关于lenet-5网络模型原理可以参考我的另一篇博客:lenet-5
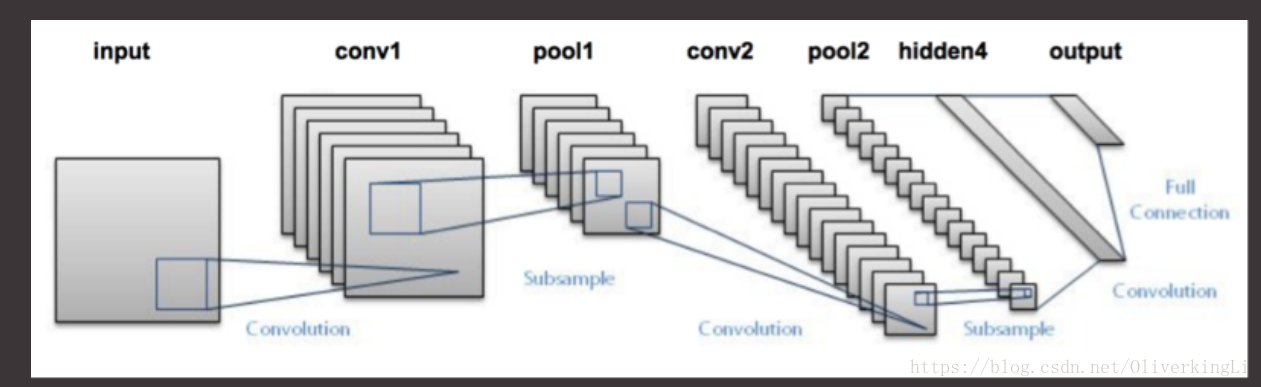
这里就放两张图:
lent-5主要的结构
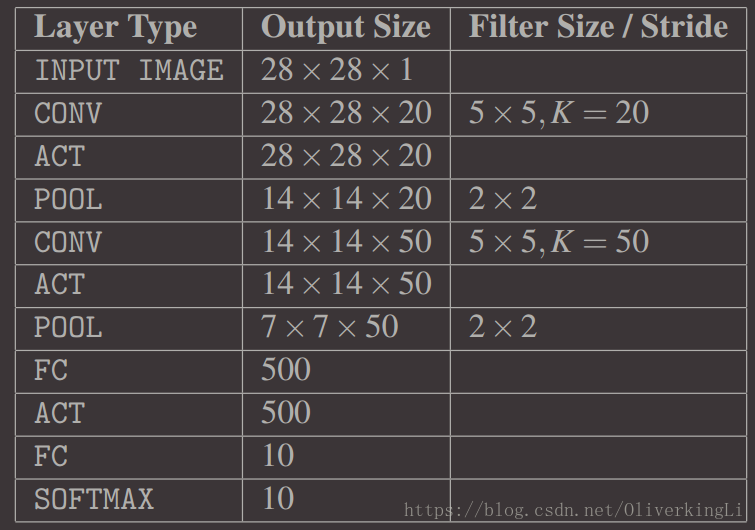
每一层对应的参数细节:
然后我们使用keras定义lenet-5网络结构,这里使用一个python文件定义成类然后包装成module:
lenet.py
from keras.models import Sequential
from keras.layers.convolutional import Conv2D
from keras.layers.convolutional import MaxPooling2D
from keras.layers.core import Activation, Flatten, Dense
from keras import backend as K
class LeNet:
@staticmethod
def build(width, height, depth, classes):
model = Sequential()
inputShape = (height, width, depth)
if K.image_data_format() == "channels_first":
inputShape = (depth, height, width)
model.add(Conv2D(20, (5, 5), padding="same", input_shape=inputShape))
model.add(Activation("relu"))
model.add(MaxPooling2D(pool_size=(2, 2), strides=(2, 2)))
model.add(Conv2D(50, (5, 5), padding="same"))
model.add(Activation("relu"))
model.add(MaxPooling2D(pool_size=(2, 2), strides=(2, 2)))
model.add(Flatten())
model.add(Dense(500))
model.add(Activation("relu"))
model.add(Dense(classes))
model.add(Activation("softmax"))
return model
然后是训练模块,同时把训练好的模型保存:
keras-lenet5.py
from lenet import LeNet
from keras.optimizers import SGD
from sklearn.preprocessing import LabelBinarizer
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
