一、find
因为Linux下面一切皆文件,经常需要搜索某些文件来编写,所以对于linux来说find是一条很重要的命令。linux下面的find指令用于在目录结构中搜索文件,并执行指定的操作。它提供了相当多的查找条件,功能很强大。在不指定查找目录的情况下,find会在对整个系统进行遍历。即使系统中含有网络文件系统,find命令在该文件系统中同样有效。 在运行一个非常消耗资源的find命令时,很多人都倾向于把它放在后台执行,因为遍历一个大的文件系统可能会花费很长的时间。
#!/bin/bash
find . -name '*tr'
find . -type '*.txt'
find ./temp -mmin -5000
find . -ctime +2
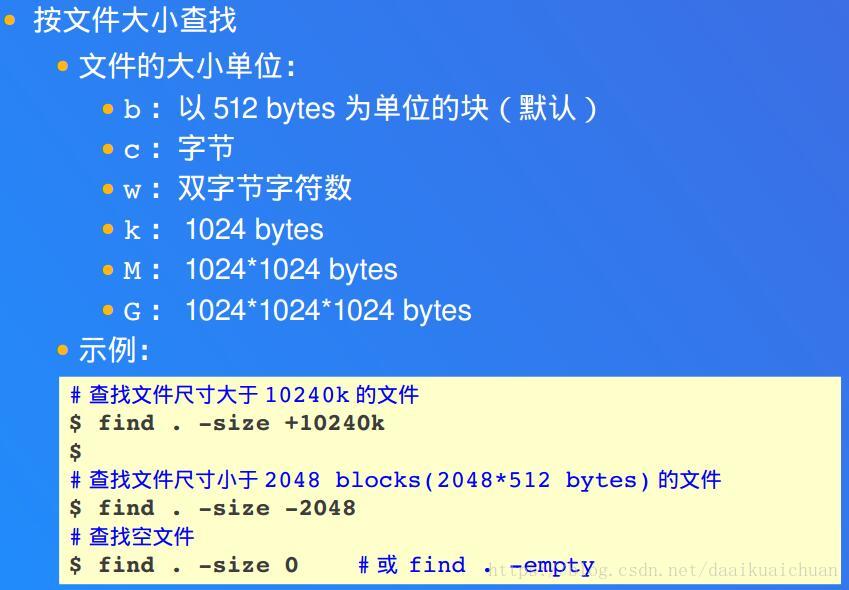
find . -size +1k
find . -perm -220
find ./temp -user lx
find . -name '*.txt' -exec cat {} \;
find . -name '*.txt' | xargs tar -cvf findtar.tar.gz






二、grep
Linux系统中grep命令是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹配的行打印出来。grep全称是Global Regular Expression Print,表示全局正则表达式版本,它的使用权限是所有用户。
ls -l | grep \'^a\'
#通过管道过滤ls -l输出的内容,只显示以a开头的行。
grep \'test\' d*
#显示所有以d开头的文件中包含test的行。
grep \'test\' aa bb cc
#显示在aa,bb,cc文件中匹配test的行。
grep \'[a-z]{5}\' aa
#显示所有包含每个字符串至少有5个连续小写字符的字符串的行。
grep \'w(es)t.*1\' aa
#如果west被匹配,则es就被存储到内存中,并标记为1,然后搜索任意个字符(.*),这些字符后面紧跟着另外一个es(1),找到就显示该行。如果用egrep或grep -E,就不用""号进行转义,直接写成\'w(es)t.*1\'就可以了。
三、sed
strem editor 流编辑器 ,sed编辑器是一行一行的处理文件内容的。正在处理的内容存放在模式空间(缓冲区)内,处理完成后按照选项的规定进行输出或文件的修改。 sed 是一种在线编辑器,它一次处理一行内容。处理时,把当前处理的行存储在临时缓冲区中,称为“模式空间”(pattern space),接着用sed命令处理缓冲区中的内容,处理完成后,把缓冲区的内容送往屏幕。接着处理下一行,这样不断重复,直到文件末尾。文件内容并没有改变,除非你使用重定向存储输出。sed是一个很好的文件处理工具,本身是一个管道命令,主要是以行为单位进行处理,可以将数据行进行替换、删除、新增、选取等特定工作,下面先了解一下sed的用法
#!/bin/bash
echo "tiger's home is home01"
