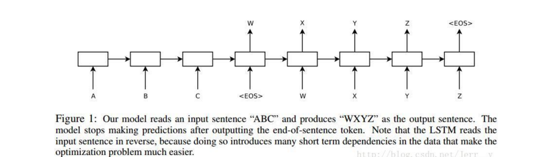
Seq2seq于2014年Google Brain团队的《Sequence to Sequence Learning with Neural Networks》提出。应用场景也很广泛。比如聊天机器人,机器翻译,文档摘要自动生成,图片描述自动生成等。顾名思义,所有应用场景的一个共同点都是sequence to sequence,即由一个序列得到另外一个序列。
Seq2seq模型由Encoder编码器和Decoder解码器组成。Encoder可以是rnn,可以是lstm,也可以是transformer结构。它负责将输入序列编码成一个指定长度的隐藏状态,即语义向量C。解码器当给它一个解码信号,它就负责根据这个语义向量C生成其他的序列。基本结构图如下:
seq2seq 有四种模式:
模式一:普通作弊 basic encoder-decoder
编码时每个时刻除了自己上一时刻的隐层状态编码外,还有当前时刻的输入,而解码时则没有这种输入。那么,一种比较直接的方式是把编码端得到的编码向量做为解码模型的每时刻输入特征。为什么叫作弊呢?因为普通同学(解码器)在考试做每一道题(每次解码)时都需要看课堂笔记(语义向量C)。结构图如下:
模式二:学霸模式 encoder-decoder with feedback
编码时每一时刻输入包含上一时刻的隐藏状态和当前时刻的输入。解码时每一时刻都使用上一时刻的隐藏状态和上一时刻的输出,而语义向量C仅在第一次解码使用。学霸考试只在做第一道题看一下课堂笔记,然后就能记住课堂笔记的内容,做其他题的时候只需要回顾一下自己前面写过什么就可以。如下:
模式三:学弱作弊 encoder-decoder with peek
很多学弱,他们不只需要作弊,而且翻看笔记的时候还需要回顾自己上一时刻写在答卷上的答案。如下:

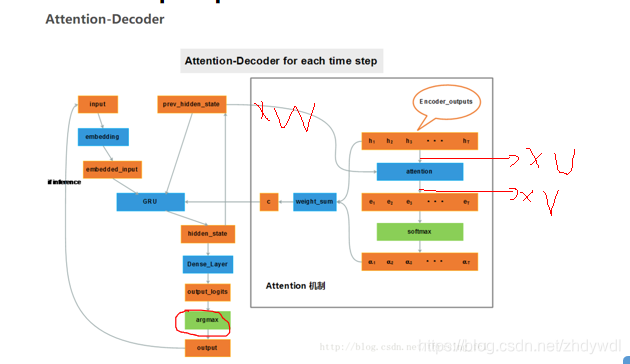
模式四:学渣作弊 encoder-decoder with attention
然而学渣渣也是存在的,他们不只需要作弊,不只需要回顾自己上一时刻卸载答卷上的答案,还需要老师在课本上画出重点才能整理出自己的课题笔记(这就是一种注意力机制Attention,记笔记的时候一定要根据考题画出重点啊!) ,如图:
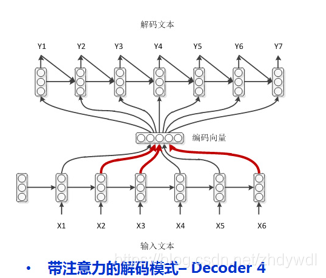
LSTM模型虽然有记忆性,但是当编码器输入序列过长,解码阶段LSTM也无法针对最早的输入序列解码,基于这个原因,提出了Attention注意力机制,在每次解码,都能有一个输入对输入序列的每一步加权求和。打个比方就是每次在预测下一个词时都会把所有输入序列的隐藏层信息都看一遍,决定预测当前词时和输入序列的那些词最相关。
Attention机制代表了在解码Decoder阶段,每次都会输入一个Context上下文的向量Ci。 隐藏层的新状态Si根据上一时刻的隐藏状态Si-1, 当前时刻的输入Yi, Ci 三者的一个非线性函数得出
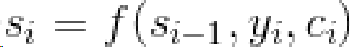
Context向量在解码的每一步都会重新计算,根据一个MLP模型计算出输出序列i对每个输入序列j的隐含层的对应权重aij,并对所有隐含层加权平均
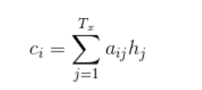
aij 即可以理解为解码的第i步,对输入序列第j步的注意力权重。
eij为一个简单的MLP模型激活的输出;aij的计算是对eij做softmax归一化后的结果
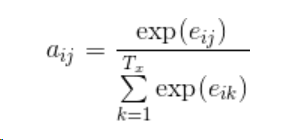
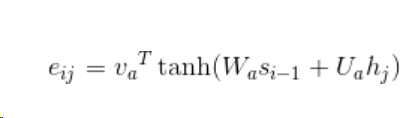
hj指编码器j时刻的隐藏状态,si-1指解码器i-1时刻的隐藏状态
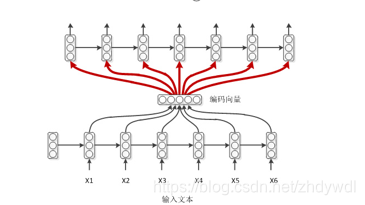
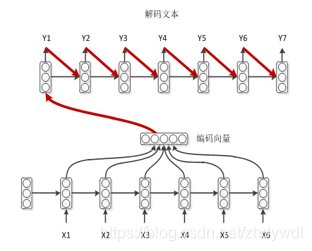
下图可以表示总体的流程