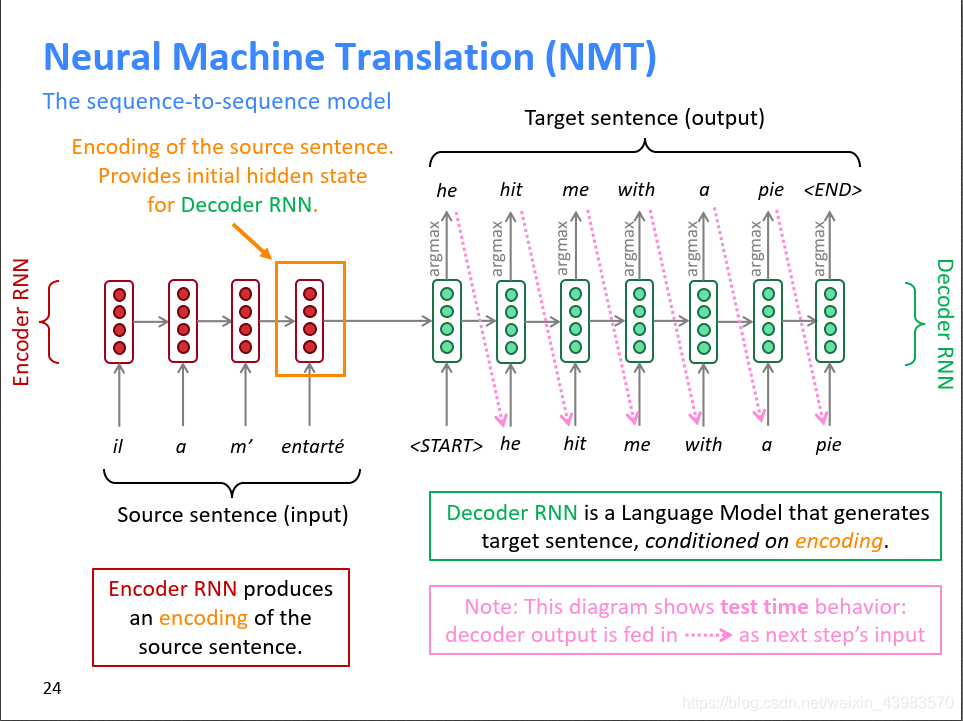
seq2seq的NMT(神经网络翻译)如下图所示,它由两个RNN组成,左边的红色部分称为Encoder RNN,它负责对源语言进行编码(Encode);右边的绿色部分称为Decoder RNN,它负责对目标语言进行解码(Decode)。首先,Encoder RNN可以是任意一个RNN,比如朴素RNN、LSTM或者GRU。Encoder RNN负责对源语言进行编码,学习源语言的隐含特征。Encoder RNN的最后一个神经元的隐状态作为Decoder RNN的初始隐状态。Decoder RNN是一个条件语言模型,一方面它是一个语言模型,即用来生成目标语言的;另一方面,它的初始隐状态是基于Encoder RNN的输出,所以称Decoder RNN是条件语言模型。Decoder RNN在预测的时候,需要把上一个神经元的输出作为下一个神经元的输入,不断的预测下一个词,直到预测输出了结束标志符,预测结束。Encoder RNN的输入是源语言的word embeding,Decoder RNN的输入是目标语言的word embeding。
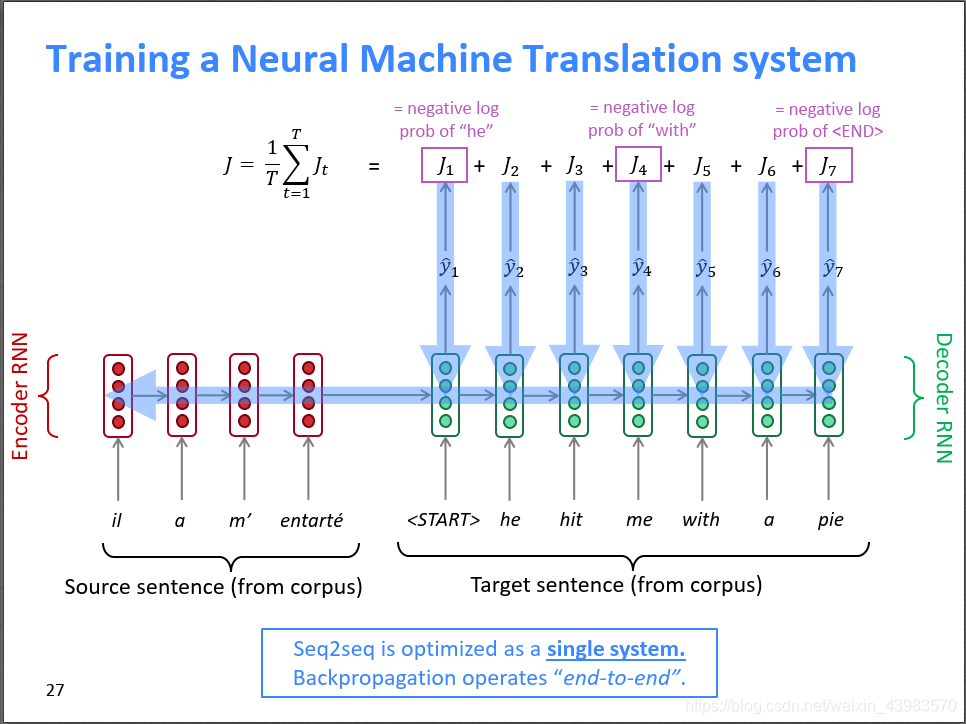
上面介绍了seq2seq的预测过程,seq2seq的训练过程如下图所示。训练的时候,我们同时需要源语言和翻译好的目标语言,分别作为Encoder RNN和Deocder RNN的输入。对于Encoder RNN没什么好说的。