参考2:使用R画桑基图(流程图)
桑基图(Sankey diagram),即桑基能量分流图,也叫桑基能量平衡图。它是一种特定类型的流程图,图中延伸的分支的宽度对应数据流量的大小,通常应用于能源、材料成分、金融等数据的可视化分析。因1898年Matthew Henry Phineas Riall Sankey绘制的“蒸汽机的能源效率图”而闻名,此后便以其名字命名为“桑基图”。桑基图最明显的特征就是,始末端的分支宽度总和相等,即所有主支宽度的总和应与所有分出去的分支宽度的总和相等,保持能量的平衡。
制作工具就有:JS库(D3、Ecgarts、highlight)、R、Python、PowerBI、Tableau、BDP个人版。
在R里,有三个包可以绘制桑基图:
library(riverplot)
library("d3Network")
library(Networkd3)
然而第一个包特色过于鲜明,第二个包对中文不太友好,所以个人偏向于第三个包。而在绘制桑基图中,我卡在了数据结构上。。。
栗子:以分析用户购买行为为例绘制桑基图。假设有产品A/B/C三种,分析用户购买路径,第一次买了什么,第二次买了什么,第三次买了什么。源数据共21个用户,如下:
说明:第一次购买A,第二次购买A,第三次购买C的用户有3个,以此类推。其中有流失用户,比如第二行的用户,在second->third过程中流失。
根据参考1可知,桑基图的数据结构只有三列,起点、终点和权重,在源数据中有多少节点对,那么最终数据就有多少个三变量数据,并要将所有三变量数据表顺序进行列对齐合并。在我们的数据中有四列数据,first->second->third 以及最后一列权重值,其中有两个节点对(first->second,second->third)。因此我们需要把数据拆开,即:
因此,第一个三变量数据,总用户数为21,且没有流失用户:
在计算value值时,计算的是first->second的各个组合的用户总数,比如A->A,用户数为3+1 = 4
第二个三变量数据,总用户数为21,其中流失用户5:
将两个数据纵向合:
绘图:
结果图如下,都不知道是个什么东西。。。这是因为我们没有区分第一次、第二次、第三次,从而使得A->A变成从A出发又流向A本身。

解决途径就是区分第一次、第二次、第三次购买产品的名称,比如第一次购买的产品名称都在产品后面加1。另外最右边灰色部分表示流失,如果数据把缺失行去掉就不会出现流失部分。最终用于绘图的数据如下:
结果图如下:
在R里,有三个包可以绘制桑基图:
library(riverplot)
library("d3Network")
library(Networkd3)
然而第一个包特色过于鲜明,第二个包对中文不太友好,所以个人偏向于第三个包。而在绘制桑基图中,我卡在了数据结构上。。。
栗子:以分析用户购买行为为例绘制桑基图。假设有产品A/B/C三种,分析用户购买路径,第一次买了什么,第二次买了什么,第三次买了什么。源数据共21个用户,如下:
| first | second | third | value |
| A | A | C | 3 |
| A | A | 1 | |
| A | B | A | 2 |
| B | A | A | 2 |
| B | A | 1 | |
| B | B | C | 2 |
| B | C | C | 1 |
| C | A | B | 1 |
| C | A | 3 | |
| C | A | C | 3 |
| C | C | B | 2 |
根据参考1可知,桑基图的数据结构只有三列,起点、终点和权重,在源数据中有多少节点对,那么最终数据就有多少个三变量数据,并要将所有三变量数据表顺序进行列对齐合并。在我们的数据中有四列数据,first->second->third 以及最后一列权重值,其中有两个节点对(first->second,second->third)。因此我们需要把数据拆开,即:
| 起点 | 终点 | 权重 |
| first | second | value1 |
| second | third | value2 |
