海量是有多海量?

如果说只有10条数据需要进行处理,那这个世界就简单多了,我两个手就处理了。大不了每条去逐一检查,人为处理,也用不了多久。
如果有上百条数据,也不是很难处理,毕竟我还能数的过来。
但是,现实往往都不是如此的通情达理,毕竟大数据异常的火。动不动就大数据分析下为什么IT难找不到女朋友。

数据一旦上到千万级别,甚至 过亿,那就不是手工能解决的了,必须通过工具或者程序进行处理,尤其海量的数据。先让我们用程序员的角度思考一下,千万,亿是啥量级概念?
2¹⁰ = 1024,10亿 = 1000 000 000 ≈ 1024 × 1024 × 1024 = 2³⁰
2¹⁰ = 1K—–2²⁰ = 1M——2³⁰ = 1G
这个1G还是建立在每个数据都只占一个字节的前提下。
32 bit=1 bite,1 int= 4bite = 32bit;表示范围:2³² = 4G
我们评价一个程序算法的优劣一般都是时间复杂度,空间复杂度。海量数据如果都放在内存里跑,光数据就存了1G+,有的时候甚至根本就放不下,只能在文件,磁盘中。比较优的算法处理就显得很重要了,普通O(N)时间复杂度的查找等类似程序就很值得优化了。

现在我们举例子,在例子中分析下,海量数据处理的几种方法。
首先我们必须了解一种数据结构
Hash
Hash (哈希),它体现的是一种映射关系,即将我们的数据通过一个关键字key和底层数组的某一地址位置对应。哈希是转换思维的产物。
哈希表就是我们所讲的底层数组。哈希函数实现的就是数据关键字与存储地址之间的一种映射关系,但是不能保证每个元素的关键字与函数值是一一对应的,因为极有可能出现对应于不同的元素,却计算出了相同的函数值。这就是哈希冲突。哈希函数的优劣往往影响着哈希冲突出现的概率。
给定100亿个整数,设计算法找到只出现一次的整数
给两个文件,分别有100亿个整数,我们只有1G内存,如何找到两个文件交集
1个文件有100亿个int,1G内存,设计算法找到出现次数不超过2次的所有整数
在海量数据处理中,哈希的大小往往还是不能满足我们的需求。也就衍生出了位图。
Bit-map
Bit-map(位图)的基本原理是使用数组中某一字节几位的单元来表示某些元素是否存在,其思想和哈希类似。通过数组下标,和对单独的位操作来实现映射。关系如判断数字是否存在,它适用于海量数据的快速查找、判重、删除等。
典型的判断在或者不在的数据用位图就很好。给每个数据简单1个位或者两个位来完成映射对应。判断出现1-3次用两个位2²就能够完成映射。
虽然我们分析题100亿很大啊,按照我们之间的说法。100亿个整形类型数据需要大约16G存储,但是利用哈希思想转换。我们需要表示也就是整形类型范围个数,每个数出现的次数不定。没有要求我们统计次数,只是要我们找出现一次的两次的那就容易多了两个位就可以完成。代码实现:
int index=Key/16;//int 32位 2位表示一个数据,表示范围则是16个
int num=(key%16)*2;//2位表示一个数据,那么这个数据具体在的位置
a[index]&=~(11<<num);//将num开始的连续两位清零
a[index]|=(x<<num);//再将num开始的连续两位设置成你需要的范围内次
//在通过按位遍历便可以找到符合要求的数据
通过分析我们知道按位图来处理数据一个数据占据两位, 4G / 16=2³² /16=1G内存就完成了任务。若只判断在或者不在 500M内存将可以完成判断。
文件求交集更是利用这个思想,建一个位图,判断文件的数存在与否,在用这个位图和另一个文件比对。
- 给一个超过100G大小的log file, log中存着IP地址, 设计算法找到出现次数最多的IP地址?
找出现次数的最多的数据,是典型的TOP K问题。
只不过我们分析题知道这是 100G 大小的 文件 中的数据。
在结合上面的位图、哈希,好像都不太符合。首先IP就不是简单的几位能表示的,所以我们再介绍大数据文件比较常用的方法。
分割
通过hash函数将大文件分解成有限个大小不均等的小文件。在对小文件进行操作。这种分割保证了相同的数据分到了同一文件中。
堆
是一种树形数据结构,每个结点都有一个值,而通常所说的堆,一般是指二叉堆。在堆中,以大顶堆为例,堆的根结点的值最大,且根结点的两个子树也是一个大堆,基于以上特点,堆适用于海量数据求前N大(用小顶堆)或者前N小(用大顶堆)数问题,其中N一般比较小。
100G的文件,我们觉得便于处理的文件大小大约在1G左右,但由于Hash函数是非均分的,所以我们保守分割1000个文件。