echo "tiger's home is home01" | sed 's/home/Home/' # 单次替换
echo "tiger's home is home01" | sed 's/home/Home/g' # 一行全局替换
echo "tiger's home is home01" | sed 's/home/Home/ ; s/tiger/Tiger/' #改变多个
sed '/two/ s/1/2/g' sedd.txt # 指定某一行,开始替换
sed -n '/three/,5 s/1/3/gp' sedd.txt # 指定范围,参数-n表示禁止显示,参数p表示仅显示匹配到的数据
sed -n '2a temp text' sedd.txt # 在第二行后追加字符串



四、awk
awk是一种样式扫描和文本处理语言。awk语言的最基本功能是在文件或者字符串中基于指定规则浏览和抽取信息。相对于sed常常用于一整行处理, awk则比较倾向于一行当中分成数个”字段“(区域)来处理, 默认的分隔符是空格键或tab键。awk还支持C语法,可以有分支条件判断、循环语句等,相当于一个小型编程语言。
#!/bin/bash
awk '{print $2}' awktest.txt # 打印第二列
awk '/zhangsan/ {print $2}' awktest.txt # 指定字段后打印第二列
awk '{FS=":"} {print $1,$2}' awktest.txt # 使用FS指定字段分隔符
awk '{print $2 | "sort"}' awktest.txt # 命令必须用双引号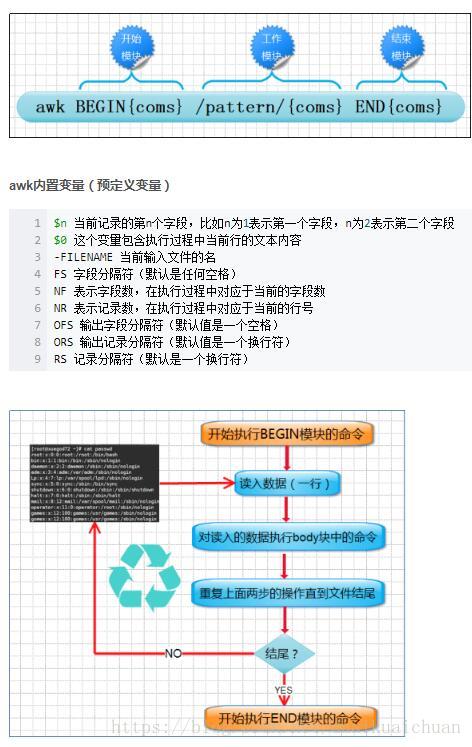
一个简单的demo
姓名 成绩
zhangsan 80
lisi 81.5
wangwu 93
zhangsan 85
lisi 88
wangwu 97
zhangsan 90
lisi 92
wangwu 88需求:求出每名学生的平均成绩,以及所有学生中成绩的最高者和最高值:
# begin表示在做后续所有动作之前先执行begin后面的语句,end则表示前面的语句都执行完了再执行end后面的语句。
# a[$1]+=$2表示关联数组,数组下标可以是数字也可以是字母,for循环和if判断和C语言里面的用法类似,NR表示文件总行数。
awk 'BEGIN {print "Name Average Total"} {a[$1]+=$2;b[$1]++} END {for(i in a) print i,a[i]/b[i],a[i]}' awktest.txt
awk 'BEGIN {print "max score:";max_i=0} {for(i=1;i<=NR;++i) if($2>max_i){max_i=$2}} END {print max_i}' awktest.txt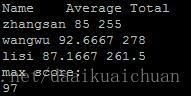
参考:https://blog.csdn.net/qq_25663723/article/details/53161646