Seq2Seq模型是RNN最重要的一个变种:N vs M(输入与输出序列长度不同)。
这种结构又叫Encoder-Decoder模型。
由于这种Encoder-Decoder结构不限制输入和输出的序列长度,因此应用的范围非常广泛,比如:
机器翻译。Encoder-Decoder的最经典应用,事实上这一结构就是在机器翻译领域最先提出的
文本摘要。输入是一段文本序列,输出是这段文本序列的摘要序列。
阅读理解。将输入的文章和问题分别编码,再对其进行解码得到问题的答案。
语音识别。输入是语音信号序列,输出是文字序列。
原始的N vs N RNN要求序列等长,然而我们遇到的大部分问题序列都是不等长的,如机器翻译中,源语言和目标语言的句子往往并没有相同的长度。
为此,Encoder-Decoder结构先将输入数据编码成一个上下文向量c:

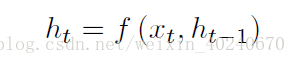
得到c有多种方式,最简单的方法就是把Encoder的最后一个隐状态赋值给c,还可以对最后的隐状态做一个变换得到c,也可以对所有的隐状态做变换。
拿到c之后,就用另一个RNN网络对其进行解码,这部分RNN网络被称为Decoder。
极大化联合分布概率:
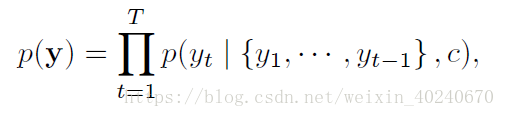
在RNN作为decoder时,每个条件概率为
here g is a nonlinear, potentially multi-layered, function that outputs the probability of yt, and st is the hidden state of the RNN
具体做法就是将c当做之前的初始状态h0输入到Decoder中:
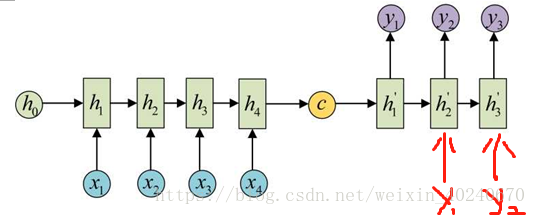
还有一种做法是将c当做每一步的输入:

seq2seq模型扩展:
1、多层、RNN改为LSTM
与单层RNN原理一样
2、注意力机制