以下总结的全是单机爬取的应对反爬策略
1、设置爬取速度,由于爬虫发送请求的速度比较快,会对服务器造成一定的影响,尽可能控制爬取速度,做到文明爬取
2、重启路由器。并不是指物理上的插拔路由器,而是指模拟路由器重启时发送的表单。登陆自己的路由器,根据路由器的重启特点进行模拟,如果觉得模拟请求麻烦,那就通过selenium+chromedriver直接点击重启,前提是路由器本身是获得动态IP的
3、设置请求代理,不过代理不是非常稳定,并且有一部分代理不是真正的高匿代理,只是它自己这么写
4、多主机策略,这种策略目前看来比较可靠,一般一些网站会部署许多服务器,而我们在本机上ping网站,由于宽带运营商的原因,往往只能访问到固定的一个服务器,拿豆瓣做例子,本机ping豆瓣:

但豆瓣本身有三台服务器(我知道的),通过http://tool.chinaz.com/dns/?type=1&host=&ip= 进行查询:
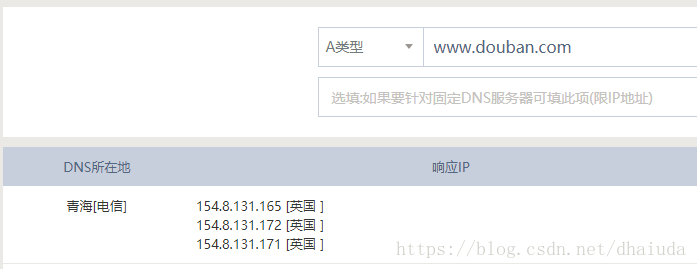
本机只访问了其中一台服务器而已,利用postman进行验证:
1、
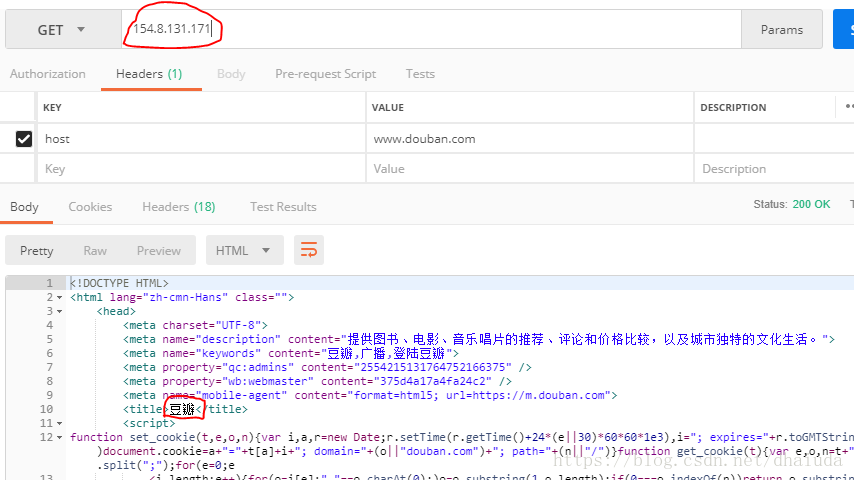
2、
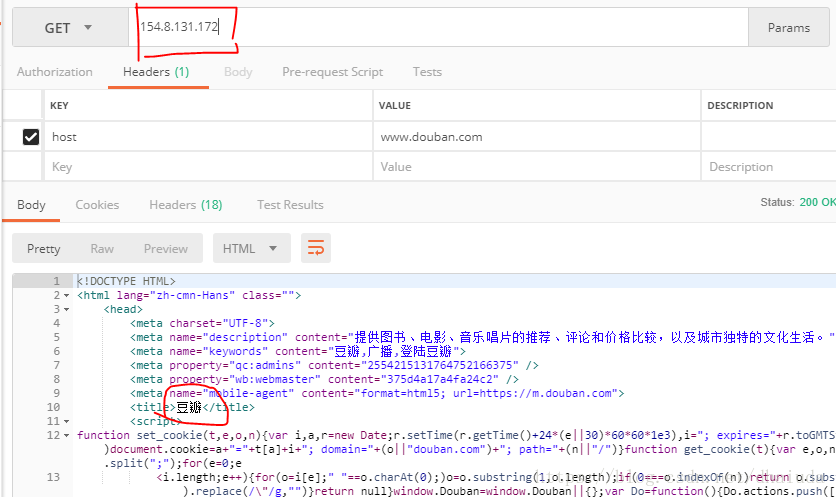
3、
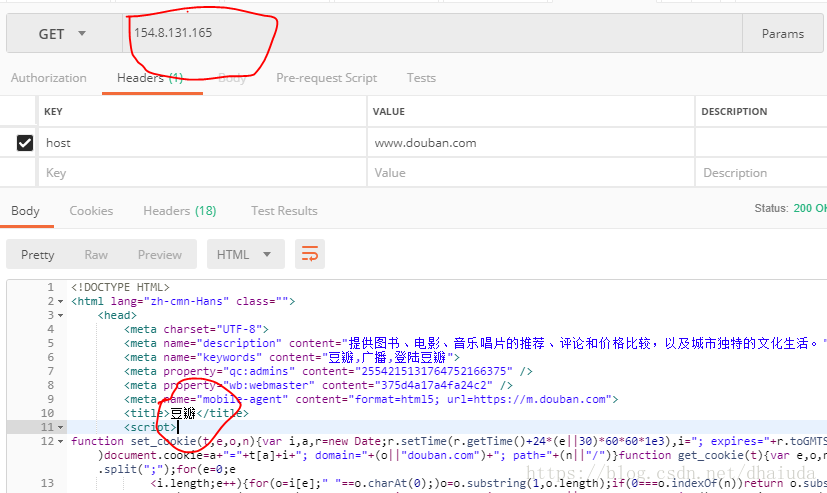
豆瓣本身没有配置IP访问时的virtualhost,通过IP访问服务器一定要在http头部指明host:www.douban.com,python3.6使用urllib访问特定IP地址的方式:
from urllib import request
header={
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Accept-Encoding': 'br',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive',
'Content-Length': '70',
'Content-Type': 'application/x-www-form-urlencoded',
'Host': 'www.douban.com',
'Origin': 'https://www.douban.com',
'Referer': 'https://www.douban.com/',
'Upgrade-Insecure-Requests': '1',
#'User-Agent': 'User-Agent:Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0;'
#'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:34.0) Gecko/20100101 Firefox/34.0'
}
req=request.Request('http://154.8.131.171',headers=header)这种策略的并行性也比较高,在单IP的情况下,通过多进程爬取同一台服务器上的网站被禁的可能性比较大,拿上面的例子来说,我们可以启动三个进程分别访问豆瓣的三台主机,提高爬取速度
5、频繁更改user-agent
6、有些网站对于某些IP地址不会做过多限制,例如学校里的公网IP,因为学校人数多,访问量大没什么奇怪,(虽然我学校公网IP貌似有限制............