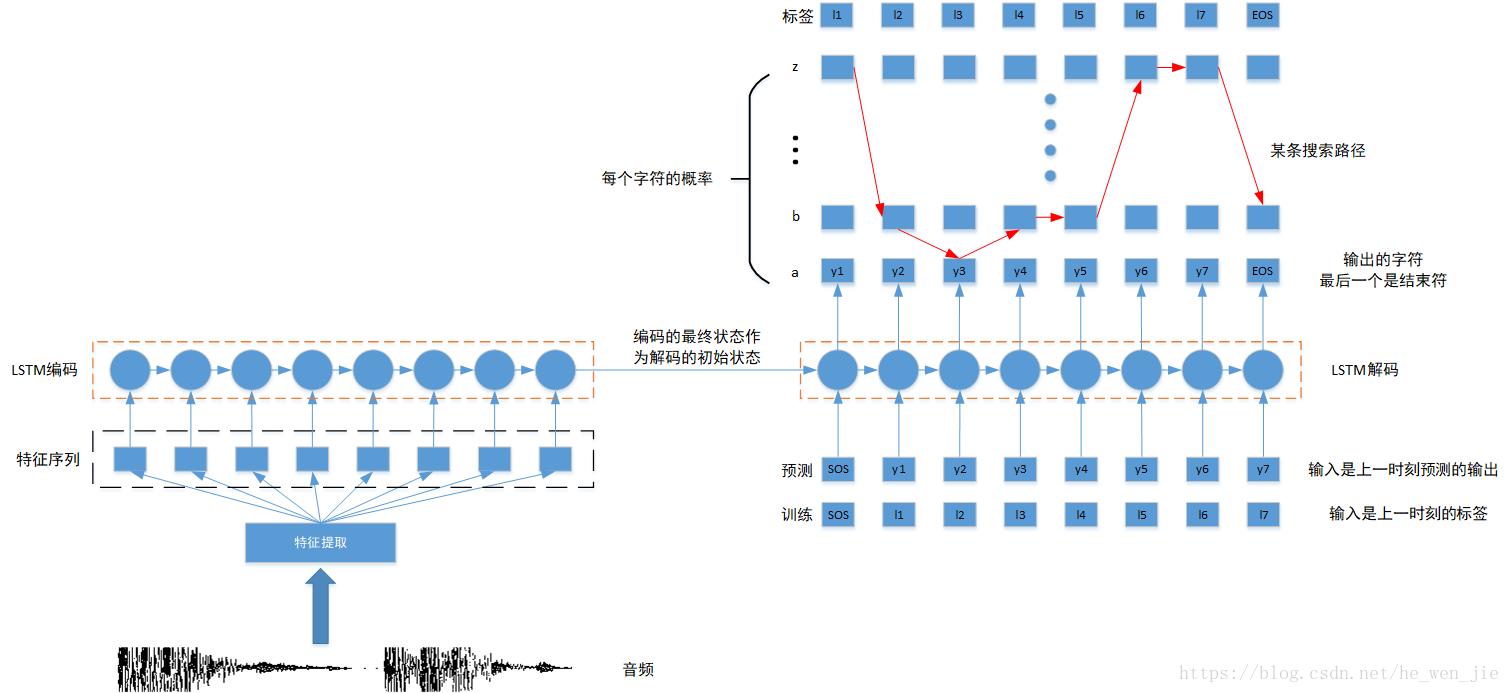
seq2seq没什么可说的,这里只是使用tensorflow 1.8最新的seq2seq接口。第一步肯定就是数据了,我们随机生成n个序列,然后将数据重写为tfrecords格式,tf.dataset进行读取数据输入到seq2seq中,标签和数据一样,也就是说我们希望seq2seq能学会输入(感觉在做AutoEncoder)。
1. 序列生成
序列的长度是不确定的,范围在
,序列的值也在
内。其实想想这很符合实际,通常我们使用的是字符串或者字符,字符串的长度是不定的,为了可计算,我们需要将字符串转换成数字,用不同数字表示不同字串,如果有1000个不同的字符串,我们可以用[0,999]每一个数字代替一个字符串。
def random_sequences(length_from, length_to,
vocab_lower, vocab_upper,
num_seq):
#length_from, length_to 序列的长度范围
#vocab_lower, vocab_upper 序列的数值范围
#num_seq 生成的序列个数
if length_from > length_to:
raise ValueError('length_from > length_to')
def random_length():
if length_from == length_to:
return length_from
return np.random.randint(length_from, length_to + 1)
for _ in range(num_seq): # 这里使用迭代生成,这样不占空间
yield np.random.randint(low=vocab_lower,
high=vocab_upper,
size=random_length()).tolist()
2. 将数据转为tfrecord格式
为什么要转成这个格式呢?我们的数据实在CPU上生成的,直接生成数据通过feed_dict传入网络训练的非常慢,实际测了一下,GPU要68s,CPU要36s,没错,GPU要比CPU慢。好像是因为数据从CPU拷贝到GPU的时间比直接在CPU上直接计算还要久。tfrecord格式的数据是可以直接传到GPU的,速度果然杠杠的。注意数据可是变长的。tensorflow 变长序列存储
sequences = random_sequences(length_from=3, length_to=8,
vocab_lower=3, vocab_upper=10,
num_seq=3000) # 创建一个数据迭代器,也就是我们的训练数据源
# seq2seq解码需要定义起始和结束符号,要和序列的值不一样,这里序列值的范围在3到10之间
# 我就定义了1和2,0用来pad序列,所以我就没有用
sos = 1
eos = 2
writer = tf.python_io.TFRecordWriter('file')
for seq in sequences: # 遍历每一个序列将其转成tfrecord
feature = {
'encoder_inputs' : _int64_feature(seq), # 编码输入不需要做什么
'decoder_inputs' : _int64_feature([sos]+seq), # 解码输入需要在序列前添加sos,我们的标签就是数据
'decoder_targets' : _int64_feature(seq+[eos]) # 解码阶段的标签需要在标签后面添加eos
}
example = tf.train.Example(features=tf.train.Features(feature=feature))
writer.write(example.SerializeToString())
writer.close()
读取数据
我们需要读取tfrecord的数据,这里使用tf.dataset提供的API。这里有两点需要注意,第一是序列是变长的,我们解析的时候需要使用tf.VarLenFeature和tf.sparse_tensor_to_dense这两个函数才行。其次,训练的时候我们是batch输入的,一个batch中的序列必须是一样长的(当然不同的batch可以不一样长),所以我们需要pad。
