摇一摇加好友功能
游戏中的好友系统通常会就有面对面添加好友的功能, 功能具体内容就是输入相同数字串进行搜索,就能搜索到一定时间内输入相同数字串的玩家。从理解上看功能描述较为简单,但具体的实现过程还是有很多需要注意的地方。
首先就是功能的整体结构, 可以采用中心化的方法, 对于发送了请求的玩家进行信息的存储, 全服所有玩家都把数据发送过来, 然后在中心节点上进行处理,最后处理结果发送玩家。该方法的好处是处理起来简单, 通信较少,保序性好,其具体的结构框架如图下图1所示:
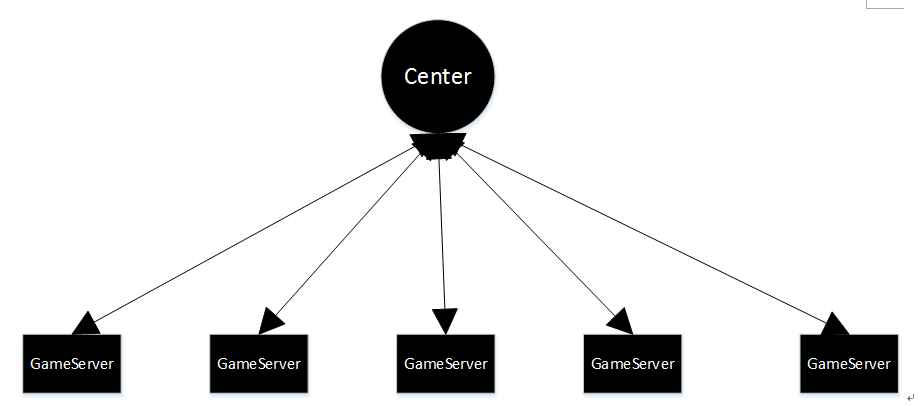
图1 中心化的实现方案
上述方案将玩家请求数据全部发送到中心节点由中心节点进行处理,中心节点将符合要求的玩家信息发送到对应的GameServer上,这样相对通信量较少, 数据集中, 实现起来也比较简单,但问题是对于中心节点的压力也是比较大的, 同时中心节点一旦出现问题整个功能都将失效。因此对于高可靠性来说可以尝试去中心化的实现方法,具体方案结构如下图2所示:
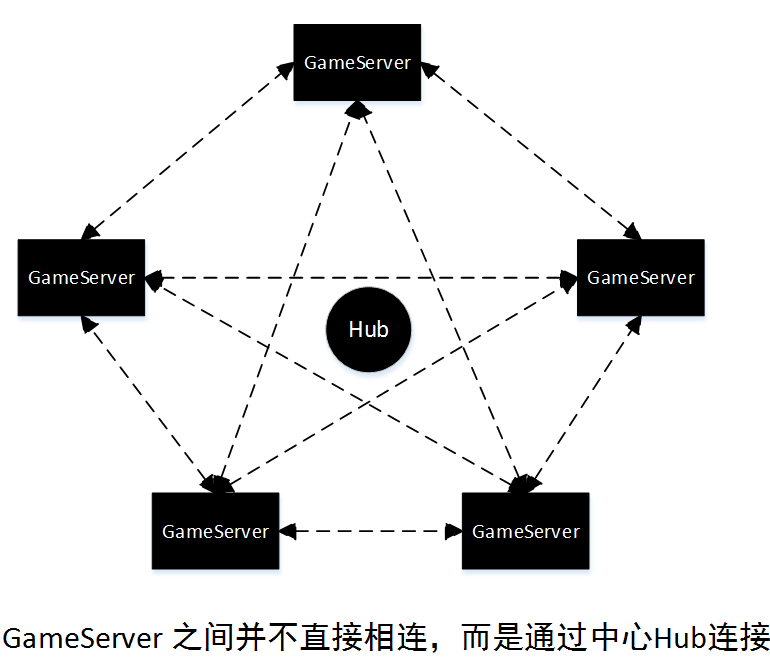
图2中可以看出每个GameServer都是一个中心, 本服的玩家将数据发送到该服务器某个进程, 然后该进程负责处理玩家的请求以及将数据发送到其它GameServer, 这样每个GameServer 都会拥有全服玩家的数据请求,那么在接受本地的玩家请求时就可以直接返回其全服玩家的数据,这种去中心化的方法将玩家的请求分散到各个服务器上,通过消息广播的方式进行全服数据的同步, 显然数据传输量较大, 也正是这种冗余的数据传输策略使得整个服务器集群的任何节点掉线都不至于影响到该功能的正常运行, 同时也分摊的中心化节点的压力提高了运行效率。
去中心化节点的具体实现方案
1. 数据同步:
去中心的实现方案中每个节点都掌握着自己服务器内玩家的输入数据,需要将这些数据进行同步,最终达到每个节点的数据都是全局玩家的请求,这就需要服务的进程上提供数据传输与接收的接口。具体的对于一个GameServer来说接收本地的玩家数据搜索请求,需要给它全局数据内有相同输入码的玩家,并且通知该服务器上的玩家搜索到了新的玩家,并且将该玩家请求广播出去,对于广播到GameServer 通知本地的玩家新的搜索结果。具体的同步过程如下图所示:
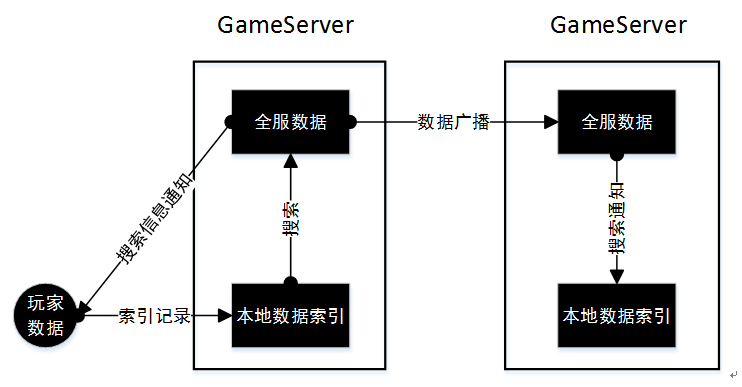
图3 全服数据同步与搜索结果的通知
2. 匹配与搜索:
面对面好友的搜索规则是在指定时间区间内输入相同搜索码的玩家,会显示在对方的搜索结果列表中,玩家可重复搜索。搜索的玩家个数具有一定的上限,具体的搜索码有四个数字组成,规则为30秒内输入相同搜索码, 搜索人数上限为30。
