1. 核心原理介绍
3个关键点:
- 距离量度
- k值选择
- 分类决策规则
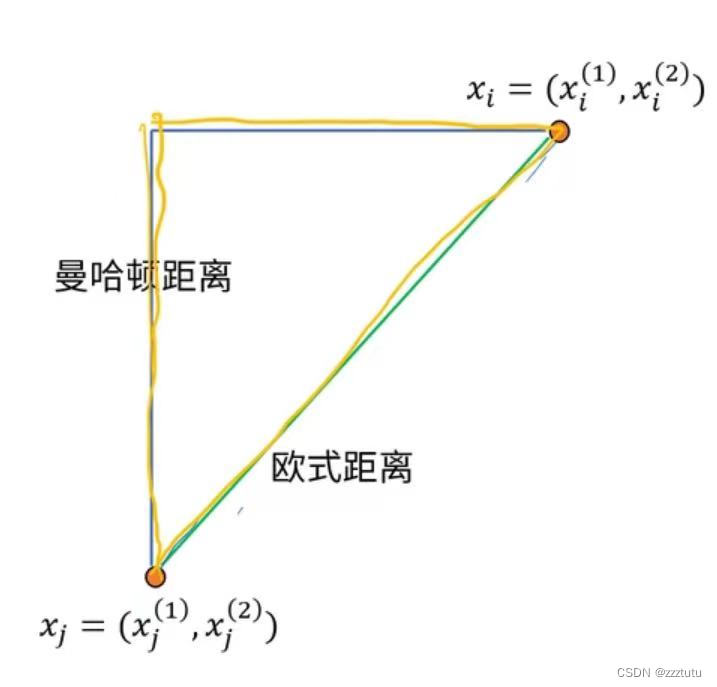
1.1 距离量度
首先提出p范数概念:
令
,
p范数:
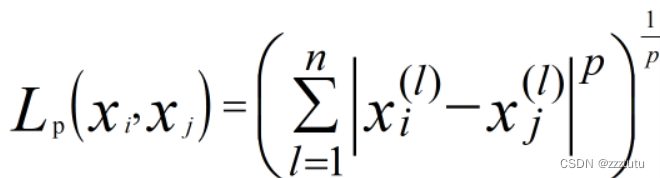
(1)欧式距离(二范数)
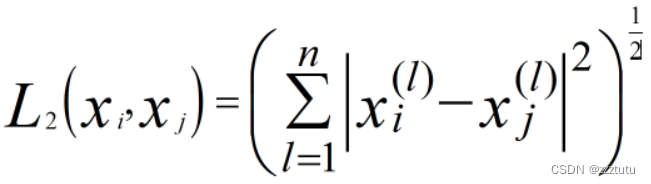
(2)曼哈顿距离(一范数)
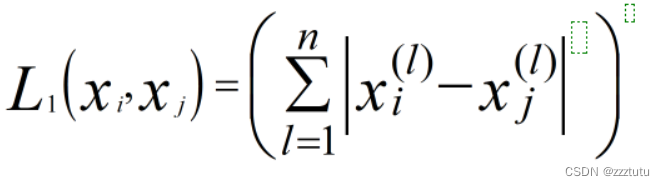
1.2 k值选择
- 选择较小的k值
用较小的邻域进行预测。预测结果对邻近的实例点非常敏感。如果邻近的实例点恰好是噪声,预测就会出错。
- 选择较大的k值
用较大的邻域进行预测。对于输入实例较远的(已经不太相似)的样本点也会对预测起作用,使预测发生错误。
- 在应用中
先选取一个较小的k值,再通过交叉验证法来选取最有的k值。
1.3 分类决策规则:多数表决
提出损失函数概念 :
其中I为指示函数:
2. 算法流程总结
输入:训练数据集 ,x为实例特征向量
1. 根据给定的距离度量,在训练集中找到与x最近的k个点,涵盖这k个点的邻记作
2.在中根据分类决策规则(如:多数表决)决定x的类别y
输出:实例x所属的类别y
3. knn与k-means区别
| knn(K-NearestNeighbor) | k-means(k-means clustering algorithm) |
| 监督学习 | 非监督学习 |
| 类别已知 | 类别未知 |
| 作用:分类 | 作用:聚类 |
4. knn利用python实现
这里本人是学习的刘建平老师的博客和github仓库
地址:https://github.com/ljpzzz/machinelearning

import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
from sklearn.datasets.samples_generator import make_classification
# 从sklearn中的自带的数据库【sklearn.datasets.samples_generator】导入分类数据生成器【make_classification】
# X为样本特征,Y为样本类别输出, 共1000个样本,每个样本2个特征,没有冗余特征,每个类别一个簇,输出有3个类别
X, Y = make_classification(n_samples=1000, n_features=2, n_redundant=0,
n_clusters_per_class=1, n_classes=3)
#X的第一列和第二列;【marker】为数据点样式;【c】为色彩序列
plt.scatter(X[:, 0], X[:, 1], marker='.', c=Y)#散点图【scatter】
plt.show()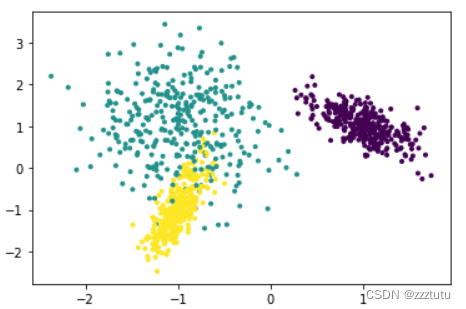
#使用KNN来拟合模型
from sklearn import neighbors#关于近邻法的类库都在【sklearn.neighbors】
#这里选择K=15,权重为距离远近
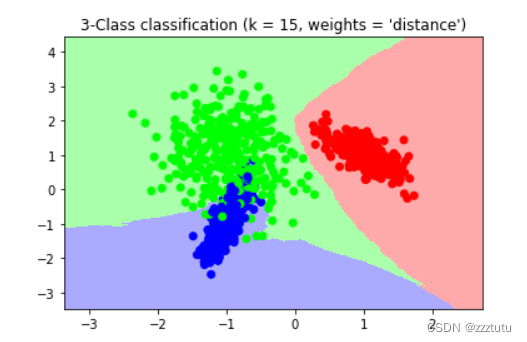