Decoder RNN在训练阶段,每一个时间步的输入是提供的正确翻译词,输出是预测的下一个时间步的词的概率分布,比如在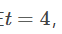 ,预测输出是
,预测输出是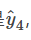
,而正确答案是”with”,根据交叉熵损失函数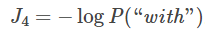 ,。总的损失函数就是所有时间步的损失均值。
,。总的损失函数就是所有时间步的损失均值。
上上张图介绍的seq2seq的预测过程,实际上是一个贪心的预测过程,即在Decoder RNN的每一步都贪心选择概率最大的那个词。但是贪心只能保证每一步是最优的,无法保证预测出来的句子整体是最优的。特别是如果在时刻贪心选择的词不是全局最优,会导致时刻往后的所有预测词都是错误的,没有回头路了。但是如果每个时间步都穷举所有可能的情况的话,时间复杂度又太高了。
注意力机制Attention
最后介绍提升机器翻译性能的一大利器——注意力机制Attention。首先回顾一下朴素的seq2seq模型,我们用Encoder RNN的最后一个神经元的隐状态作为Decoder RNN的初始隐状态,也就是说Encoder的最后一个隐状态向量需要承载源句子的所有信息,成为整个模型的“信息”瓶颈。
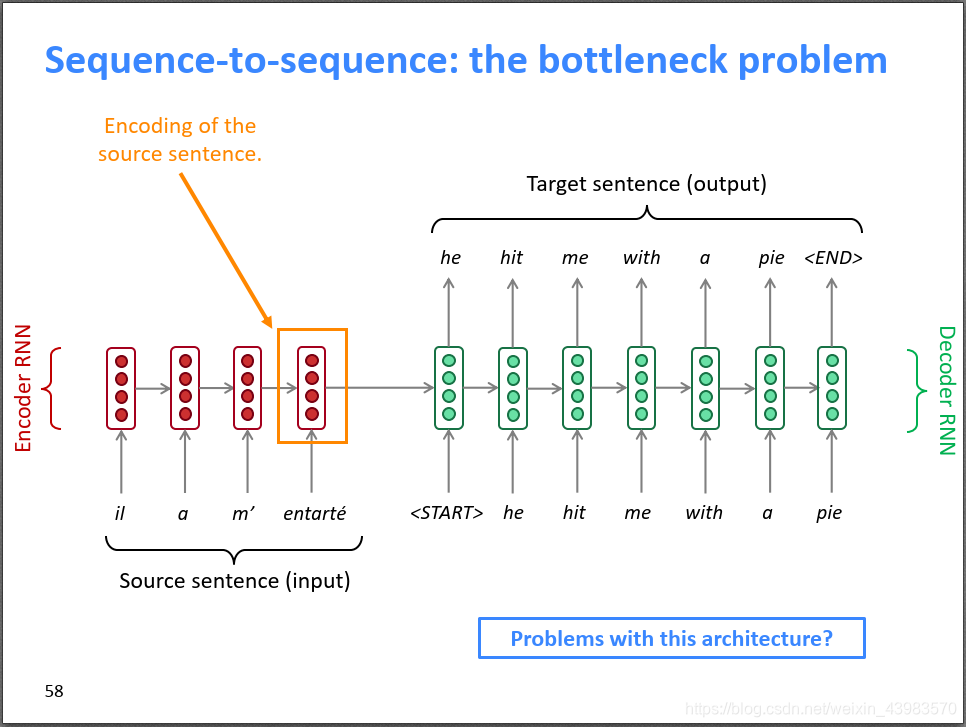