从以上数据可以知道搜索码一共是 10000 中可能, 而每个搜索码最多承载30个玩家, 所以全服数据最多30 * 10000 个玩家数据,如果我们每次都去遍历30万玩家的数据去查找相同搜索码显然不太现实, 并且有源源不断的玩家数据发送过来, 那么30秒以外的数据是需要及时清除的, 否则会耗尽内存。 此外我们在搜索结果的通知时需要获取玩家服务器地址的需求, 以便将搜索结果发送多去,更为重要的是玩家的其它信息,比如姓名、性别、头像、段位、等级等信息也是需要在客户端显示的,这些信息如果通过访问数据表进行获取,就加大了数据访问的压力,假设有10个人一起面对面, 那么在不同的服务器都去查表获取这些玩家的数据,可能需要10 * 9 次的数据库访问。基于以上分析在具体的搜索与匹配策略中采用了如下方案:

图 4 服务端数据存储结构
具体策略:采用如上的数据结构是典型的空间换时间的做法, 为了避免搜索结果去查询玩家的信息,此处采用了将玩家信息一并发送的策略。 这样就省去了数据库的信息查询。时间戳为索引的字典: 主要作用是将过时的玩家数据进行清除, 清除的同时也会去清除Code为索引 以及UID 为索引字典中相关的数据, 以保证三者之间信息的同步。Code为索引的字典: 主要用于快速查询相同搜索码的玩家,并将数据返回给前来搜索的玩家。UID为索引的字典:用于快速查询与存储玩家的数据。 本地玩家{UID:通信地址}字典: 用于判定是否是本地玩家以及取得与本地玩家的通信地址, 可以在数据同步时显著减少冗余通信。此外服务进程采用定时发送的策略,将本地玩家数据缓冲每10个TICK 将数据统一同步到其它服务器以减少单个通知的通信压力。
数据监控: 正常情况下随着时间的进行, 过时的时间戳存储的数据将会被删除, 此时其它几个存储了过时玩家数据的字典也会清除, 但是在异常情况下可能出现死点数据,导致这些数据永远存储在字典中,长期下去会增加内存的消耗,严重时会导致服务器崩溃, 因此需要监控数据,定时的清除死点数据。 对于时间戳为索引的字典每10个TICK就会清除过时的数据,因此不需要监控。 对于以Code为索引的字典, 因为Code 仅1万种,且每个Code内的玩家最多30 个, 因此可以采取每个Tick检查一个Code内的所有玩家数据是否过时, 那么10000/600 每 16 分钟就可以完成一次清扫。 对于以UID为索引的字典, 最多有30万玩家的数据, 因为UID数据一致在变化, 我们无法进行遍历, 此处采用随机采样的策略,在每个TICK中随机抽取100个玩家数据进行检查, 那么对于一次抽查数据抽不到的概率是1-100/300000, 那么20000次抽取都抽不到的概率是(1-100/300000)的 20000次方, 大概是0.1 %, 因此大概每 32 分钟就能完成一次死数据的清扫工作。
内存分析: 以上的方案中采用了以空间换时间的策略, 那么需要对占用的内存空间进行分析,总共极端情况下是30 万玩家数据,每个玩家的数据量 经过字段精简后大概上限是300B 那么一共大概是 100M内存的用量。