1.二分查找
二分查找也称为折半查找,它是一种效率较高的查找方法。二分查找的使用前提是线性表已经按照大小排好了序。这种方法充分利用了元素间的次序关系,采用分治策略。基本原理是:首先在有序的线性表中找到中值,将要查找的目标与中值进行比较,如果目标小于中值,则在前半部分找,如果目标小于中值,则在后半部分找;假设在前半部分找,则再与前半部分的中值相比较,如果小于中值,则在中值的前半部分找,如果大于中值,则在后半部分找。以此类推,直到找到目标为止。
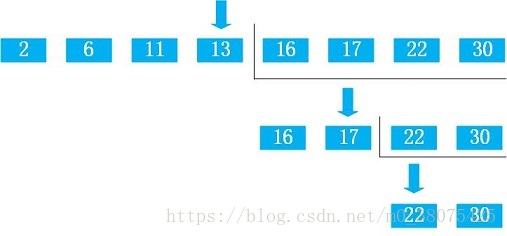
假设我们要在 2,6,11,13,16,17,22,30中查找22,上图所示,则查找步骤为:
- 首先找到中值:中值为13(下标:int middle = (0+7)/2),将22与13进行比较,发现22比13大,则在13的后半部分找;
- 在后半部分 16,17,22,30中查找22,首先找到中值,中值为17(下标:int middle=(0+3)/2),将22与17进行比较,发现22比17大,则继续在17的后半部分查找;
- 在17的后半部分 22,30查找22,首先找到中值,中值为22(下标:int middle=(0+1)/2),将22与22进行比较,查找到结果。
二分查找大大降低了比较次数,二分查找的时间复杂度为:,即
。
示例代码:
public class BinarySearch {
public static void main(String[] args) {
int arr[] = {2, 6, 11, 13, 16, 17, 22, 30};
System.out.println("非递归结果,22的位置为:" + binarySearch(arr, 22));
System.out.println("递归结果,22的位置为:" + binarySearch(arr, 22, 0, 7));
}
//非递归
static int binarySearch(int[] arr, int res) {
int low = 0;
int high = arr.length-1;
while(low <= high) {
int middle = (low + high)/2;
if(res == arr[middle]) {
return middle;
}else if(res <arr[middle]) {
high = middle - 1;
}else {
low = middle + 1;
}
}
return -1;
}
//递归
static int binarySearch(int[] arr,int res,int low,int high){
if(res < arr[low] || res > arr[high] || low > high){
return -1;
}
int middle = (low+high)/2;
if(res < arr[middle]){
return binarySearch(arr, res, low, middle-1);
}else if(res > arr[middle]){
return binarySearch(arr, res, middle+1, high);
}else {
return middle;
}
}
}2.二叉查找树
一般情况下二分查找比顺序查找在时间上要快很多,但是在频繁修改的表中采用二分查找,其效率是非常低下的,因为顺序表的修改操作效率低下,而二分查找的高效就是利用顺序表的索引来取值进行比较的。为了支持频繁的修改,我们需要采用链表这种数据结构。然而,单链表的查找效率又非常低,为了解决这一问题,二叉查找树(BST)便诞生了。
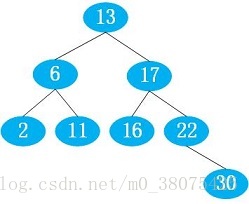
二叉查找树的特点是:任一结点的值都大于其左子树,小于其右子数,如下图所示:
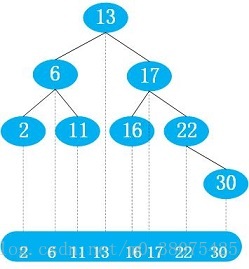
我们将二叉查找树投影到平面上,实际上就是有顺序的线性表,如下图所示:
二叉查找树既有快速查找的特点,又有快速插入的特点。其查找代码几乎和二分查找一样。
其时间复杂度最好情况为,最差情况为
。
最好情况为平衡二叉树(即每次查找会分成两半)时,如图:
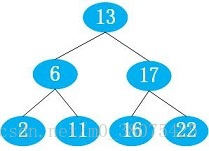
最差情况为所有数据全部在一端时(链表无索引,需要一个一个搜索),如图:
