数据的归一化
先放上宏毅大神的图,说明一下我们为什么要做数据的归一化

说明:x2的变化比较大,使用w2方向上就显得比较陡峭(梯度),学习率就不能设置得过大。
Batch Normalization

为什么要有batch normalization
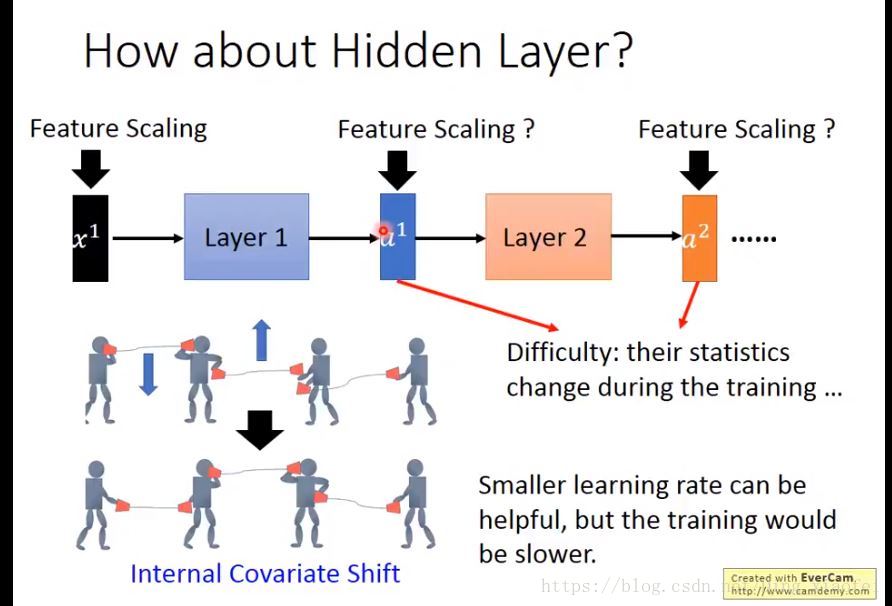
主要是避免internal covariate shift,如图所示,输出上下波动太大(如同第二个人)的话会影响整个模型的训练,第二个人告诉第二个人话筒放低点,第三个人告诉第二个人放高点,如果你的步长过大的话就会变成第二个图,跟没训练一样,所以最开始为了解决这样的状况,会考虑把学习率放小点,但这样网络就会变得比较慢。所以bn就可以把每一层的输出的变化都变小。训练也会变快,我们也就能训练更加深层的神经网络。
这边吴恩达的解释也是异曲同工:
Batch归一化减少了输入值改变的问题,它的确使这些值变得更稳定,神经网络的之后层就会有更坚实的基础。即使使输入分布改变了一些,它会改变得更少。它做的是当前层保持学习,当改变时,迫使后层适应的程度减小了,你可以这样想,它减弱了前层参数的作用与后层参数的作用之间的联系,它使得网络每层都可以自己学习,稍稍独立于其它层,这有助于加速整个网络的学习。
所以,希望这能带给你更好的直觉,重点是Batch归一化的意思是,尤其从神经网络后层之一的角度而言,前层不会左右移动的那么多,因为它们被同样的均值和方差所限制,所以,这会使得后层的学习工作变得更容易些。
Batch归一化还有一个作用,它有轻微的正则化效果。
测试时的batchnorm
我们使用指数平均的方法计算每一个batch的平均值