filenames = ["file"]
dataset = tf.data.TFRecordDataset(filenames)
def _parse_function(example_proto):
keys_to_features = {
'encoder_inputs':tf.VarLenFeature(tf.int64), # 序列是变长的,需要使用tf.VarLenFeature
'decoder_inputs':tf.VarLenFeature(tf.int64),
'decoder_targets':tf.VarLenFeature(tf.int64)
}
parsed_features = tf.parse_single_example(example_proto, keys_to_features)
encoder_inputs = tf.sparse_tensor_to_dense( parsed_features['encoder_inputs'])
decoder_inputs = tf.sparse_tensor_to_dense( parsed_features['decoder_inputs'])
decoder_targets = tf.sparse_tensor_to_dense( parsed_features['decoder_targets'])
encoder_inputs = tf.cast(encoder_inputs,tf.int32) # 转换成tf.int32,因为后面logit是tf.int32
decoder_inputs = tf.cast(decoder_inputs,tf.int32)
decoder_targets = tf.cast(decoder_targets,tf.int32)
return encoder_inputs,decoder_inputs,decoder_targets
dataset = dataset.map(_parse_function) # 对每一个序列进行解析,返回序列的数据,标签等等
dataset = dataset.repeat(10) # 迭代10次,不填意味着无穷次
dataset = dataset.padded_batch(32,padded_shapes=([None],[None],[None]))# 动态pad,这里返回3个值,都是变长的,所以需要3个None
iterator = dataset.make_one_shot_iterator()
encoder_inputs,decoder_inputs,decoder_targets = iterator.get_next()
decoder_shape = tf.shape(decoder_targets)# 先不急,后面好好分析,狗日的
decoder_lengths = tf.fill([decoder_shape[0]],decoder_shape[1])网络搭建
数据也可以读取了,下一步就是搭建网络了。还是老样子,首先是对输入进行embed。embed可以理解为降维,比如我们有1000个字符串,每个字符串映射到[0,999]中的某个值,我们通过embed就可以得到映射到例如[0,300]。
src_vocab_size = 10 # 这个一定大于等于我们的所有序列的值,要不然序列的某些值无法映射。
# 想一想假如我们有1000个字符串,讲道理要映射到`[0,999]`的,如果我们的src_vocab_size=900,
# 那么大于900的词就无法索引了啊
tgt_vocab_size = 10 # 输入和输出一样的范围
embedding_size = 5 # 映射后的维度值
embedding_encoder = tf.get_variable("embedding_encoder", [src_vocab_size, embedding_size])
encoder_emb_inputs = tf.nn.embedding_lookup(embedding_encoder, encoder_inputs)
embedding_decoder = tf.get_variable("embedding_decoder", [tgt_vocab_size, embedding_size])
