机器学习cart算法的分类树
1、写在前面
决策树是通过一系列规则对数据进行分类的过程。它提供一种在什么条件下会得到什么值的类似规则的方法。决策树分为分类树和回归树两种,分类树对离散变量做决策树,回归树对连续变量做决策树,分类树是从ID3算法开始,改进成C4.5,随后又出现了cart算法,cart算法可以生成分类树,也可以生成回归树,每个决策树之所以不同主要是因为在最优标准属性的选择规则的不同,ID3的最优标准采取的是信息熵,改进成C4.5采取的是信息熵增益,而cart算法在构建分类树采取的标准是基尼指数,在构建回归时采取的标准为最小节点方差,因为ID3、C4.5在其他博客也已经详细介绍了,也通过python算法编程实现,这里就不再叙述,而对于cart算法,本人查阅很多资料以及博客,对其分类树的构建各有不同,而cart算法相对于前两个算法的优势是可以处理大批量的数据,故本人实例编程实现cart算法的分类树,回归树、模型树,以及将回归树与模型树进行了比较。
2、cart算法的分类树:
(2)、对生成树的后剪枝,应该利用测试集对其进行剪枝,利用测试集计算每一节点的表面误差率增益值α。
(3)、增加了一些函数,主要目的是利用测试集来计算表面误差率增益值α以及计算每个节点分类的正确率。
以下是本人改进后的分类树代码,在本人觉得不太容易理解的地方本人给出了注释,在此本人也给训练集与测试集链接训练集与测试集 密码 zf0q:
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
using namespace std;
//置信水平取0.95时的卡方表
const double CHI[18] = { 0.004,0.103,0.352,0.711,1.145,1.635,2.167,2.733,3.325,3.94,4.575,5.226,5.892,6.571,7.261,7.962 };
/*根据多维数组计算卡方值*/
template
double cal_chi(Comparable **arr, int row, int col) {
vector rowsum(row);
vector colsum(col);
Comparable totalsum = static_cast(0);//强制将0转换为Comparable型
//cout<<"observation"<right.first;
}
};
/* 下面这三个数据结构是来存在在哪种属性下的某一类的个数*/
typedef map MAP_REST_COUNT;
typedef map MAP_ATTR_REST;
typedef vector VEC_STATI;
const int ATTR_NUM = 6; //自变量的维度
vector X(ATTR_NUM);
int rest_number; //因变量的种类数,即类别数
vector > classes; //把类别、对应的记录数存放在一个数组中
int total_record_number; //总的记录数
vector > inputData; //原始输入数据
vector > testinputData; //测试输入数据
class node {
public:
node* parent; //父节点
node* leftchild; //左孩子节点
node* rightchild; //右孩子节点
string cond; //分枝条件
string decision; //在该节点上作出的类别判定
double precision; //判定的正确率
int record_number; //该节点上涵盖的记录个数
int size; //子树包含的叶子节点的数目
int index; //层次遍历树,给节点标上序号
double alpha; //表面误差率的增加量
node() {
parent = NULL;
leftchild = NULL;
rightchild = NULL;
precision = 0.0;
record_number = 0;
size = 1;
index = 0;
alpha = 1.0;
}
node(node* p) {
parent = p;
leftchild = NULL;
rightchild = NULL;
precision = 0.0;
record_number = 0;
size = 1;
index = 0;
alpha = 1.0;
}
node(node* p, string c, string d) :cond(c), decision(d) {
parent = p;
leftchild = NULL;
rightchild = NULL;
precision = 0.0;
record_number = 0;
size = 1;
index = 0;
alpha = 1.0;
}
void printInfo() {
cout << "index:" << index << "\tdecisoin:" << decision << "\tprecision:" << precision << "\tcondition:" << cond << "\tsize:" << size;
if (parent != NULL)
cout << "\tparent index:" << parent->index;
if (leftchild != NULL)
cout << "\tleftchild:" << leftchild->index << "\trightchild:" << rightchild->index;
cout << endl;
}
void printTree() {
printInfo();
if (leftchild != NULL)
leftchild->printTree();
if (rightchild != NULL)
rightchild->printTree();
}
};
/* 读取测试文件数据,采取的是c++字符串流的读取方式
得到结果:testinputData 数据源
*/
int readtestInput(string filename) {
ifstream ifs(filename.c_str());
if (!ifs) {
cerr << "open inputfile failed!" << endl;
return -1;
}
map catg;
string line;
getline(ifs, line);