from sklearn import datasets
from keras import backend as K
import matplotlib.pyplot as plt
import numpy as np
# 加载数据MNIST,然后归一化到【0,1】,同时使用75%做训练,25%做测试
print("[INFO] loading MNIST (full) dataset")
dataset = datasets.fetch_mldata("MNIST Original", data_home="/home/king/test/python/train/pyimagesearch/nn/data/")
data = dataset.data
if K.image_data_format() == "channels_first":
data = data.reshape(data.shape[0], 1, 28, 28)
else:
data = data.reshape(data.shape[0], 28, 28, 1)
(trainX, testX, trainY, testY) = train_test_split(data / 255.0,
dataset.target.astype("int"), test_size=0.25, random_state=42)
# 将label进行one-hot编码
lb = LabelBinarizer()
trainY = lb.fit_transform(trainY)
testY = lb.transform(testY)
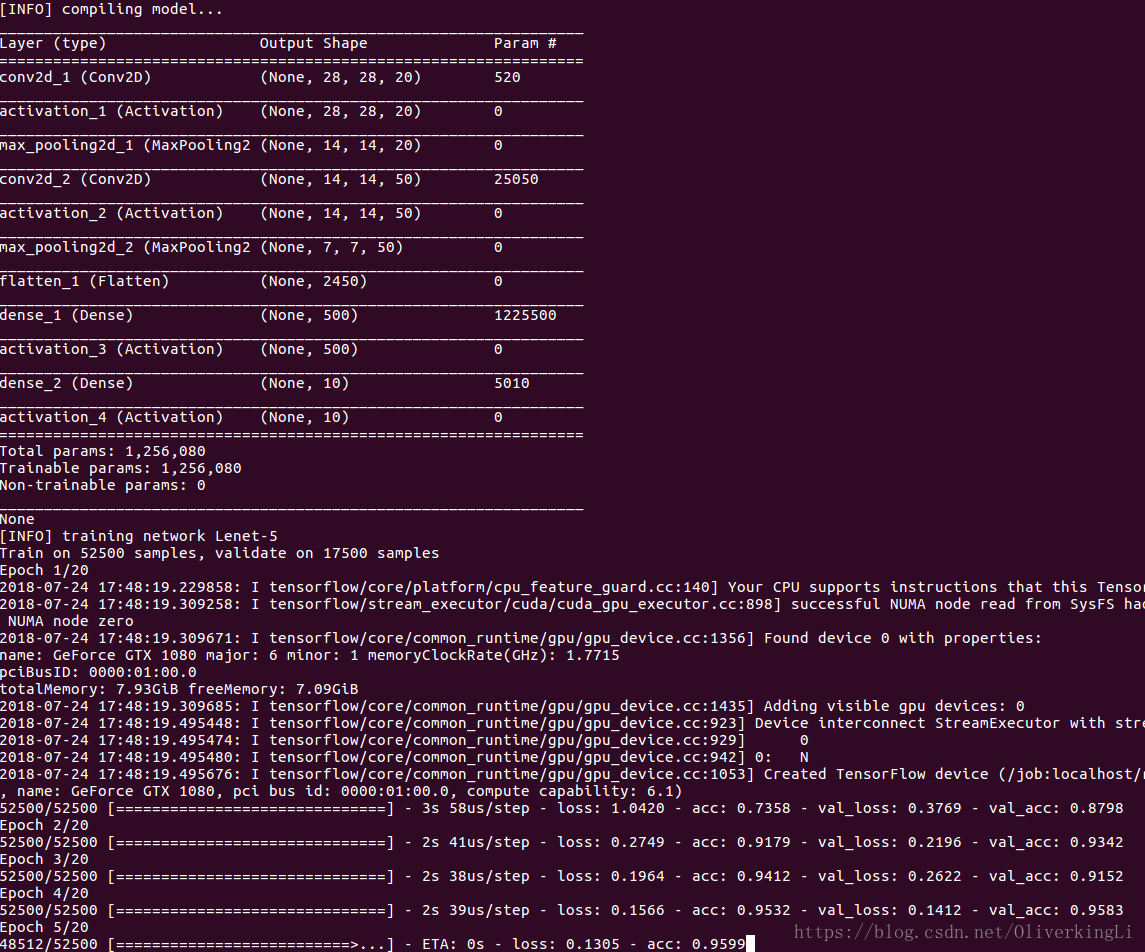
print("[INFO] compiling model...")
opt = SGD(lr=0.01)
model = LeNet.build(width=28, height=28, depth=1, classes=10)
model.compile(loss="categorical_crossentropy", optimizer=opt, metrics=['accuracy'])
print(model.summary())
print("[INFO] training network Lenet-5")
H = model.fit(trainX, trainY, validation_data=(testX, testY), batch_size=128, epochs=20, verbose=1)
model.save("./lenet-5-MNIST.hdf5")
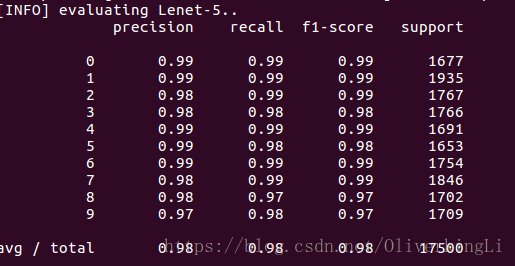
print("[INFO] evaluating Lenet-5..")