Attention机制就是为了解决这个“信息”瓶颈而设计的,请大家结合下面的示意图和公式进行理解。宏观上来说,Attention把Decoder RNN的每个隐层和Encoder RNN的每个隐层直接连起来了,还是“减少中间商赚差价”的思路,由于有这个捷径,Encoder RNN的最后一个隐状态不再是“信息”瓶颈,信息还可以通过Attention的很多“直连”线路进行传输。
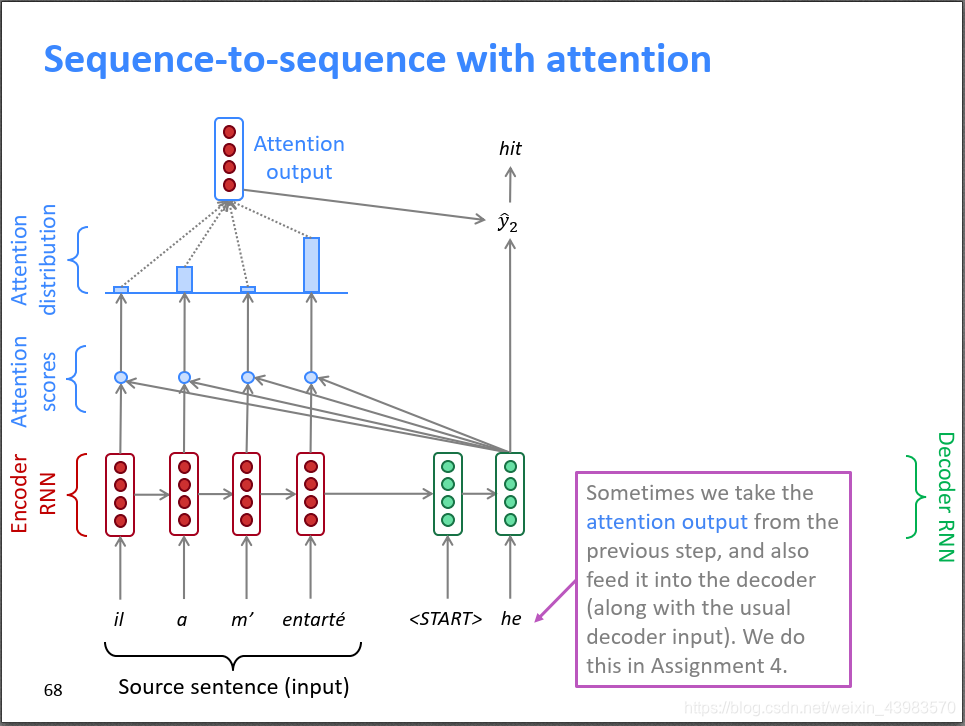
具体来说,在时刻,Decoder第t时刻的隐状态和Encoder所有时刻的隐状态做点积,得到N个标量Attention score,作为Encoder每个隐状态的权重,然后使用softmax对这些权重进行归一化,得到Attention distribution。这个Attention distribution相当于Decoder在时刻t对Encoder所有隐状态的注意力分布,如下图所示,”he”时刻的注意力主要分布在Encoder的第2和第4个词上。Attention自动学习到了这种对齐操作,只不过是soft alignment。
接下来,对Encoder所有隐状态使用Attention distribution进行加权平均,得到Attention output 。把和该时刻的隐状态拼起来再进行非线性变换得到输出
。有时,也可以把上一时刻的Attention output和当前的输入词向量拼起来作为一个新的输入,输入到Decoder RNN中。