string item;
istringstream strstm(line);
strstm >> item;
for (int i = 0; i> item;
X[i] = item;
}
while (getline(ifs, line)) {
vector conts(ATTR_NUM + 2);
istringstream strstm(line);
//strstm.str(line);
for (int i = 0; i> item;
conts[i] = item;
if (i == conts.size() - 1)
catg[item]++;
}
testinputData.push_back(conts);
}
total_record_number = testinputData.size();
ifs.close();
return 0;
}
/* 读取文件数据,采取的是c++字符串流的读取方式
得到结果:inputData 数据源
classes 分类标签以及个数(first:哺乳类,second:6)
rest_number 分类的种类数
*/
int readInput(string filename) {
ifstream ifs(filename.c_str());
if (!ifs) {
cerr << "open inputfile failed!" << endl;
return -1;
}
map catg;
string line;
getline(ifs, line);
string item;
istringstream strstm(line);
strstm >> item;
for (int i = 0; i> item;
X[i] = item;
}
while (getline(ifs, line)) {
vector conts(ATTR_NUM + 2);
istringstream strstm(line);
//strstm.str(line);
for (int i = 0; i> item;
conts[i] = item;
if (i == conts.size() - 1)
catg[item]++;
}
inputData.push_back(conts);
}
total_record_number = inputData.size();
ifs.close();
map::const_iterator itr = catg.begin();//将catg归类结果放入classes中
while (itr != catg.end()) {
classes.push_back(make_pair(itr->first, itr->second));
itr++;
}
rest_number = classes.size();//标签分为几类
return 0;
}
/*根据inputData作出一个统计stati,统计的是在哪种属性下的某类的个数。*/
void statistic(vector > &inputData, VEC_STATI &stati) {
for (int i = 1; isecond).find(rest);
if (iter == (itr->second).end()) {
(itr->second).insert(make_pair(rest, 1));
}
else {
iter->second += 1;
}
}
}
stati.push_back(attr_rest);
}
}
/*依据某条件作出分枝时,inputData被分成两部分*/
void splitInput(vector > &inputData, int fitIndex, string cond, vector > &LinputData, vector > &RinputData) {
for (int i = 0; i > &inputData) {
for (int i = 0; i < ATTR_NUM + 2; ++i) {
for (int j = 0; j < inputData.size(); ++j) {
cout << inputData[j][i] << "\t";
}
}cout << endl;
}
void printStati(VEC_STATI &stati) {
for (int i = 0; ifirst;
MAP_REST_COUNT::const_iterator iter = (itr->second).begin();
while (iter != (itr->second).end()) {
cout << "\t" << iter->first << "\t" << iter->second;
iter++;
}
itr++;
cout << endl;
}
cout << endl;
}
}
void split(node *root, vector > &inputData, vector > classes) {
//root->printInfo();
root->record_number = inputData.size();
VEC_STATI stati;
statistic(inputData, stati);
//printStati(stati);
//for(int i=0;i > fitleftclasses;//左树的分类标签以及个数
vector > fitrightclasses;//右树的分类标签以及个数
int fitleftnumber;//左树记录数
int fitrightnumber;
for (int i = 0; ifirst; //判定的条件,即到达左孩子的条件,属性
//cout<<"cond 为"< > leftclasses(classes); //左孩子节点上类别、及对应的数目
vector > rightclasses(classes); //右孩子节点上类别、及对应的数目
int leftnumber = 0; //左孩子节点上包含的类别数目
int rightnumber = 0; //右孩子节点上包含的类别数目
for (int j = 0; jsecond).find(rest);//
if (iter2 == (itr->second).end()) { //没找到,则对应类别以及类别树就全部在右树
leftclasses[j].second = 0;
rightnumber += rightclasses[j].second;
}
