一、背景
前两天写了一个简单的Python脚本,用来定期爬取我的 CSDN 账号下的 博客文章,脚本在定时任务上也成功运行了一段时间,但是最近发现,脚本运行有时候会失败,因为脚本写的比较简单,没有输出错误日志,所以定位了好久没有啥发现。今天脚本运行失败后,我再次手动运行,发现脚本中的接口调用 接口 status_code = 521,res.text 内容是html包裹了的压缩且加密了的JavaScript脚本,(为了方便查看我格式化了下)内容如下:
<html>
<body>
<script language="javascript">
window.onload = setTimeout("dr(175)", 200);
function dr(OB) {
var qo, mo = "",
no = "",
oo = [0xbb, 0x9e, 0x1f, 0x4a, 0x87, 0xdc, 0x59, 0x86, 0xdc, 0x19, 0x8f, 0xda, 0x87, 0xde, 0x16, 0x49, 0x9a, 0xc7, 0x0a, 0x8f, 0x1f, 0x4f, 0x8b, 0xc7, 0xd6, 0x0f, 0x4a, 0x71, 0xb2, 0xfe, 0x29, 0x74, 0xa8, 0xf5, 0x3f, 0x79, 0xe7, 0x31, 0x67, 0xb2, 0xff, 0x65, 0xbe, 0x38, 0x63, 0xff, 0x29, 0xa3, 0x75, 0xa1, 0x3f, 0x6d, 0xe5, 0x63, 0x72, 0xbe, 0x38, 0xb5, 0x30, 0x7a, 0x4b, 0xc6, 0x42, 0xda, 0x5a, 0xd9, 0xb1, 0x2c, 0xac, 0x2e, 0x7a, 0xef, 0xa8, 0x26, 0xa6, 0xef, 0x6b, 0x00, 0x7b, 0xf7, 0x78, 0xa3, 0xf0, 0x66, 0xbe, 0xe7, 0x32, 0xaf, 0x2b, 0xc0, 0x07, 0x9f, 0xc8, 0x41, 0x8e, 0xd8, 0xa4, 0x40, 0x6c, 0xba, 0x3a, 0xb8, 0xf0, 0x72, 0xec, 0x62, 0xfb, 0x7a, 0x82, 0x03, 0x82, 0x1b, 0x9b, 0x18, 0xd4, 0x50, 0xd0, 0x51, 0xd4, 0x5d, 0xd2, 0x20, 0x60, 0x98, 0xc9, 0x04, 0x8f, 0xdc, 0x18, 0x9d, 0xb8, 0xf5, 0x76, 0xac, 0x21, 0xa9, 0x23, 0xa3, 0x58, 0xcd, 0xff, 0x3d, 0x73, 0xe8, 0x93, 0x0e, 0x89, 0x12, 0x8b, 0x04, 0xc1, 0x44, 0xdf, 0x5b, 0xdd, 0x56, 0x5e, 0xde, 0x47, 0x76, 0x8b, 0xa7, 0xd1, 0x55, 0xdd, 0x0a, 0x41, 0x96, 0xd8, 0x02, 0x53, 0x89, 0x0f, 0x85, 0xe7, 0x33, 0x6e, 0xba, 0xf0, 0x67, 0xfa, 0x31, 0x7e, 0xba, 0x3e, 0xa6, 0xda, 0x13, 0x5c, 0x98, 0xc8, 0x4e, 0x00, 0x78, 0xfb, 0x64, 0x9f, 0xcc, 0x65, 0xb0, 0xed, 0x28, 0x75, 0xe4, 0x6f, 0xf2, 0x32, 0x63, 0xb9, 0xe5, 0x8c, 0xc3, 0x03, 0x99, 0xc5, 0x1d, 0x60, 0x8b, 0xc8, 0x1e, 0x4b, 0x81, 0xcc, 0x09, 0x9f, 0xd3, 0x0b, 0x56, 0x5d, 0x86, 0xc2, 0x14, 0x4b, 0x81, 0x8f, 0x15, 0x84, 0x1c, 0x47, 0x9e, 0x1b, 0x50, 0x85, 0xc2, 0x19, 0x4a, 0x36, 0x72, 0xb3, 0x2b, 0x7b, 0xb2, 0x88, 0xdd, 0x0b, 0xa0, 0xc9, 0x02, 0x01, 0x52, 0xc9, 0x08, 0x81, 0x19, 0x24, 0x73, 0xc0, 0xfc, 0x72, 0xae, 0xbf, 0xe8, 0x33, 0xa8, 0xe4, 0x3c, 0x4a, 0x86, 0xcf, 0x04, 0x8b, 0xc8, 0x89, 0xc4, 0x12, 0x4c, 0x82, 0xcb, 0x9f, 0xd4, 0x02, 0x87, 0xb1, 0x2b, 0x78, 0xf1, 0x6a, 0xe7, 0x80, 0xff, 0xae, 0x29, 0xaa, 0xd6, 0x3b];