因此,第一个三变量数据,总用户数为21,且没有流失用户:
| first | second | value1 |
| A | A | 4 |
| A | B | 2 |
| B | A | 3 |
| B | B | 2 |
| B | C | 1 |
| C | A | 7 |
| C | C | 2 |
第二个三变量数据,总用户数为21,其中流失用户5:
| second | third | value2 |
| A | C | 3 |
| A | 5 | |
| B | A | 2 |
| A | A | 2 |
| B | C | 2 |
| C | C | 1 |
| A | B | 1 |
| A | C | 3 |
| C | B | 2 |
将两个数据纵向合:
| s | t | v |
| A | A | 4 |
| A | B | 2 |
| B | A | 3 |
| B | B | 2 |
| B | C | 1 |
| C | A | 7 |
| C | C | 2 |
| A | C | 3 |
| A | 5 | |
| B | A | 2 |
| A | A | 2 |
| B | C | 2 |
| C | C | 1 |
| A | B | 1 |
| A | C | 3 |
| C | B | 2 |
绘图:
- library(networkD3)
- a = read.csv("m.csv") # a为合并之后的数据
- a$s = as.character(a$s) # 导入数据的起点终点是factor类型,需要将其转为chr,否则之后unique的是因子水平,不能进行合并。
- a$t = as.character(a$t)
- Sankeylinks<-a
- Sankeynodes<-data.frame(name=unique(c(Sankeylinks$s,Sankeylinks$t)))
- Sankeynodes$index<-0:(nrow(Sankeynodes) - 1)
- Sankeylinks<-merge(Sankeylinks,Sankeynodes,by.x="s",by.y="name")
- Sankeylinks<-merge(Sankeylinks,Sankeynodes,by.x="t",by.y="name")
- Sankeydata<-Sankeylinks[,c(4,5,3)];
- names(Sankeydata)<-c("Source","Target","Value")
- Sankeyname<-Sankeynodes[,1,drop=FALSE]
- sankeyNetwork(Links=Sankeydata,Nodes=Sankeyname, Source ="Source",
- Target = "Target", Value = "Value", NodeID = "name",
- fontSize = 12, nodeWidth = 30)
结果图如下,都不知道是个什么东西。。。这是因为我们没有区分第一次、第二次、第三次,从而使得A->A变成从A出发又流向A本身。
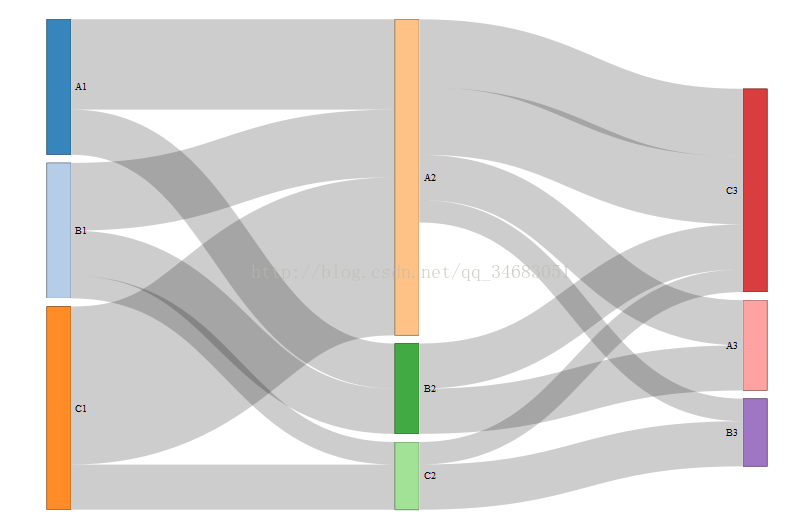
解决途径就是区分第一次、第二次、第三次购买产品的名称,比如第一次购买的产品名称都在产品后面加1。另外最右边灰色部分表示流失,如果数据把缺失行去掉就不会出现流失部分。最终用于绘图的数据如下:
| s | t | v |
| A1 | A2 | 4 |
| A1 | B2 | 2 |
| B1 | A2 | 3 |
| B1 | B2 | 2 |
| B1 | C2 | 1 |
| C1 | A2 | 7 |
| C1 | C2 | 2 |
| A2 | C3 | 3 |
| B2 | A3 | 2 |
| A2 | A3 | 2 |
| B2 | C3 | 2 |
| C2 | C3 | 1 |
| A2 | B3 | 1 |
| A2 | C3 | 3 |
| C2 | B3 | 2 |
结果图如下: