1 为什么要重点学习requests模块,而不是urllib
- requests的底层实现就是urllib
- requests在python2 和python3中通用,方法完全一样
- requests简单易用
- Requests能够自动帮助我们解压(gzip压缩的等)响应内容
2 requests的作用
作用:发送网络请求,返回响应数据
中文文档 : http://docs.python-requests.org/zh_CN/latest/index.html
通过观察文档来学习:如何使用requests来发送网络请求
3 requests模块发送简单的get请求、获取响应
需求:通过requests向百度首页发送请求,获取百度首页的数据
import requests
# 目标url
url = 'https://www.baidu.com'
# 向目标url发送get请求
response = requests.get(url)
# 打印响应内容
print(response.text)
response的常用属性:
response.text响应体 str类型respones.content响应体 bytes类型response.status_code响应状态码response.request.headers响应对应的请求头response.headers响应头response.request.cookies响应对应请求的cookieresponse.cookies响应的cookie(经过了set-cookie动作)
思考:text是response的属性还是方法呢?
- 一般来说名词,往往都是对象的属性,对应的动词是对象的方法
3.1 response.text 和response.content的区别
-
response.text- 类型:str
- 解码类型: requests模块自动根据HTTP 头部对响应的编码作出有根据的推测,推测的文本编码
- 如何修改编码方式:
response.encoding=”gbk”
-
response.content- 类型:bytes
- 解码类型: 没有指定
- 如何修改编码方式:
response.content.deocde(“utf8”)
获取网页源码的通用方式:
response.content.decode()response.content.decode("GBK")response.text
以上三种方法从前往后尝试,能够100%的解决所有网页解码的问题
所以:更推荐使用response.content.deocde()的方式获取响应的html页面
3.2 练习:把网络上的图片保存到本地
我们来把
www.baidu.com的图片保存到本地
思考:
- 以什么方式打开文件
- 保存什么格式的内容
分析:
- 图片的url: https://www.baidu.com/img/bd_logo1.png
- 利用requests模块发送请求获取响应
- 以2进制写入的方式打开文件,并将response响应的二进制内容写入
import requests
# 图片的url
url = 'https://www.baidu.com/img/bd_logo1.png'
# 响应本身就是一个图片,并且是二进制类型
response = requests.get(url)
# print(response.content)
# 以二进制+写入的方式打开文件
with open('baidu.png', 'wb') as f:
# 写入response.content bytes二进制类型
f.write(response.content)
4 发送带header的请求
我们先写一个获取百度首页的代码
import requests
url = 'https://www.baidu.com'
response = requests.get(url)
print(response.content)
# 打印响应对应请求的请求头信息
print(response.request.headers)
4.1 思考
对比浏览器上百度首页的网页源码和代码中的百度首页的源码,有什么不同?
代码中的百度首页的源码非常少,为什么?
4.2 为什么请求需要带上header?
模拟浏览器,欺骗服务器,获取和浏览器一致的内容
4.3 header的形式:字典
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"}
4.4 用法
requests.get(url, headers=headers)
4.5 完整的代码
import requests
url = 'https://www.baidu.com'
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"}
# 在请求头中带上User-Agent,模拟浏览器发送请求
response = requests.get(url, headers=headers)
# print(response.content)
# 打印请求头信息
print(response.request.headers)
5 发送带参数的请求
我们在使用百度搜索的时候经常发现url地址中会有一个
?,那么该问号后边的就是请求参数,又叫做查询字符串
5.1 什么叫做请求参数:
例1: http://www.webkaka.com/tutorial/server/2015/021013/
例2:https://www.baidu.com/s?wd=python&a=c
例1中没有请求参数!例2中?后边的就是请求参数
5.2 请求参数的形式:字典
kw = {'wd':'长城'}
5.3 请求参数的用法
requests.get(url,params=kw)
5.4 关于参数的注意点
在url地址中, 很多参数是没有用的,比如百度搜索的url地址,其中参数只有一个字段有用,其他的都可以删除 如何确定那些请求参数有用或者没用:挨个尝试! 对应的,在后续的爬虫中,越到很多参数的url地址,都可以尝试删除参数
5.5 两种方式:发送带参数的请求
- 对
https://www.baidu.com/s?wd=python发起请求可以使用requests.get(url, params=kw)的方式
# 方式一:利用params参数发送带参数的请求
import requests
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"}
# 这是目标url
# url = 'https://www.baidu.com/s?wd=python'
# 最后有没有问号结果都一样
url = 'https://www.baidu.com/s?'