qo = "qo=303; do{oo[qo]=(-oo[qo])&0xff; oo[qo]=(((oo[qo]>>5)|((oo[qo]<<3)&0xff))-201)&0xff;} while(--qo>=2);";
eval(qo);
qo = 302;
do {
oo[qo] = (oo[qo] - oo[qo - 1]) & 0xff;
} while (-- qo >= 3 );
qo = 1;
for (;;) {
if (qo > 302) break;
oo[qo] = ((((((oo[qo] + 112) & 0xff) + 80) & 0xff) << 5) & 0xff) | (((((oo[qo] + 112) & 0xff) + 80) & 0xff) >> 3);
qo++;
}
po = "";
for (qo = 1; qo < oo.length - 1; qo++) if (qo % 6) po += String.fromCharCode(oo[qo] ^ OB);
eval("qo=eval;qo(po);");
}
</script>
</body>
</html>
经在网络上查找了一番,得知这是一些网站用来反爬虫的策略(js+cookie)。
具体来讲就是,当访问某个接口或页面时,如果没有携带的正确的cookie,就会返回上边的 521状态的页面,该页面中的js代码,就是用来生成真正需要cookie的。原因也找到了,有没有解决方案呢?既然决定写这篇文章了,肯定是有了解决方案,O(∩_∩)O哈哈~
二、反反爬虫
反爬虫策略有很多中,反反爬虫的方案也有很多,这里我只总结上述我遇到的情况。
1. 获取521页面内容
获取res.status_code=521状态时的响应内容,用于提取生成cookie的js脚本
import requests
import re
import js2py
# 创建一个 session会话,通过 session自动管理cookie内容
session = requests.Session()
# 将接口通用的 headers,放到 session中进行管理,这样就不用在下边所有接口处写了,而且如果有需要也方便设置为动态的 UA
# 这里建议将 User-Agent 设置为浏览器的,python脚本默认会使用 "User-Agent": "python-requests/2.31.0",有些反爬虫策略是会检测 UA 来反爬的
session.headers.update({
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36 SLBrowser/8.0.1.1171 SLBChan/12"})
csdn_url = "https://blog.csdn.net/B11050729"
csdn_params = {
"type":"blog"
}
csdn_headers = {
"Accept":"text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9"
}
# 不带 Cookie 请求页面,
res = session.get(url=csdn_url,params=csdn_params,headers=csdn_headers)
# print(res.text) # 查看接口响应文本内容
# print(res.status_code) # 查看接口响应状态码
# print(res.request.headers) # 查看接口请求头内容
# print(res.cookies) # 查看生成的Cookie信息(RequestsCookieJar对象)
# print(res.headers) # 查看接口响应头内容
# print(requests.utils.dict_from_cookiejar(session.cookies)) # 查看生成的Cookie信息(转为了dict格式)
2. 获取Cookie
获取js脚本,并执行脚本获取cookie,然后将cookie更新到session会话
