grep 分析一行信息,以整行为单位,用在正则表达式里面。最重要的功能是进行字符串数据的对比,然后将符合需求的字符串打印出来
简单语法:
grep [-acinv] [--color=auto] '查找字符串' filename
-a 将binary文件以text文件的方式查找数据
-c 计算找到'查找字符串'的次数
-i 忽略大小写的不同
-n 输出行号
-v 反向选择,显示出没有'查找字符串'内容的那一行
--color=auto 将找到的关键字部分加上颜色
例:将last中出现root的一行取出来
last | grep 'root'
一些高级参数 :grep [-A] [-B] [--color=auto] '查找字符串' filename
-A 后面可加数字,除了列出该行,后续n行也列出来
-B 后面可加数字,除了列出该行,前面n行也列出来
例,在关键字所在行的前两行和后三行一起找出来
dmesg | grep -n -A3 -B2 --color=auto 'eth'

sed
可以将数据进行替换、删除、新增、选取特定行等
sed [-nefr] [动作]
动作说明:[n1[,n2]]function
n1,n2 不见得会存在,一般代表选择进行动作的行数,例如,需要在10行到20行之间进行,则“10,20[动作行为]”
function参数:
a 新增
c 替换
d 删除
i 插入
p 打印
s 替换
例,将/etc/passwd 的内容列出并打印行号,同时删除2~5行
nl /etc/passwd | sed '2,5d'

在第二行后加上“drink tea”
nl /etc/passwd | sed '2a drink tea'

例,将第2~5行的内容替换为“no 2-5 number”
nl /etc/passwd | sed '2,5c no 2-5 number'

awk
awk主要是处理每一行的字段内的数据,而默认的字段的分隔符为空格键或[tab]键
awk '条件类型1{动作1} 条件类型2{动作2}...' filename
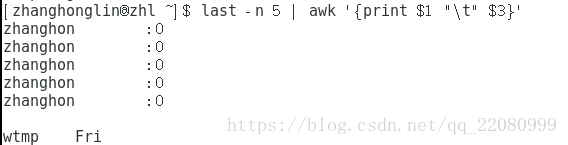
last -n 5 仅取出前5行

取出第一项和第三项
awk内置变量 NF:每一行($0)拥有的字段总数 NR:目前awk所处理的是第几行 FS:目前的分割字符,默认是空格键
