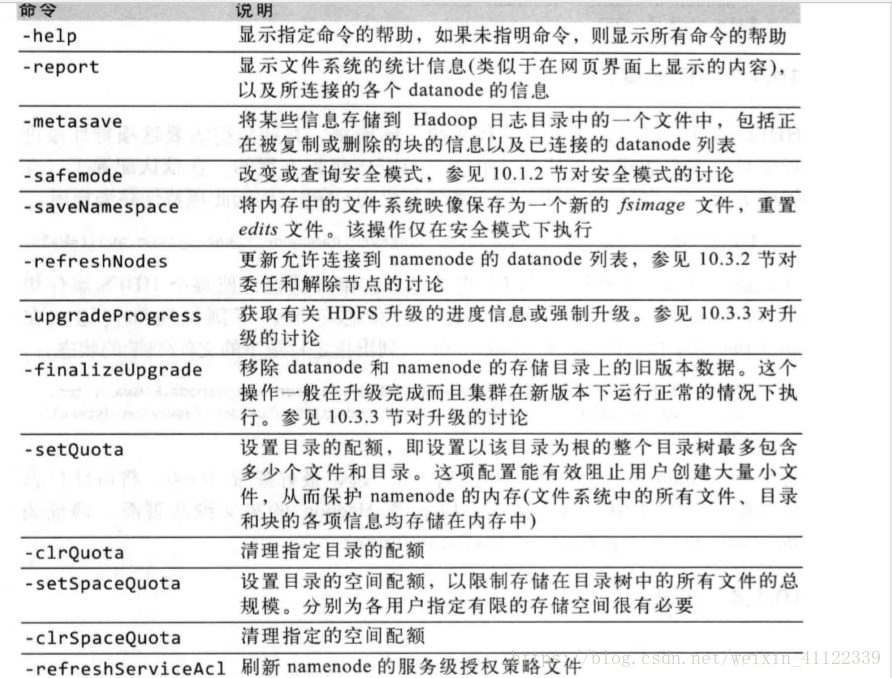
hdfs dfsadmin管理命令图
1,namenode的本地目录结构
edit //编辑日志
fsimage //镜像文件
version //版本信息
1,文件系统客户端执行写操作时(例如创建或者上传等一系列操作),首先会被记录到编辑日志中,namenode在内存维护文件系统的元数据,当编辑日志被修改时,相关的数据信息也同步更新。内存中的元数据可以支持客户端的读请求。 2,在每次只需写操作之后,编辑日志都会更新同步。当namenode想多个目录下数据时,只有字所有写操作均执行完毕之后方可返回成功代码,以确保任何操作不会因为机器故障而丢失。 3,fsimage 文件是文件系统元数据的一个永久性检查点。并非每一个写操作都会更新该文件,因为fsimage是一个大型文件(甚至高达几个G),如果频繁的执行写操作,会是系统运行极为缓慢,但这个特性根本不会降低系统的恢复能力,因为如果namenode发生故障,可以把fsimage文件载入到内存重构新的元数据,在执行编辑日志中记录的各项操作,事实上,namenode在启动阶段正是怎样做的2,查看编辑/镜像文件
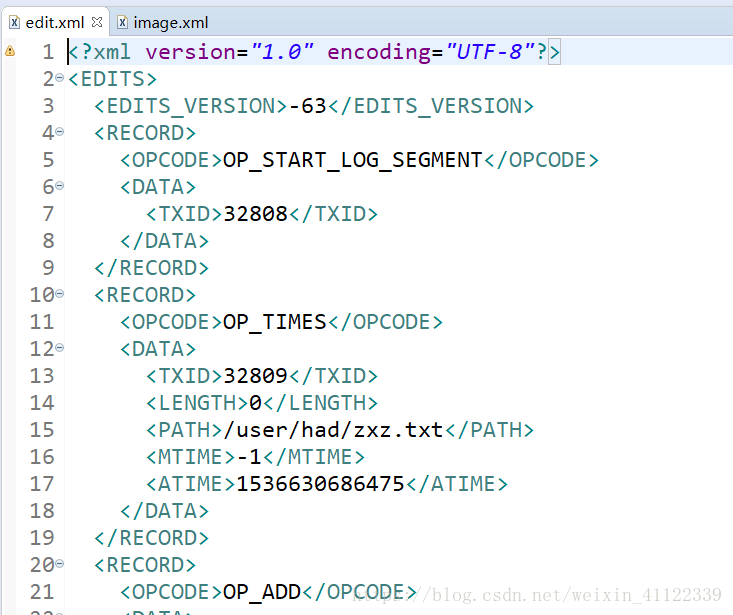
hdfs oiv (镜像日志) 例如: hdfs oiv -i imageFile -p XML -o image.xml
hdfs oev (编辑日志)例如: hdfs oev -i editFile -p XML -o edit.xml
hdfs dfsadmin -rollEdits //滚动日志(即立刻保存当前日志状态)
注意(编辑日志里面存放着是你每次操作的信息,镜像日志里存放的是记录每个文件和文件夹的信息,所以每次启动hadoop集群他都会加载这个镜像文件,和更新日志文件不过这些都必须在安全模式下进行,后面会介绍安全模式)
3,辅助namenode解决namenode中的编辑日志过大的解决方法和执行流程
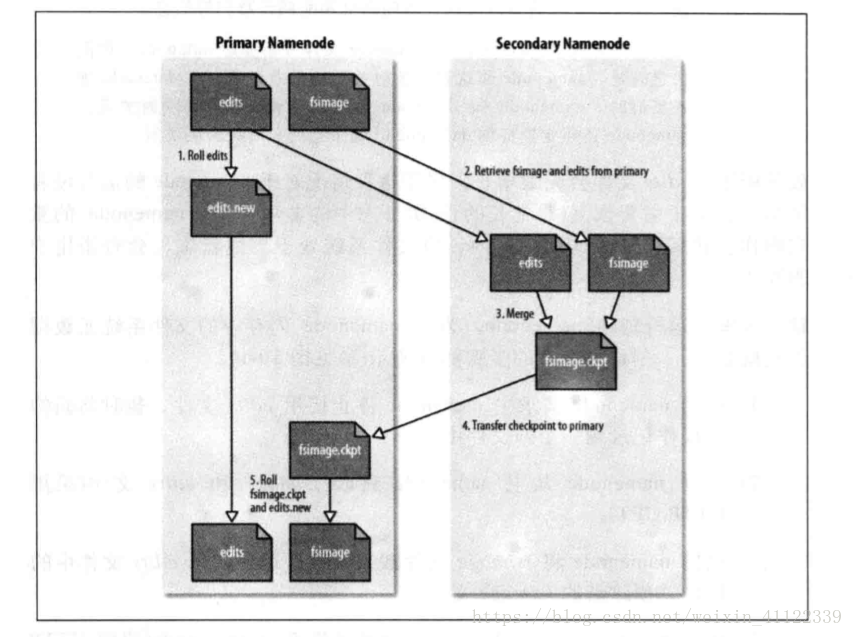