# 请求参数是一个字典 即wd=python
kw = {'wd': 'python'}
# 带上请求参数发起请求,获取响应
response = requests.get(url, headers=headers, params=kw)
# 当有多个请求参数时,requests接收的params参数为多个键值对的字典,比如 '?wd=python&a=c'-->{'wd': 'python', 'a': 'c'}
print(response.content)
- 也可以直接对
https://www.baidu.com/s?wd=python完整的url直接发送请求,不使用params参数
# 方式二:直接发送带参数的url的请求
import requests
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"}
url = 'https://www.baidu.com/s?wd=python'
# kw = {'wd': 'python'}
# url中包含了请求参数,所以此时无需params
response = requests.get(url, headers=headers)
6 作业
1.获取新浪首页,查看response.text 和response.content.decode()的区别
2.实现任意贴吧的爬虫,保存网页到本地
小结
- requests模块的介绍:能够帮助我们发起请求获取响应
- requests的基本使用:
requests.get(url) - 以及response常见的属性:
response.text响应体 str类型respones.content响应体 bytes类型response.status_code响应状态码response.request.headers响应对应的请求头response.headers响应头response.request._cookies响应对应请求的cookieresponse.cookies响应的cookie(经过了set-cookie动作)
- 掌握 requests.text和content的区别:text返回str类型,content返回bytes类型
- 掌握 解决网页的解码问题:
response.content.decode()response.content.decode("GBK")response.text
- 掌握 requests模块发送带headers的请求:
requests.get(url, headers={}) - 掌握 requests模块发送带参数的get请求:
requests.get(url, params={})
requests模块的深入使用
学习目标:
- 能够应用requests发送post请求的方法
- 能够应用requests模块使用代理的方法
- 了解代理ip的分类
1 使用requests发送POST请求
思考:哪些地方我们会用到POST请求?
- 登录注册( POST 比 GET 更安全)
- 需要传输大文本内容的时候( POST 请求对数据长度没有要求)
所以同样的,我们的爬虫也需要在这两个地方回去模拟浏览器发送post请求
1.1 requests发送post请求语法:
-
用法:
response = requests.post("http://www.baidu.com/", \ data = data,headers=headers) -
data 的形式:字典
1.2 POST请求练习
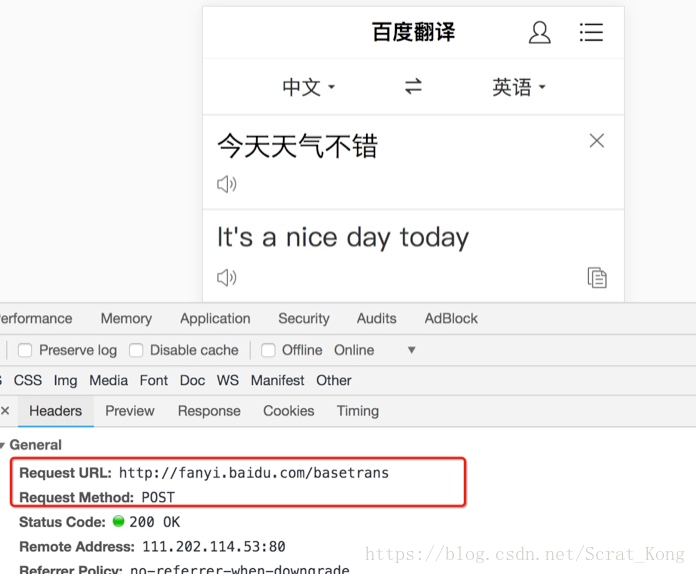
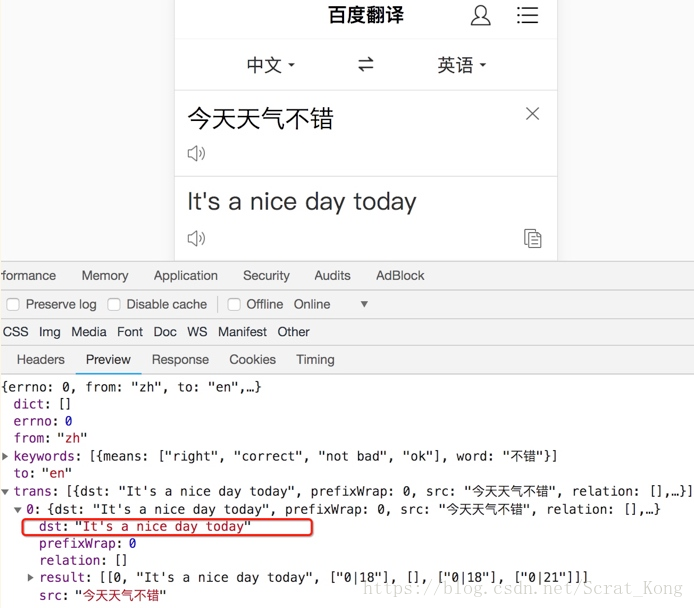
下面面我们通过手机版百度翻译的例子看看post请求如何使用:
思路分析
-
抓包确定请求的url地址
-
确定请求的参数
-
确定返回数据的位置
-
模拟浏览器获取数据

{kind=link}
1.3 小结
在模拟登陆等场景,经常需要发送post请求,直接使用requests.post(url,data)即可