k近邻算法
k近邻算法基本描述
给定一个训练数据集,对新的输入实例,在训练数据集中找到与该实例最相近的k个实例,这k个实例的多数属于某个类,就把该输入实例分为这个类.

k近邻模型
该模型有三个基本要素:**距离度量,k值的选择,分类决策规则**.当这三个要素确定后,便能对于任何一个新的输入实例,给出唯一确定的分类.这里用图片说明更清楚,对于训练集中的每一个样本,距离该点比其他点更近的所有点组成一片区域,叫做单元.每个样本都拥有一个单元,所有样本的单元最终构成对整个特征空间的划分,且对每个样本而言,它的标签就是该单元内所有点的标记.这样每个单元的样本点的标签也就是唯一确定的.(我感觉这图片真的很形象)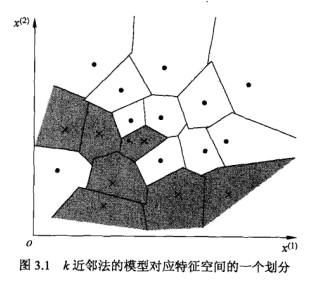
下面来简要说下这三个基本要素
1.距离度量
当然,一般都是用的欧式距离,但也应该了解还有那些距离度量方法:如lp距离:
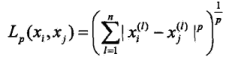
而欧式距离就是p=2时的特殊情况
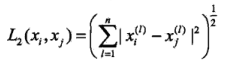
还有曼哈顿距离,即p=2时的lp距离
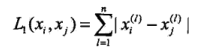
和p=无穷时,
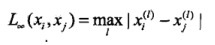
2.k值的选择
k值过小
近似误差减小,估计误差增大
易受噪声影响
易发生过拟合
k值过大
近似误差增大,估计误差减小
忽略有效信息
3.分类决策规则
最主要用的一般是多人表决,