我们都知道辅助namenode节点就是为了协助namenode的,具体他干了些什么事我们看图进行分析;
执行流程
(1)辅助namenode请求namenode停止使用edits文件,暂时将新的写操作记录到一个新文件中 (2)辅助namenode从namnode获取fsimgae和edits文件(采用HTTP GET) (3)辅助namenode将fsimage文件载入内存,逐一执行edits文件中的操作,创建新的fsimage文件(也就是把edits文件和fsimage文件和成一个image文件) (4)辅助namenode将新的fsimage文件发送回namenode(使用HTTP POST) (5)namenode用从辅助namenode接收的fsimage文件替换旧的fsimage文件,用步骤1所产生的edits文件替换旧的edits文件,同时,还更新fstime文件来记录检查点执行的时间4,辅助namenode的本地目录结构(恢复nodename的两种方式)
他其实和namenode的结构是相同的,这样设计的好处就在于,如果namenode发生故障,并且没有及时备份的情况下, 可以从辅助namenode上恢复数据,并且有两种方式:
1,复制辅助namenode的数据到新的namenode上
2,启动nn时,使用-importCheckpoint选项进行检查点导入
start-dfs.sh -importCheckpoint
5,datanode的本地目录结构
datanode和namenode不同的是,datanode的存储是初始阶段自动创建爱你的,不需要额外的格式化,,他的目录结构如下:
${dfs.data.dir}/
└── current/
├── VERSION
├── blk_<id_1>
├── blk_<id_1>.meta
├── blk_<id_2>
├── blk_<id_2>.meta
├── ...
├── blk_<id_64>
├── blk_<id_64>.meta
├── subdir0/
├── subdir1/
├── ...
└── subdir63/其中: Version都是差不多的只不过一个记录的是namnode一个是datanode
还有就是极为重要得以blk_为前缀的文件分为两种:
1,HDFS块文件(仅包含原始数据)
2,块的元数据文件(含.meta后缀)
块文件包含所有存储文件中的一部分的原始数据(如果所在文件不足128m,就只有一块原始数据)
元信息文件包括头部(含版本和类型信息)和该块各区段的一系列校验和
6,安全模式
1,namenode启动时,首先将镜像文件(fsimage)载入内存,并执行编辑日志(edits)中的各项操作。一旦在内存中成功建立文件系统元数据的镜像,则创建一个新的fsimage文件(该操作不需要借助辅助namenode)和一个空的编辑日志,此时,namenode开始监听RPC和HTTP请求,但是此刻,namenode运行在安全模式,集namenode的文件系统对客户端来说是只读的像那些上传,下载,删除,在安全模式下是不支持的
2,系统中数据块的位置并不是namenode维护的,而是以块列表的形式存储在datanode中,在系统的正常操作期间中namenode会在内存中保存所有块的位置的镜像信息,在安全模式下,各个datanode会向namenode发送最新的块列表信息,namenode了解到足够多的块位置信息之后,即可高效运行文件系统,,如果namenode认为向其发送更新信息的datanode过少,则会启动块复制进程,以将数据块复制到新的datanode节点,实际上,在安全模式下namenode并不向datanode发送任何块复制和块删除的指令。如果满足百分之九九点九的块满足复本级别,才会自动打开安全模式。
3,安全模式命令操作
hdfs dfsadmin -safemode enter //进入安全模式
hdfs dfsadmin -safemode leave //离开安全模式
hdfs dfsadmin -safemode get //查询当前模式
hdfs dfsadmin -safemode wait //等待模式
7,检查点控制手段
1.配置2nn检查点周期,默认是一小时(秒数)
[hdfs-site.xml]
<property>
<name>dfs.namenode.checkpoint.period</name>
<value>3600</value>
<description>The number of seconds between two periodic checkpoints.
</description>
</property>
2.编辑日志超过64M,也会创建检查点。8,hadoop配额管理
1,配额类型
space quota //空间配额
dir quota //目录配额
2,设置目录配额
hdfs dfsadmin -setQuota 2 /user/had/hadpp[
3, 设置空间配额,至少3*128M
hdfs dfsadmin -setSoaceQuota 500M /user/had/hadoop
9,快照管理(快速备份)
hdfs dfsadmin -allowSnapshot dir_name //启用指定目录快照
hdfs dfsadmin -disallowSnapshot dir_name //禁用指定目录快照hdfs dfs [-createSnapshot <snapshotDir> [<snapshotName>]] //创建快照
hdfs dfs [-deleteSnapshot <snapshotDir> <snapshotName>] //删除快照
hdfs dfs -renameSnapshot hadoop sp_1 sp_2 //重命名快照hdfs lsSnapshottableDir //列出所有可以快照的目录
hdfs snapshotDiff hadoop sp_1 sp_2 //比较两个快照的不同10,块扫描器
数据节点每隔多少个小时扫描块数据,进行校验和计算
<property>
<name>dfs.datanode.scan.period.hours</name>
<!--小时数(3周)-->
<value>504</value>
<description>
0 //默认值==504
-1 //禁用
</description>
</property>webui:
http://datanode:50075/blockScannerReport?listblocks11.均衡器
随着时间推移,个个datanode上分布的数据块,会越来越不均衡会降低mareduce的本地性,导致部分datanode的相对更加繁忙,为了避免情况发生,我们可以执行均衡器进程命令来达到集群均衡
start-balancer.sh
12,回收站控制文件在trash中存活时间(分钟数)
客户端和服务器端均可以进行配置,优先级server >client
shell命令删除文件会进入到trash
编程删除的文件会直接删除
编程可以通过movetoTrash()进入会进入trash
从trash恢复文件只需要移除trash即可
[core-site.xml]
<!-- 驻留间隔(分钟数) -->
<property>
<name>fs.trash.interval</name>
<value>1</value>
</property><!-- 回收站检查间隔(分钟) <= fs.trash.interval -->
<property>
<name>fs.trash.checkpoint.interval</name>
<value>1</value>
</property>$>hadoop fs -expunge //清除超期的文件
Hadoop(HDFS)管理

猜你喜欢
转载自blog.csdn.net/weixin_41122339/article/details/82621727
今日推荐
周排行