今天看了一个说法,说是入坑windows程序开发,必先掌握文字的编码和字符集知识。本博客就整理下信息存储和字符编码的相关知识。
一.位:
计算机存储信息的最小单位,称之为位(bit),音译比特,二进制的一个“0”或一个“1”叫一位。
二.字节
字节(Byte)是一种计量单位,表示数据量多少,它是计算机信息技术用于计量存储容量的一种计量单位,8个二进制位组成1个字节。在ASCII码中,一个标准英文字母(不分大小写)占一个字节位置,一个标准汉字占二个字节位置。
三.字符
字符是指计算机中使用的文字和符号,比如“1、2、3、A、B、C、~!·#¥%…*()+”等等。
四.ASCII码
先从最简单的ASCII说起吧,这个大家也熟悉:全名是American Standard Code for Information Interchange, 叫做“美国信息交换标准码”。ASCII码中,一个英文字母(不分大小写)占一个字节的空间,一个中文汉字占两个字节的空间。ASCII码是目前最普及的一种字符编码,它扎根于我们的互联网,操作系统,键盘,打印机,文件字体和打印机等。ASCII表如下:
图片来源百度百科
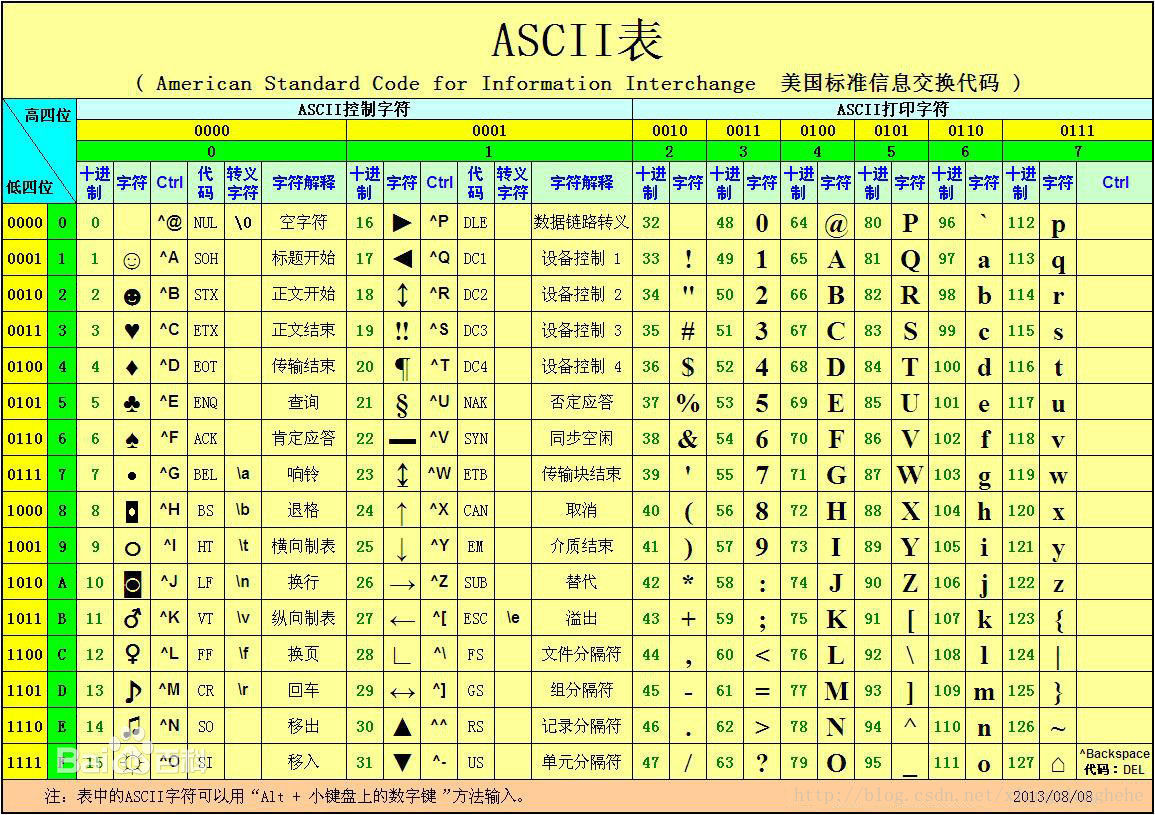
当然,从这个名字美国信息交换标准码来看,ASCII码只适用于美帝,要是用在美帝之外的国家,就不能满足需求了。
ANSI码
ANSI编码是一种对ASCII码的拓展:ANSI编码用0x00~0x7f 范围的1 个字节来表示 1 个英文字符,超出一个字节的 0x80~0xFFFF 范围来表示其他语言的其他字符。也就是说,ANSI码仅在前126个与ASCII码相同,之后的字符全是某个国家语言的所有字符。值得注意的是,两个字节最多可以存储的字符数目是2的16次方,即65536个字符,这对于一个语言的字符来说,绝对够了。还有ANSI编码其实包括很多编码:中国制定了GB2312编码,用来把中文编进去另外,日本把日文编到Shift_JIS里,韩国把韩文编到Euc-kr里,各国有各国的标准。受制于当时的条件,不同语言之间的ANSI码之间不能互相转换,这就会导致在多语言混合的文本中会有乱码。
Unicode编码
为了解决不同国家ANSI编码的冲突问题,Unicode应运而生:如果全世界每一个符号都给予一个独一无二的编码,那么乱码问题就会消失。这就是Unicode,就像它的名字都表示的,这是一种所有符号的编码。
Unicode标准也在不断发展,但最常用的是用两个字节表示一个字符(如果要用到非常偏僻的字符,就需要4个字节)。现代操作系统和大多数编程语言都直接支持Unicode。
但是问题在于,原本可以用一个字节存储的英文字母在Unicode里面必须存两个字节(规则就是在原来英文字母对应ASCII码前面补0),这就产生了浪费。那么有没有一种既能消除乱码,又能避免浪费的编码方式呢?答案就是UTF-8!
UTF-8编码
这是一种变长的编码方式:它可以使用1~4个字节表示一个符号,根据不同的符号而变化字节长度,当字符在ASCII码的范围时,就用一个字节表示,保留了ASCII字符一个字节的编码做为它的一部分,如此一来UTF-8编码也可以是为视为一种对ASCII码的拓展。值得注意的是unicode编码中一个中文字符占2个字节,而UTF-8一个中文字符占3个字节。从unicode到uft-8并不是直接的对应,而是要过一些算法和规则来转换。
在计算机内存中,统一使用Unicode编码,当需要保存到硬盘或者需要传输的时候,就转换为UTF-8编码。
用记事本编辑的时候,从文件读取的UTF-8字符被转换为Unicode字符到内存里,编辑完成后,保存的时候再把Unicode转换为UTF-8保存到文件。