给两个文件,分别有100亿个query,我们只有1G内存,如何找到两个文件交集?分别给出精确算法和近似算法
如何扩展BloomFilter使得它支持删除元素的操作
如何扩展BloomFilter使得它支持计数操作
根据我们上面几个题的分析,我们这几个文件,也就都不难有思路。
1.首先看文件数据大小,再看内存限制。如果不能直接适用于某种数据结构,分割。通过哈希函数不均等分割成有限个符合要求大小个小文件。
2判断现文件适用于 那种数据结构解决问题。分析处理。
精确算法,就可以对分割好的小文件,在进行哈希操作。因为是100亿个query我们可以建哈希桶,通过特定位置链上query的方法,在完成一个文件的划分整理,再和另一个文件比对。
BloomFilter
如果想要判断一个元素是不是在一个集合里,一般想到的是将所有元素保存起来,然后通过比较确定。链表,树等等数据结构都是这种思路。但是随着集合中元素的增加,我们需要的存储空间越来越大,检索速度也越来越慢(O(n),O(logn))。不过世界上还有一种叫作散列表(又叫哈希表,Hash table)的数据结构。它可以通过一个Hash函数将一个元素映射成一个位阵列(Bit array)中的一个点。这样一来,我们只要看看这个点是不是1就可以知道集合中有没有它了。布隆过滤器通过特有的func函数选择3或几个位置共同判断一个数据是否存在来减少哈希冲突所导致的误判。其底层可以说就是一个位图。

布隆过滤器就是一个判断字符串等非简单数字数据在或者不在一个比较优的算法思想。但是他依然只是近似算法,因为他没有避免冲突,只是减少了冲突。
但是由于布隆过滤器是使用多个位共同判断一个数据的存在与否,也就同时意味着,不能够轻易删除。
这也就引申出我们的下一个问题。如果支持删除,计数。那么就要求我们扩大表示一个数据的单元大小来实现计数,1位能表示0/1及存在1次或者不存在,扩大位则就可以扩大表示次数范围,1一般可以扩大到1个字节。
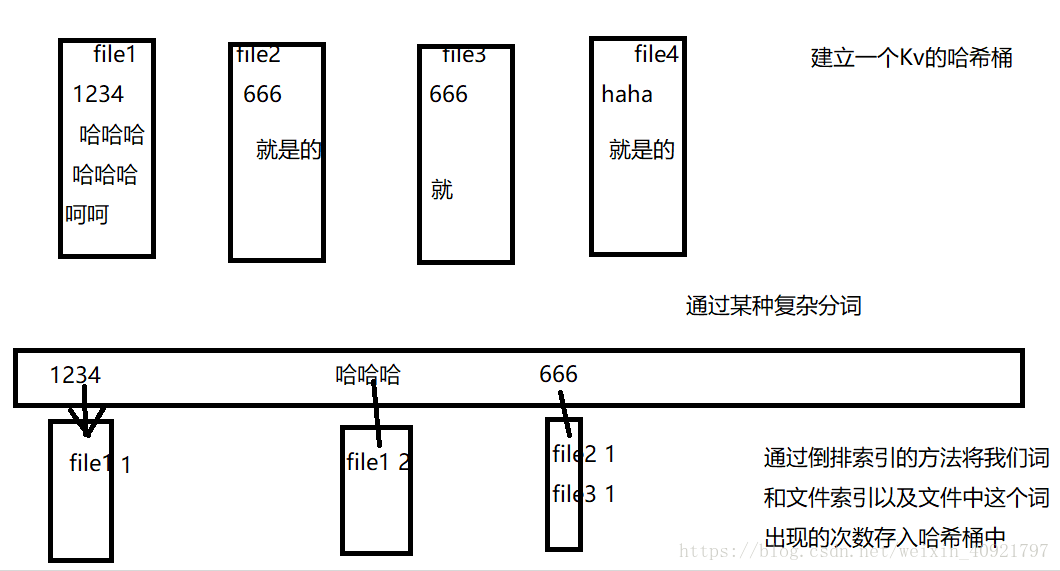
给上千个文件,每个文件大小为1K—100M。给n个设计算法对每个词找到所有包含它的文件,你只有100K内存
这个题让我想到了搜索引擎,一个文件通过分词算法,把文件拆分成多个词,在通过词索引找到与之相关联的文件。
倒排索引
倒排索引源于实际应用中需要根据属性的值来查找记录。这种索引表中的每一项都包括一个属性值和具有该属性值的各记录的地址。由于不是由记录来确定属性值,而是由属性值来确定记录的位置,因而称为倒排索引(inverted index)。带有倒排索引的文件我们称为倒排索引文件,简称倒排文件(inverted file)。
文档是有许多的单词组成的,其中每个单词也可以在同一个文档中重复出现很多次,当然,同一个单词也可以出现在不同的文档中。
正排索引是通过文档对单词经行操作而倒排索引则是通过单词对文档操作操作。
倒排列表用来记录有哪些文档包含了某个单词。一般在文档集合里会有很多文档包含某个单词,每个文档会记录文档编号(DocID),单词在这个文档中出现的次数(TF)及单词在文档中哪些位置出现过等信息,这样与一个文档相关的信息被称做倒排索引项(Posting),包含这个单词的一系列倒排索引项形成了列表结构,这就是某个单词对应的倒排列表。
通过我的小分析,希望也可以同样帮到被同样问题困扰有需求了解的你,你,你,你,你。