无重复字符的最长子串 (C++)
LeetCode No.3
给定一个字符串,找出不含有重复字符的最长子串的长度。
示例:
给定 "abcabcbb" ,没有重复字符的最长子串是 "abc" ,那么长度就是3。
给定 "bbbbb" ,最长的子串就是 "b" ,长度是1。
给定 "pwwkew" ,最长子串是 "wke" ,长度是3。请注意答案必须是一个子串,"pwke" 是 子序列 而不是子串。
看到这个问题,我首先想到的就是拿vector存下来最长的子串然后返回size就可以了
流程图:
重复这个流程,每次起始的位置都比原来靠后一个,这样就能找出最长的子串了
例如 abcabcbb
先扫描到了a 然后存进v里面
然后是 b 和 c 。那么现在v里面就有三个字符了
接下来又遇到了a ,那么新建一个 vector of char 继续上面的步骤
这样的话,对于短的还好,长一点的字符串简直就是灾难
复杂度基本为O(n^n)
推倒重来,这简直太慢了
翻cplusplus.com 发现vector的erase可以删除一个范围
那么思路改一下
总共只用一个vector,如果发现重复的字符,把当前vector的大小记录下来,然后删除重复字符之前的所有字符
例如tabcadebb
v里面一个一个存,直到第二个a的出现, 这时,存下来当前v的长度,也就是v = tabc = 4
这时候删掉a和a之前的所有字符 v = bc 然后把现在这个a记录到后面 v = bca
这样的话只需要重复一遍,而且代码十分容易理解
(原谅我根本看不懂leet-code 比我效率更高的代码,我才学了一个学期的基础c++课)
那么是时候放自己写的稀烂的代码啦
class Solution {
public:
int lengthOfLongestSubstring(string s) {
auto it1 = s.begin();
vector<char> v; //储存字符串的vector
int max = 0; //最后输出的最长的字符串的个数
int lin = 0; //字符串的个数(不一定是最长的)
while (it1 != s.end()) {
auto it3 = find(v.begin(), v.end(),*it1); //查询v里面有没有当前要插入的字符
if (it3 == v.end()) { //如果没有找到
v.push_back(*it1); //就把这个字符放在v的最后面
lin++; //并且让这个字符串的大小加一
}
else { //如果当前vector里面已经有这个字符了
if (max < lin) max = lin; //那么把lin存一下,如果之前已经有比lin长的字符串了,那么就不存
v.erase(v.begin(), it3+1); //把包括当前重复的字符和它以前的所有字符都删掉
v.push_back(*it1); //然后将刚刚的字符插在v的最后面
lin = v.size(); //lin等于新的vector的大小
}
it1++; //指针指向下一个字符
}
if (max < lin) max = lin; //确保max里面是最长的字符串的长度
return max;
}
};然后再加上leet code必备玄学加速代码(我根本不知道原理)
static const auto ban_io_sync = []()
{
std::ios::sync_with_stdio(false);
cin.tie(nullptr);
return 0;
}();当当当当
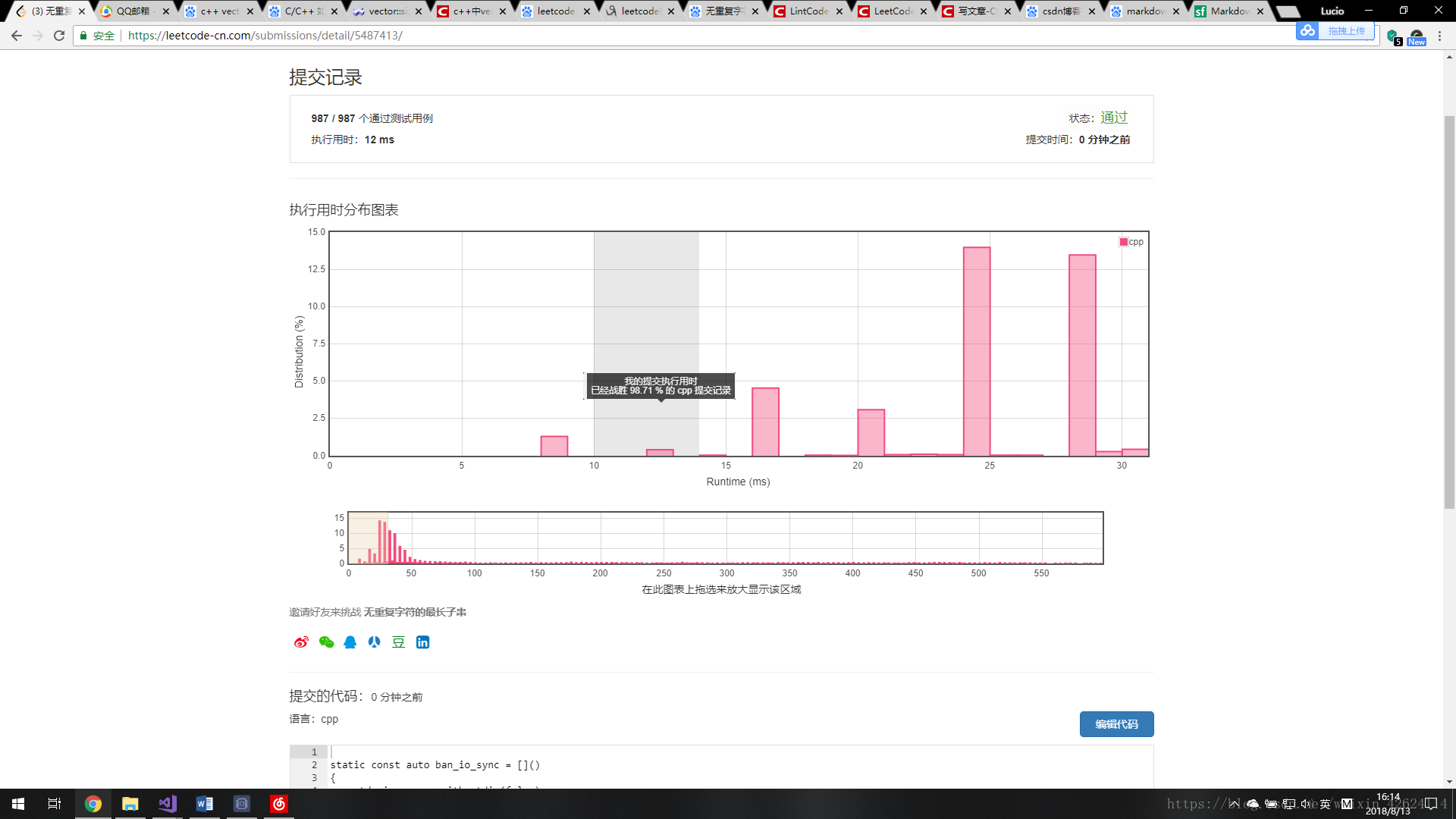
我用这么简单易懂的方法就完成啦
执行用时:12 ms
嘿嘿