else { //找到,则右边树对应的种类以及个数就是总体的减去左边的种类数
leftclasses[j].second = iter2->second;
leftnumber += leftclasses[j].second;
rightclasses[j].second -= (iter2->second);
rightnumber += rightclasses[j].second;
}
}
/**if(leftnumber==0 || rightnumber==0){
cout<<"左右有一边为空"<cond<size)++;
travel = travel->parent;
}
node *LChild = new node(root); //创建左右孩子
node *RChild = new node(root);
root->leftchild = LChild;
root->rightchild = RChild;
int maxLcount = 0;
int maxRcount = 0;
string Ldicision, Rdicision;
for (int i = 0; imaxLcount) {
maxLcount = fitleftclasses[i].second;
Ldicision = fitleftclasses[i].first;
}
if (fitrightclasses[i].second>maxRcount) {
maxRcount = fitrightclasses[i].second;
Rdicision = fitrightclasses[i].first;
}
}
LChild->decision = Ldicision;
RChild->decision = Rdicision;
//LChild->precision = 1.0*maxLcount / fitleftnumber;
//RChild->precision = 1.0*maxRcount / fitrightnumber;
/*递归对左右孩子进行分裂*/
vector > LinputData, RinputData;
splitInput(inputData, fitIndex, fitCond, LinputData, RinputData);
//cout<<"左边inputData行数:"< > &testinputData) {
int i=0;
int fitIndex;
total_record_number = testinputData.size();
node *LChild= new node(root);
node *RChild= new node(root);
vector > LinputData, RinputData;
LChild =root->leftchild;
RChild = root->rightchild;
if (root->leftchild == NULL)
return;
string cond = root->cond;//分支条件是字符串:属性=属性下的分类,一下是对字符串的操作
string::size_type pos = cond.find("=");
string pre = cond.substr(0, pos);//将字符串前0-pos的位置的子字符串赋予pre
string post = cond.substr(pos + 1);//在此节点上的分支
for(int index=0;indexrecord_number = LinputData.size();
RChild->record_number = RinputData.size();
//printinputData(LinputData);
//printinputData(RinputData);
/*计算正确率*/
for (int j = 0; j < LinputData.size(); ++j) {
string rest = LinputData[j][ATTR_NUM + 1];//左树这一行的标签
if (rest == LChild->decision)
i++;
}
if (LChild->record_number == 0)
LChild->precision = 0;
else
LChild->precision=1.0*i/LChild->record_number;
i = 0;
for (int j = 0; j < RinputData.size(); ++j) {
string rest = RinputData[j][ATTR_NUM + 1];//右树这一行的标签
if (rest == RChild->decision)
i++;
}
if (RChild->record_number == 0)
RChild->precision=0;
else
RChild->precision = 1.0*i/RChild->record_number;
if(LChild->leftchild!=NULL)
pruneprecision(LChild,LinputData);
if(RChild->leftchild!=NULL)
pruneprecision(RChild, RinputData);
}
/*计算子树的误差代价*/
double calR2(node *root) {
if (root->leftchild == NULL)//叶子结点是没有左右子树的
return (1 - root->precision)*root->record_number / total_record_number;
else
return calR2(root->leftchild) + calR2(root->rightchild);
}
/*层次遍历树,给节点标上序号*/
void index(node *root) {
int i = 1;
queue que;
que.push(root);
while (!que.empty()) {
node* n = que.front();
que.pop();
n->index = i++;
if (n->leftchild != NULL) {
que.push(n->leftchild);
que.push(n->rightchild);
}
}
}
/*层次遍历树,给节点标上序号。同时计算alpha*/
void calalpha(node *root, priority_queue, MyCompare> &pq) {
