在看高性能MySQL中,看到一个查询。
当时觉得explain的结果很没道理。
explain select film_id from film order by title limit 50,5;结果是这样的。

其中film这个表的索引如下

我就在想,通过对title排序,然后进行limit 50, 5。这个没问题,那就是通过索引就可以快速的操作。
但是,最后select的是film_id,这个不是要回表的吗?
因为仅仅通过title索引,是无法获取film_id的呀!
这两个又不是联合索引。。。
但是,真的是这样的吗?
哈哈!!!
不是的,我忘了MySQL默认引擎是innodb。
那就是,索引的数据结构是B+树。
其中,主键索引和二级索引的区别如下。
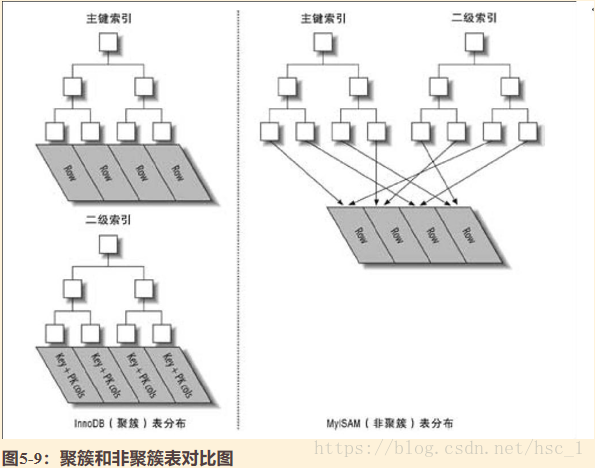
InooDB的二级索引的结构和主键索引的结构是一样的,都是B+树。
主键索引,其实, 就是一个表,每个叶子节点都包含了主键索引对应的一行。
但是二级索引不是这样的(所说结构是一样的),二级索引的叶子节点存储的是主键的值。
好了,到此可以回到开始提出的查询结果了。
explain select film_id from film order by title limit 50,5;
根据该表的索引(第二个图), 可以知道,film_id是主键索引,title是二级索引。
也就是title对应的这个索引的叶子节点存储的就是film_id的值。
所以,最开始提出的查询extra列的结果为using index。即,是不需要回表的。。。