preds = model.predict(testX, batch_size=128)
print(classification_report(testY.argmax(axis=1), preds.argmax(axis=1),
target_names=[str(x) for x in lb.classes_]))
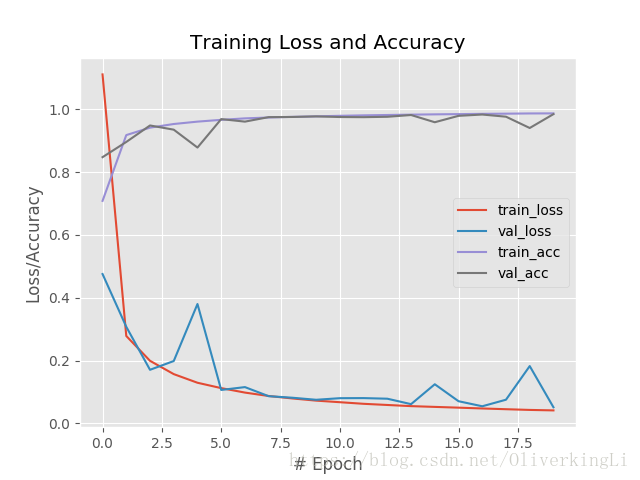
# 保存可视化训练结果
plt.style.use("ggplot")
plt.figure()
plt.plot(np.arange(0, 20), H.history["loss"], label="train_loss")
plt.plot(np.arange(0, 20), H.history["val_loss"], label="val_loss")
plt.plot(np.arange(0, 20), H.history["acc"], label="train_acc")
plt.plot(np.arange(0, 20), H.history["val_acc"], label="val_acc")
plt.title("Training Loss and Accuracy")
plt.xlabel("# Epoch")
plt.ylabel("Loss/Accuracy")
plt.legend()
plt.savefig("./lenet-5-loss_acc.png")
其次是测试程序:
扫描二维码关注公众号,回复:
2449722 查看本文章

这里就使用完整的mnist数据集中的50张做测试:
test.py
from lenet import LeNet
from keras.optimizers import SGD
from sklearn.preprocessing import LabelBinarizer
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
from sklearn import datasets
from keras import backend as K
from keras.models import load_model
import matplotlib.pyplot as plt
import numpy as np
import cv2
import argparse
ap = argparse.ArgumentParser()
ap.add_argument("-m", "--model", required=True, help="path to load train model")
args = vars(ap.parse_args())
# 加载数据MNIST,然后归一化到【0,1】,同时使用75%做训练,25%做测试
print("[INFO] loading MNIST (full) dataset")
dataset = datasets.fetch_mldata("MNIST Original", data_home="/home/king/test/python/train/pyimagesearch/nn/data/")
data = dataset.data
if K.image_data_format() == "channels_first":
data = data.reshape(data.shape[0], 1, 28, 28)
else:
data = data.reshape(data.shape[0], 28, 28, 1)
(trainX, testX, trainY, testY) = train_test_split(data / 255.0,
dataset.target.astype("int"), test_size=0.005, random_state=42)
# 将label进行one-hot编码
lb = LabelBinarizer()
trainY = lb.fit_transform(trainY)
testY = lb.transform(testY)
print("[INFO] loading pre-trained network...")
model = load_model(args["model"])
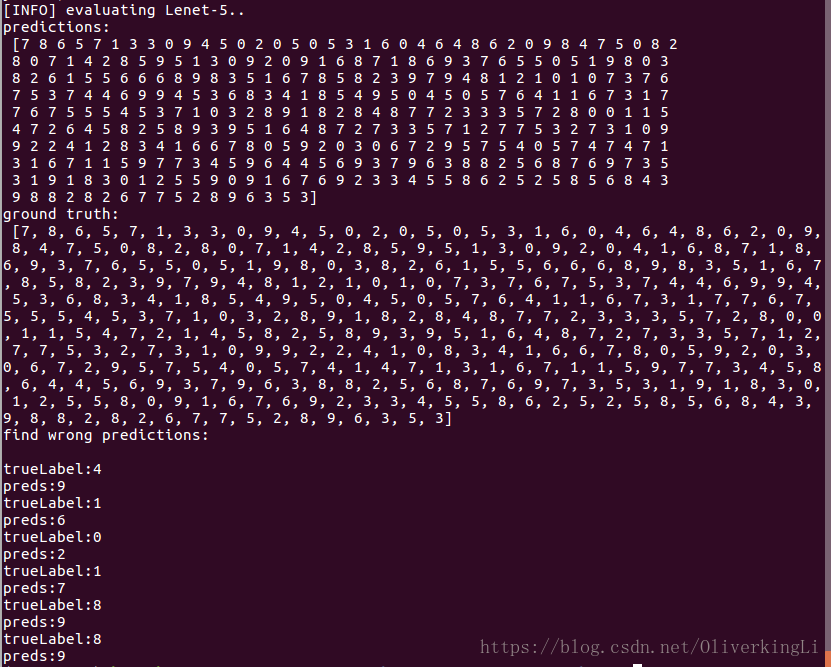
print("[INFO] evaluating Lenet-5..")
preds = model.predict(testX, batch_size=128).argmax(axis=1)
print("predictions:\n", preds)
trueLabel = []
for i in range(len(testY)):
for j in range(len(testY[i])):
if testY[i][j] != 0:
trueLabel.append(j)
print("ground truth:\n", trueLabel)
print("find wrong predictions:\n")
for i in range(len(trueLabel)):
if trueLabel[i] != preds[i]:
print("trueLabel:{}".format(trueLabel[i]))
print("preds:{}".format(preds[i]))
result:
测试结果: