excel.save("D:/Test/test02.xlsx")如果保存的路径是其他的,则会另存为一个新的