leetcode之无重复字符的最长子串c++解法
给定一个字符串,请你找出其中不含有重复字符的 最长子串 的长度。
示例 1:
输入: "abcabcbb"
输出: 3
解释: 因为无重复字符的最长子串是 "abc",所以其长度为 3。
示例 2:
输入: "bbbbb"
输出: 1
解释: 因为无重复字符的最长子串是 "b",所以其长度为 1。
示例 3:
输入: "pwwkew"
输出: 3
解释: 因为无重复字符的最长子串是 "wke",所以其长度为 3。
请注意,你的答案必须是 子串 的长度,"pwke" 是一个子序列,不是子串。
方法一:暴力法
假设我们有一个函数 bool allUnique(string substring) ,如果子字符串中的字符都是唯一的,它会返回true,否则会返回false。 我们可以遍历给定字符串 s 的所有可能的子字符串并调用函数 allUnique。 如果事实证明返回值为true,那么我们将会更新无重复字符子串的最大长度的答案。
为了枚举给定字符串的所有子字符串,我们需要枚举它们开始和结束的索引。假设开始和结束的索引分别为 ii 和 j。那么我们有 0≤i<j≤n (这里的结束索引 j 是按惯例排除的)。因此,使用 ii 从0到 n - 1以及 j 从 i+1到 n 这两个嵌套的循环,我们可以枚举出 s 的所有子字符串。
时间复杂度:O(n3)。要验证索引范围在[i,j)内的字符是否是唯一的,需要检查该范围中的所有字符(遍历一遍插入哈希表中,哈希表查找需要O(1)的时间),因此将花费O(j-i)的时间。对于对于给定的 i,对于所有 j \in [i+1, n]j∈[i+1,n] 所耗费的时间总和为:
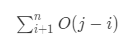
因此,执行所有步骤耗去的时间总和为:
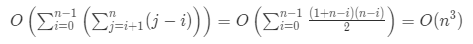
空间复杂度:O(min(n, m)),所需的额外空间取决于哈希表中存储的元素数量以及字符集/字母 m 的大小,该表最多需要存储n个元素。
class Solution{
public:
int lengthOfLongestSubstring(string s){
int ans = 0;
//遍历所有无重复字符的子串
for(int i = 0; i<s.size(); i++)
for(int j=i+1; j<=s.size(); j++){
if(allUnique(s,i,j))
ans = max(ans,j-i); //保存最长子串的长度
}
return ans;
}
bool allUnique(string s, int begin, int end){
map<char,int> hash;
for(int i=begin; i<end; i++){
if(hash.find(s[i])!=hash.end())
return false; //存在重复字符则返回false
hash[s[i]]=i;
}
return true;
}
};
方法二:滑动窗口
我们使用 哈希表 将字符存储在当前窗口 [i, j)(最初 j = i)中。 然后我们向右侧滑动索引 j,如果它不在 哈希表 中,我们会继续滑动 j。直到 s[j] 已经存在于 哈希表 中。此时,我们找到的没有重复字符的最长子字符串将会以索引 i 开头。如果我们对所有的 i 这样做,就可以得到答案。即,当 s[j] 已经存在于 哈希表 中时,清空哈希表,然后将 i 向后移一位再重复上述操作。
时间复杂度:O(2n) = O(n),在最糟糕的情况下,每个字符将被 i 和 j 访问两次。
空间复杂度:O(min(m, n))
class Solution {
public:
int lengthOfLongestSubstring(string s) {
map<char,int> hash;
int ans = 0;
int i = 0;
int j = 0;
int n = s.length();
while(i<n && j<n){
if(hash.find(s[j])==hash.end()){
hash[s[j++]]=j; // 等价于hash[s[j]]=j;j++; j自增必须要在下一条语句中的j-i之前
ans=max(ans,j-i);
}
else
hash.erase(s[i++]); // 根据键值删除哈希表中元素。该条语句等价于hash.erase(s[i]);i++; 每回向右滑动一位(此处可以改善,见方法三)
}
return ans;
}
};
方法三:优化的滑动窗口
基于上一个方法,当我们找到重复的字符时,我们可以立即跳过该窗口。也就是说,如果 s[j]在 [i, j)范围内有与 j’重复的字符,我们不需要逐渐增加 ii。 我们可以直接跳过 [i,j’] 范围内的所有元素,并将 i变为 j’ + 1。
时间复杂度:O(n),索引 j将会迭代 n次。
空间复杂度:O(min(m,n))。
class Solution {
public:
int lengthOfLongestSubstring(string s) {
map<char,int> hash;
int ans = 0;
int n= s.size();
for(int i= 0, j=0;j<n;j++){
if(hash.find(s[j])!=hash.end())
i=max(hash.find(s[j])->second+1,i); //当发现重复字符时,i直接跳到重复字符的下一位,改进了方法2中一个字符一个字符滑动窗口的方法
ans=max(ans,j-i+1);
hash[s[j]]=j;
}
return ans;
}
};