decoder_emb_inputs = tf.nn.embedding_lookup(embedding_decoder, decoder_inputs)然后就是编码序列了
encoder_cell = tf.nn.rnn_cell.BasicLSTMCell(num_units)
encoder_outputs, encoder_state = tf.nn.dynamic_rnn(
encoder_cell, encoder_emb_inputs, dtype=tf.float32) # 我们只需要encoder_state就可以了下面就是tensorflow的seq2seq了,老实说我还不怎么明白,但是看着好像又明白。TrainingHelper函数有一个sequence_length参数,这个我搞了好久,这个参数是一个向量,长度为batch_size,每个值代表batch中每个序列解码的长度,一个batch中序列长度一样,所以只要获取这个batch中一个长度,然后拷贝batch_size个组成一个向量就可以了。这样我们可以先获取一个decoder_targets的shape,decoder_targets.shape = [batch_size,seq_length],shape[0]就是batch_size,shape[1]就是长度,我们通过tf.fill函数生成一个长度为batch_size,值全为seq_length的向量。也就是
decoder_shape = tf.shape(decoder_targets)
decoder_lengths = tf.fill([decoder_shape[0]],decoder_shape[1])projection_layer = layers_core.Dense(tgt_vocab_size, use_bias=False) # LSTM后加一个全连接,输出概率值
train_helper = tf.contrib.seq2seq.TrainingHelper(decoder_emb_inputs, decoder_lengths)
decoder_cell = tf.nn.rnn_cell.LSTMCell(num_units)
initial_state = encoder_state # 编码的最终状态作为解码的初始状态
train_decoder = tf.contrib.seq2seq.BasicDecoder(
decoder_cell, train_helper, initial_state,output_layer=projection_layer)
final_outputs, _, _ = tf.contrib.seq2seq.dynamic_decode(train_decoder)然后就是损失函数了
logits = final_outputs.rnn_output
loss = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=decoder_targets, logits=logits)
loss = tf.reduce_mean(loss)RNN需要梯度裁剪,这个学习率可能要改成动态的,因为训练的时候不怎么收敛。
optimizer = tf.train.AdamOptimizer(learning_rate)
gvs = optimizer.compute_gradients(loss)
capped_gvs = [(tf.clip_by_value(grad, -1., 1.), var) for grad, var in gvs]
train_op = optimizer.apply_gradients(capped_gvs)最后就是训练了
with tf.Session() as sess:
tf.summary.FileWriter('log',sess.graph)
sess.run(tf.global_variables_initializer())
while True:
try:
_, loss_value = sess.run([train_op, loss])
print(loss_value)
except tf.errors.OutOfRangeError:
break