# 这里为了调试,将521状态页面内容写死到代码里,实际中js代码是动态的生成的
# js_page_text = res.text
js_page_text = '<html><body><script language="javascript"> window.οnlοad=setTimeout("dr(175)", 200); function dr(OB) {var qo, mo="", no="", oo = [0xbb,0x9e,0x1f,0x4a,0x87,0xdc,0x59,0x86,0xdc,0x19,0x8f,0xda,0x87,0xde,0x16,0x49,0x9a,0xc7,0x0a,0x8f,0x1f,0x4f,0x8b,0xc7,0xd6,0x0f,0x4a,0x71,0xb2,0xfe,0x29,0x74,0xa8,0xf5,0x3f,0x79,0xe7,0x31,0x67,0xb2,0xff,0x65,0xbe,0x38,0x63,0xff,0x29,0xa3,0x75,0xa1,0x3f,0x6d,0xe5,0x63,0x72,0xbe,0x38,0xb5,0x30,0x7a,0x4b,0xc6,0x42,0xda,0x5a,0xd9,0xb1,0x2c,0xac,0x2e,0x7a,0xef,0xa8,0x26,0xa6,0xef,0x6b,0x00,0x7b,0xf7,0x78,0xa3,0xf0,0x66,0xbe,0xe7,0x32,0xaf,0x2b,0xc0,0x07,0x9f,0xc8,0x41,0x8e,0xd8,0xa4,0x40,0x6c,0xba,0x3a,0xb8,0xf0,0x72,0xec,0x62,0xfb,0x7a,0x82,0x03,0x82,0x1b,0x9b,0x18,0xd4,0x50,0xd0,0x51,0xd4,0x5d,0xd2,0x20,0x60,0x98,0xc9,0x04,0x8f,0xdc,0x18,0x9d,0xb8,0xf5,0x76,0xac,0x21,0xa9,0x23,0xa3,0x58,0xcd,0xff,0x3d,0x73,0xe8,0x93,0x0e,0x89,0x12,0x8b,0x04,0xc1,0x44,0xdf,0x5b,0xdd,0x56,0x5e,0xde,0x47,0x76,0x8b,0xa7,0xd1,0x55,0xdd,0x0a,0x41,0x96,0xd8,0x02,0x53,0x89,0x0f,0x85,0xe7,0x33,0x6e,0xba,0xf0,0x67,0xfa,0x31,0x7e,0xba,0x3e,0xa6,0xda,0x13,0x5c,0x98,0xc8,0x4e,0x00,0x78,0xfb,0x64,0x9f,0xcc,0x65,0xb0,0xed,0x28,0x75,0xe4,0x6f,0xf2,0x32,0x63,0xb9,0xe5,0x8c,0xc3,0x03,0x99,0xc5,0x1d,0x60,0x8b,0xc8,0x1e,0x4b,0x81,0xcc,0x09,0x9f,0xd3,0x0b,0x56,0x5d,0x86,0xc2,0x14,0x4b,0x81,0x8f,0x15,0x84,0x1c,0x47,0x9e,0x1b,0x50,0x85,0xc2,0x19,0x4a,0x36,0x72,0xb3,0x2b,0x7b,0xb2,0x88,0xdd,0x0b,0xa0,0xc9,0x02,0x01,0x52,0xc9,0x08,0x81,0x19,0x24,0x73,0xc0,0xfc,0x72,0xae,0xbf,0xe8,0x33,0xa8,0xe4,0x3c,0x4a,0x86,0xcf,0x04,0x8b,0xc8,0x89,0xc4,0x12,0x4c,0x82,0xcb,0x9f,0xd4,0x02,0x87,0xb1,0x2b,0x78,0xf1,0x6a,0xe7,0x80,0xff,0xae,0x29,0xaa,0xd6,0x3b];qo = "qo=303; do{oo[qo]=(-oo[qo])&0xff; oo[qo]=(((oo[qo]>>5)|((oo[qo]<<3)&0xff))-201)&0xff;} while(--qo>=2);"; eval(qo);qo = 302; do { oo[qo] = (oo[qo] - oo[qo - 1]) & 0xff; } while (-- qo >= 3 );qo = 1; for (;;) { if (qo > 302) break; oo[qo] = ((((((oo[qo] + 112) & 0xff) + 80) & 0xff) << 5) & 0xff) | (((((oo[qo] + 112) & 0xff) + 80) & 0xff) >> 3); qo++;}po = ""; for (qo = 1; qo < oo.length - 1; qo++) if (qo % 6) po += String.fromCharCode(oo[qo] ^ OB);eval("qo=eval;qo(po);");} </script> </body></html>'
# status_code = res.status_code
status_code = 521
# 前面也说了,CSDN 网站的这个反爬虫策略,有时候是开启的,有时候是关闭的
# 这里通过 status_code 状态码,做下兼容处理
if status_code == 521:
# 1)通过正则表达式,提取脚本内容(函数调用和函数声明,栗子中 函数调用 dr(175),函数声明 function dr(OB) { var qo, ...)
js_ydclearance = re.findall('window.οnlοad=setTimeout\("(.+?)", 200\);\s*(.+?)\s*</script> ', js_page_text)
# print(js_ydclearance)
# 函数dr声明中,由于qo=eval,那么等同于最终调用了eval(po),真正js在"po"中
# 2)把 `eval("qo=eval;qo(po);")` 替换为 return po
func_str = js_ydclearance[0][1]
func_str = func_str.replace('eval("qo=eval;qo(po);")', 'return po')
# print(func_str)
# 3)获取执行js的环境,js2py 第3方库,用于执行js,自行安装
context = js2py.EvalJs()
# 4)加载(执行) func_str
context.execute(func_str)
# 5)执行这个方法, 生成我们需要的js
context.execute('code = {};'.format(js_ydclearance[0][0]))
# 打印最终生成的代码
# print(context.code)
# 6)获取生成的Cookie
cookie_str = re.findall("document.cookie='(.+?); ", context.code)[0]
print(cookie_str)
# 7)在Session中添加Cookie
session.cookies.set("https_ydclearance", cookie_str.split("=")[1], path='/', domain='.csdn.net')
print(session.cookies)
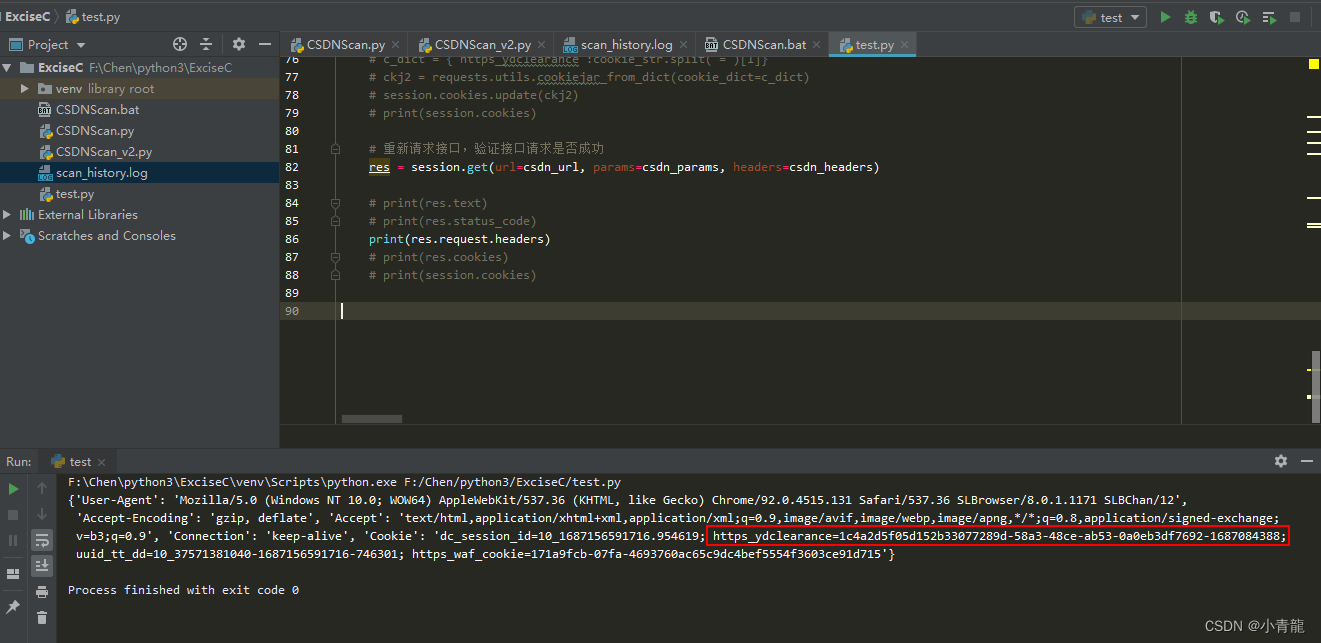
3. 验证新Cookie,是否有效
# 重新请求接口,验证接口请求是否成功
res = session.get(url=csdn_url, params=csdn_params, headers=csdn_headers)
# print(res.text)
# print(res.status_code)
print(res.request.headers)
# print(res.cookies)
# print(session.cookies)
由于,我在写这个文章的时候,CSDN 网站的反爬虫策略 是关闭了的,所以这里就没办法直接验证了,就看下 res.request.headers 的 Cookie 信息中有没有 https_ydclearance 就可以了,有的话就证明成功了
4. 完整示例代码
import requests
import re
import js2py
# 创建一个session会话,通过session自动管理cookie内容
session = requests.Session()
# 将接口通用的headers,放到session中进行管理
session.headers.update({
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36 SLBrowser/8.0.1.1171 SLBChan/12"})
csdn_url = "https://blog.csdn.net/B11050729"
csdn_params = {
"type":"blog"
}
csdn_headers = {
"Accept":"text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9"
}
# 不带 Cookie 请求页面,
res = session.get(url=csdn_url,params=csdn_params,headers=csdn_headers)
# print(res.text) # 查看接口响应文本内容
# print(res.status_code) # 查看接口响应状态码
# print(res.request.headers) # 查看接口请求头内容
# print(res.cookies) # 查看生成的Cookie信息(RequestsCookieJar对象)
# print(res.headers) # 查看接口响应头内容
# print(requests.utils.dict_from_cookiejar(session.cookies)) # 查看生成的Cookie信息(转为了dict格式)
# 这里为了调试,将521状态页面内容写死到代码里,实际中js代码是动态的生成的,通过 res.text 获取
# js_page_text = res.text
js_page_text = '<html><body><script language="javascript"> window.