一、count():返回、计算结果集的行数;
1、count()和sum()函数的区别:
一个(count)是统计结果集的总行数; 一个(sum)是计算所有(符合条件)数值的总和;
mysql> select * from chengji;
+------+---------+-------+
| name | subject | score |
+------+---------+-------+
| 张三 | 数学 | 90 |
| 张三 | 语文 | 50 |
| 张三 | 地理 | 40 |
| 李四 | 语文 | 55 |
| 李四 | 政治 | 45 |
| 王五 | 政治 | 30 |
+------+---------+-------+
6 rows in set (0.00 sec)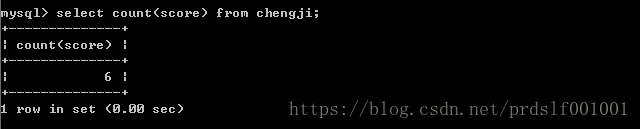
用count(列)的时候,即:select count(score)from chengji; 这句查询的意思是:先做 select score from chengji; 的查询,然后统计出返回的结果集的总行数;

sum(列)的时候,计算的是 符合条例 数值的总和;
2、count(*)和count(1)、count(columnName)的区别:
(1)从统计的结果上:
count(*)和count(1)会统计出结果集表中所有的记录数, 包含字段为NULL的记录;
count(columnName):在统计的时候,如果字段值为NULL,则不会计入总数(不统计字段为NULL的记录);
(1)从统计的效率上:
如果只有一个字段,则count(*)的效率是最优的;
如果有主键,则count(主键)的效率是最优的;
其他情况下,一般count(1)的效率是最优的;
二、groud by、having的总和应用;
1、根据下表。查询出2门及2门以上不及格者的平均成绩;mysql> select * from chengji;
+------+---------+-------+
| name | subject | score |
+------+---------+-------+
| 张三 | 数学 | 90 |
| 张三 | 语文 | 50 |
| 张三 | 地理 | 40 |
| 李四 | 语文 | 55 |
| 李四 | 政治 | 45 |
| 王五 | 政治 | 30 |
+------+---------+-------+
6 rows in set (0.00 sec)## 一种错误做法
mysql> select name,count(score < 60) as k,avg(score) from chengji group by name having k>=2;
错误分析:首先,此语句先执行:select name from chengji (where 1) : 得出:查询出所有人的名字;
mysql> select name from chengji;
+------+
| name |
+------+
| 张三 |
| 张三 |
| 张三 |
| 李四 |
| 李四 |
| 王五 |
+------+
6 rows in set (0.00 sec)
mysql>然后:再次执行:select count(score<60) as k,avg(score) from chengji group by name; 按照姓名,进行分组,统计出每组的行数(即每个人的科目数),计算出每个组的平级分数;得出:

此时的K是,按照分组,统计出的每个人的科目数,而不是挂科数:故:最后在用having>2筛选,显然错误;
## 另一种错误做法:
mysql> select name,avg(score) from chengji where score<60 group by name having count(*)>=2;
错误分析:首先,此语句先执行:select name from chengji where score <60; 先把score <60 的人给查询出来;得出:

然后,再执行:select name,avg(score) from chengji where score<60 group by name;按照名字进行分组,求出每组人的平级分,此时,显然错误,第一次score<60只查询出的是挂科的人以及对应的分数,而再次分组求平均分,则只求的是 每个人 挂科的平均分 而不是 整体的 平级分;
## 正确方法1:
先求出每个人的平级分,然后再筛选出挂科数>=2的;
每个人平级分:

每个人的挂科数:
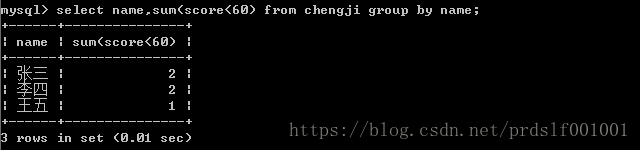
注意:此时用的是sum()求和函数,比较运算符 返回的数值为0或者1(假或者真); 不是用count,count则返回的是按照分组每个人分数的总行数,每个人下的分数都统计,包含挂科以及不挂科的:
最终得出:

## 正确方法2:
先查询出2门以及两门以上不及格者:

即;为张三、李四,需要在筛选出来;
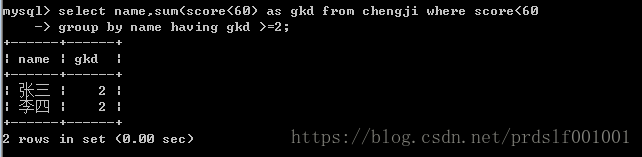
然后,算出,这个表中name人物的平均分;

或者直接简写一个表的查询,直接得出name张三、李四的值;

综上:从where到group by、再到having的流程为:先查询,在分组(计算),最后筛选;
三、order by 应用;
order by 字段名 asc(升序), order by 字段名 desc(降序);默认是asc。在不写的情况下;
多条件综合排序的时候,用 , (逗号) 进行分割;

四、limit 应用;
limit [offset=0] N; 其中offset表示的偏移量,跳过几个(行),N表示取出的数量,行数;

前三名到前五名,即:跳过了(偏移了)2个,所以offset = 2,一共需要取出3个,即: limit 2,3;
五、练习应用以及聚合函数注意点;

上述的查询语句,是取出的最大商品价格以及其对于的商品名称;
如果用max(shop_price)聚合函数来只能取出最大商品价格,不能与最大商品价格的名字相互匹配;
因为,max(shop_price)相当于一个一个新的字段列,一个原表格的投影,是最大的商品单独一个字段一行,
但是如果select后面加个goods_name字段,则会一下取出所有的商品名字(goods_name),那么多goods_name商品名称,哪一个与之相匹配呢?