int i = 1;
queue que;
que.push(root);
while (!que.empty()) {
node* n = que.front();
que.pop();
n->index = i++;
if (n->leftchild != NULL) {
que.push(n->leftchild);
que.push(n->rightchild);
//计算表面误差率的增量
double r1 = (1 - n->precision)*n->record_number / total_record_number; //节点的误差代价
double r2 = calR2(n);
n->alpha = (r1 - r2) / (n->size - 1);
pq.push(MyTriple(n->alpha, n->size, n->index));
}
}
}
/*剪枝*/
void prune(node *root, priority_queue, MyCompare> &pq) {
MyTriple triple = pq.top();
int i = triple.third;
queue que;
que.push(root);
while (!que.empty()) {
node* n = que.front();
que.pop();
if (n->index == i) {
cout << "将要剪掉" << i << "的左右子树" << endl;
n->leftchild = NULL;
n->rightchild = NULL;
int s = n->size - 1;
node *trav = n;
while (trav != NULL) {
trav->size -= s;
trav = trav->parent;
}
break;
}
else if (n->leftchild != NULL) {
que.push(n->leftchild);
que.push(n->rightchild);
}
}
}
void test(string filename, node *root,int labels) {
ifstream ifs(filename.c_str());
if (!ifs) {
cerr << "open inputfile failed!" << endl;
return;
}
string line;
getline(ifs, line);
string item;
istringstream strstm(line); //跳过第一行
map independent; //自变量,即分类的依据
while (getline(ifs, line)) {
istringstream strstm(line);
//strstm.str(line);
strstm >> item;
cout << item << "\t";
for (int i = 0; i> item;
independent[X[i]] = item;
}
node *trav = root;
while (trav != NULL) {
if (trav->leftchild == NULL) {
if (labels >0) {
cout << (trav->decision) << "\t置信度:" << (trav->precision) << endl;
break;
}
else
cout << (trav->decision) << endl;
}
string cond = trav->cond;//分支条件是字符串:属性=属性下的分类,一下是对字符串的操作
string::size_type pos = cond.find("=");
string pre = cond.substr(0, pos);//将字符串前0-pos的位置的子字符串赋予pre
string post = cond.substr(pos + 1);
if (independent[pre] == post)
trav = trav->leftchild;
else
trav = trav->rightchild;
}
}
ifs.close();
}
int main() {
string inputFile = "watermelon.txt";
readInput(inputFile);
VEC_STATI stati,teststati; //最原始的统计
statistic(inputData, stati);
// for(int i=0;iprintTree();
cout << "剪枝前使用该决策树最多进行" << root->size - 1 << "次条件判断" << endl;
string testFile = "testwatermelon.txt";
readtestInput(testFile);
test(testFile, root,0);
/*进行剪枝*/
pruneprecision(root,testinputData);
//root->printTree();
priority_queue, MyCompare> pq;
calalpha(root,pq);
/*//检验一个是不是表面误差增量最小的被剪掉了
while(!pq.empty()){
MyTriple triple=pq.top();
pq.pop();
cout<size - 1 << "次条件判断" << endl;
test(testFile, root,1);
/*priority_queue pq;
calalpha(root, pq);
root->printTree();
prune(root, pq);
cout << "剪枝后使用该决策树最多进行" << root->size - 1 << "次条件判断" << endl;
test(testFile, root);*/
system("pause");
return 0;
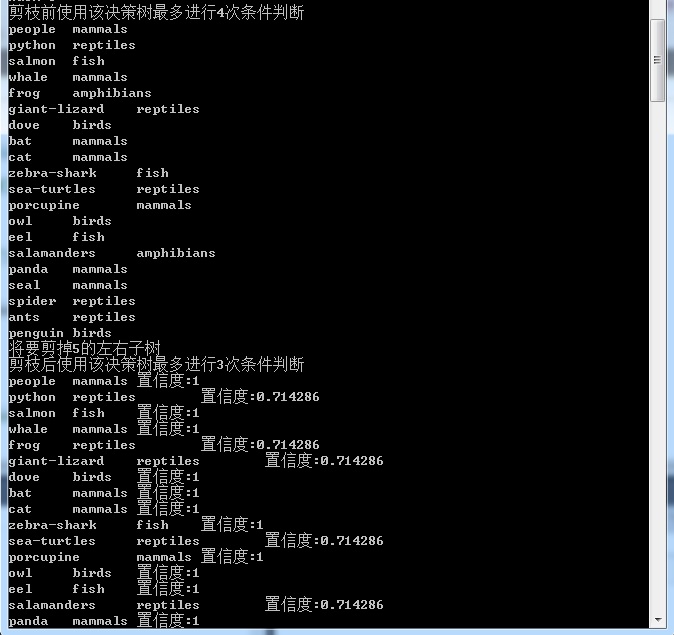
}最后贴一下代码运行结果图:(第一个是对watermelon数据源的分类树构建结果,以及利用测试集剪枝结果,足见在未剪枝时需进行4次条件判断,错误3个,而剪枝后分类判断
只进行1次,错误也为3个,若训练集数量大,测试集也多,既可以在降低条件判断步数,不降低分类的正确率)

以下是animal数据集的分类树构建与剪枝结果图(注意:要将代码中存放属性维数ATTR_NUM 改为8):