οnlοad=setTimeout("dr(175)", 200); function dr(OB) {var qo, mo="", no="", oo = [0xbb,0x9e,0x1f,0x4a,0x87,0xdc,0x59,0x86,0xdc,0x19,0x8f,0xda,0x87,0xde,0x16,0x49,0x9a,0xc7,0x0a,0x8f,0x1f,0x4f,0x8b,0xc7,0xd6,0x0f,0x4a,0x71,0xb2,0xfe,0x29,0x74,0xa8,0xf5,0x3f,0x79,0xe7,0x31,0x67,0xb2,0xff,0x65,0xbe,0x38,0x63,0xff,0x29,0xa3,0x75,0xa1,0x3f,0x6d,0xe5,0x63,0x72,0xbe,0x38,0xb5,0x30,0x7a,0x4b,0xc6,0x42,0xda,0x5a,0xd9,0xb1,0x2c,0xac,0x2e,0x7a,0xef,0xa8,0x26,0xa6,0xef,0x6b,0x00,0x7b,0xf7,0x78,0xa3,0xf0,0x66,0xbe,0xe7,0x32,0xaf,0x2b,0xc0,0x07,0x9f,0xc8,0x41,0x8e,0xd8,0xa4,0x40,0x6c,0xba,0x3a,0xb8,0xf0,0x72,0xec,0x62,0xfb,0x7a,0x82,0x03,0x82,0x1b,0x9b,0x18,0xd4,0x50,0xd0,0x51,0xd4,0x5d,0xd2,0x20,0x60,0x98,0xc9,0x04,0x8f,0xdc,0x18,0x9d,0xb8,0xf5,0x76,0xac,0x21,0xa9,0x23,0xa3,0x58,0xcd,0xff,0x3d,0x73,0xe8,0x93,0x0e,0x89,0x12,0x8b,0x04,0xc1,0x44,0xdf,0x5b,0xdd,0x56,0x5e,0xde,0x47,0x76,0x8b,0xa7,0xd1,0x55,0xdd,0x0a,0x41,0x96,0xd8,0x02,0x53,0x89,0x0f,0x85,0xe7,0x33,0x6e,0xba,0xf0,0x67,0xfa,0x31,0x7e,0xba,0x3e,0xa6,0xda,0x13,0x5c,0x98,0xc8,0x4e,0x00,0x78,0xfb,0x64,0x9f,0xcc,0x65,0xb0,0xed,0x28,0x75,0xe4,0x6f,0xf2,0x32,0x63,0xb9,0xe5,0x8c,0xc3,0x03,0x99,0xc5,0x1d,0x60,0x8b,0xc8,0x1e,0x4b,0x81,0xcc,0x09,0x9f,0xd3,0x0b,0x56,0x5d,0x86,0xc2,0x14,0x4b,0x81,0x8f,0x15,0x84,0x1c,0x47,0x9e,0x1b,0x50,0x85,0xc2,0x19,0x4a,0x36,0x72,0xb3,0x2b,0x7b,0xb2,0x88,0xdd,0x0b,0xa0,0xc9,0x02,0x01,0x52,0xc9,0x08,0x81,0x19,0x24,0x73,0xc0,0xfc,0x72,0xae,0xbf,0xe8,0x33,0xa8,0xe4,0x3c,0x4a,0x86,0xcf,0x04,0x8b,0xc8,0x89,0xc4,0x12,0x4c,0x82,0xcb,0x9f,0xd4,0x02,0x87,0xb1,0x2b,0x78,0xf1,0x6a,0xe7,0x80,0xff,0xae,0x29,0xaa,0xd6,0x3b];qo = "qo=303; do{oo[qo]=(-oo[qo])&0xff; oo[qo]=(((oo[qo]>>5)|((oo[qo]<<3)&0xff))-201)&0xff;} while(--qo>=2);"; eval(qo);qo = 302; do { oo[qo] = (oo[qo] - oo[qo - 1]) & 0xff; } while (-- qo >= 3 );qo = 1; for (;;) { if (qo > 302) break; oo[qo] = ((((((oo[qo] + 112) & 0xff) + 80) & 0xff) << 5) & 0xff) | (((((oo[qo] + 112) & 0xff) + 80) & 0xff) >> 3); qo++;}po = ""; for (qo = 1; qo < oo.length - 1; qo++) if (qo % 6) po += String.fromCharCode(oo[qo] ^ OB);eval("qo=eval;qo(po);");} </script> </body></html>'
# status_code = res.status_code
status_code = 521