clf = neighbors.KNeighborsClassifier(n_neighbors = 15 , weights='distance')#KNN分类树【KNeighborsClassifier】
#KNN中的K值【n_neighbors】;权重【weights】:可选【"uniform"or"distance"】,unifor表示所有最近邻样本权重都一样,distance表示权重和距离成反比
clf.fit(X, Y)from matplotlib.colors import ListedColormap
#定义颜色库:浅色库、深色库
cmap_light = ListedColormap(['#FFAAAA', '#AAFFAA', '#AAAAFF'])#(#ffaaaa由100.0%红色,66.67%绿色和66.67%蓝色组成,RGB(255,170,170)
cmap_bold = ListedColormap(['#FF0000', '#00FF00', '#0000FF'])#(纯红色FF0000,绿色#00FF00,纯蓝#0000FF
#确认训练集的边界
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1 #样本1边界
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1 #样本2边界
#生成随机数据来做测试集,然后作预测
#【mershgrid(x1,x2)】将数组扩展成一个矩阵,x1竖向扩展, x2横向扩展
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.02),
np.arange(y_min, y_max, 0.02))
#【ravel】将矩阵变为一个一维的数组,其中xx.ravel()就表示x轴(数据特征data_feature1),yy.ravel()就表示了y轴(数据特征data_feature2)
Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])
# 画出测试集数据
#【reshape(-1,8,8,1)】-1表示不知道,两个8表示8行8列,1表示一维空间
Z = Z.reshape(xx.shape) #将Z形状变为和xx一样
plt.figure()
#【pcolormesh(x,y,z,camp)】x,y为两个自变量(需要是适当的二维数组,形成矩形网格,用到前面的【mershgrid】);
#z是因变量,行索引对应y坐标,列索引对应x坐标。所以画图时,一般将计算好的z转置
#camp是颜色映射
plt.pcolormesh(xx, yy, Z, cmap=cmap_light)
# 也画出所有的训练集数据
plt.scatter(X[:, 0], X[:, 1], c=Y, cmap=cmap_bold)
#【xlim((left, right)) 】设置x轴边界
plt.xlim(xx.min(), xx.max())
plt.ylim(yy.min(), yy.max())
plt.title("3-Class classification (k = 15, weights = 'distance')" )