# 前面也说了,CSDN 网站的这个反爬虫策略,有时候是开启的,有时候是关闭的
# 这里通过 status_code 状态码,做下兼容处理
if status_code == 521:
# 1)通过正则表达式,提取脚本内容(函数调用和函数声明,栗子中 函数调用 dr(175),函数声明 function dr(OB) { var qo, ...)
js_ydclearance = re.findall('window.οnlοad=setTimeout\("(.+?)", 200\);\s*(.+?)\s*</script> ', js_page_text)
# print(js_ydclearance)
# 函数dr声明中,由于qo=eval,那么等同于最终调用了eval(po),真正js在"po"中
# 2)把 `eval("qo=eval;qo(po);")` 替换为 return po
func_str = js_ydclearance[0][1]
func_str = func_str.replace('eval("qo=eval;qo(po);")', 'return po')
# print(func_str)
# 3)获取执行js的环境,js2py 第3方库,用于执行js,自行安装
context = js2py.EvalJs()
# 4)加载(执行) func_str
context.execute(func_str)
# 5)执行这个方法, 生成我们需要的js
context.execute('code = {};'.format(js_ydclearance[0][0]))
# 打印最终生成的代码
# print(context.code)
# 6)获取生成的Cookie
cookie_str = re.findall("document.cookie='(.+?); ", context.code)[0]
# print(cookie_str)
# 7)在Session中添加Cookie
# 在session中添加cookie 有几种方法
# 方法1,直接通过key设置,但不支持设置 path、domain
# session.cookies["https_ydclearance"] = cookie_str.split("=")[1]
# 方法2,通过set方法设置,支持设置 path、domain
session.cookies.set("https_ydclearance", cookie_str.split("=")[1], path='/', domain='.csdn.net')
# 方法3,通过 utils工具包里的 add_dict_to_cookiejar 方法设置,不支持设置 path、domain
# requests.utils.add_dict_to_cookiejar(session.cookies, {"https_ydclearance":cookie_str.split("=")[1]})
# 方法4,通过 RequestsCookieJar() 对象设置,可以设置 path、domain
# ckj1 = requests.sessions.RequestsCookieJar()
# ckj1.set('https_ydclearance', cookie_str.split("=")[1], path='/', domain='.csdn.net')
# session.cookies.update(ckj1)
# 方法5,通过 utils工具包里的 cookiejar_from_dict 方法设置,不支持设置 path、domain
# c_dict = {"https_ydclearance":cookie_str.split("=")[1]}
# ckj2 = requests.utils.cookiejar_from_dict(cookie_dict=c_dict)
# session.cookies.update(ckj2)
# print(session.cookies)
# 重新请求接口,验证接口请求是否成功
res = session.get(url=csdn_url, params=csdn_params, headers=csdn_headers)
# print(res.text)
# print(res.status_code)
print(res.request.headers)
# print(res.cookies)
# print(session.cookies)
三、总结
1)CSDN 网站的反爬虫策略,有时是打开的,有时是生效的,因此代码中根据 res.status_code == 521,判断反爬虫策略是否生效,即当接口 返回的状态码是 521 时,就获取js脚本,然后解析并执行脚本,生成cookie,进行反反爬虫
2)针对于 CSDN 使用的 js+cookie 的反爬虫策略,解决方案的重点代码在 【2.获取Cookie 】
参考文章:https://blog.csdn.net/welggy/article/details/115358013