从android HashMap的源码实现谈谈HashMap的性能问题
前言
实际开发中,HashMap可能是我们用的最多的数据结构了。基础稍微扎实一点的开发,问起HashMap的特性,都会说,HashMap是key可以为null的,无序的,非线程安全的。没错,这几点确实是HashMap的特性,但是HashMap究竟为什么是非线程安全的,多线程下会有什么问题,作为“有理想”的程序员,都不应该放过。
预备知识
HashMap,顾名思义,是使用Hash表实现的Map。和Hash表相关的几个概念有:
Hash(哈希)函数,Hash冲突。Hash函数的表达式:Addr = H(key),就是以key为输入,Addr为输出的函数,Addr就是key对应的在哈希表中的地址。当不同的key产生相同的Addr时,就会发生hash冲突。
android中HashMap的实现
android中hashMap的实现和jdk里的大致思路一样,以android的为例。
先看构造函数:
public HashMap() {
table = (HashMapEntry<K, V>[]) EMPTY_TABLE;
threshold = -1; // Forces first put invocation to replace EMPTY_TABLE
}
public HashMap(int capacity) {
if (capacity < 0) {
throw new IllegalArgumentException("Capacity: " + capacity);
}
if (capacity == 0) {
@SuppressWarnings("unchecked")
HashMapEntry<K, V>[] tab = (HashMapEntry<K, V>[]) EMPTY_TABLE;
table = tab;
threshold = -1; // Forces first put() to replace EMPTY_TABLE
return;
}
if (capacity < MINIMUM_CAPACITY) {
capacity = MINIMUM_CAPACITY;
} else if (capacity > MAXIMUM_CAPACITY) {
capacity = MAXIMUM_CAPACITY;
} else {
capacity = Collections.roundUpToPowerOfTwo(capacity);
}
makeTable(capacity);
}
public HashMap(int capacity, float loadFactor) {
this(capacity);
if (loadFactor <= 0 || Float.isNaN(loadFactor)) {
throw new IllegalArgumentException("Load factor: " + loadFactor);
}
/*
* Note that this implementation ignores loadFactor; it always uses
* a load factor of 3/4. This simplifies the code and generally
* improves performance.
*/
}
public HashMap(Map<? extends K, ? extends V> map) {
this(capacityForInitSize(map.size()));
constructorPutAll(map);
}HashMap提供了四个构造方法,按照上面的代码排列依次是:无参构造、初始容量构造、初始容量+装载因子构造、map构造。这几个构造方法涉及到了几个名词:
threshold : 阀值,容量为0时默认-1
capacity : 容量
loadFactor: 装载因子,默认0.75(3/4)
makeTable()的实现:
private HashMapEntry<K, V>[] makeTable(int newCapacity) {
@SuppressWarnings("unchecked") HashMapEntry<K, V>[] newTable
= (HashMapEntry<K, V>[]) new HashMapEntry[newCapacity];
table = newTable;
threshold = (newCapacity >> 1) + (newCapacity >> 2); // 3/4 capacity
return newTable;
}这段代码决定了,threshold阀值 = table大小的3/4(0.75)。
HashMap()构造函数中,出现了
table = (HashMapEntry<K, V>[]) EMPTY_TABLE
这样一行代码,看下table的申明:
transient HashMapEntry<K, V>[] table;
table是一个HashMapEntry的数组,而HashMapEntry的实现:
static class HashMapEntry<K, V> implements Entry<K, V> {
final K key;
V value;
final int hash;
HashMapEntry<K, V> next;
HashMapEntry(K key, V value, int hash, HashMapEntry<K, V> next) {
this.key = key;
this.value = value;
this.hash = hash;
this.next = next;
}
public final K getKey() {
return key;
}
public final V getValue() {
return value;
}
public final V setValue(V value) {
V oldValue = this.value;
this.value = value;
return oldValue;
}
@Override public final boolean equals(Object o) {
if (!(o instanceof Entry)) {
return false;
}
Entry<?, ?> e = (Entry<?, ?>) o;
return Objects.equal(e.getKey(), key)
&& Objects.equal(e.getValue(), value);
}
@Override public final int hashCode() {
return (key == null ? 0 : key.hashCode()) ^
(value == null ? 0 : value.hashCode());
}
@Override public final String toString() {
return key + "=" + value;
}
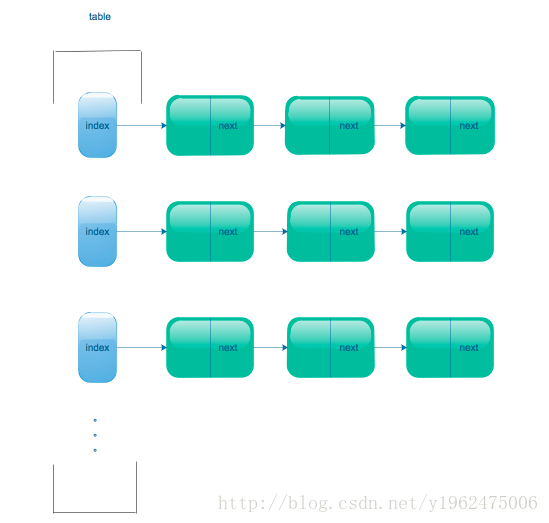
}可以看到,HashMapEntry是一个实现了Entry接口,并且封装了get、set相关方法的类,看到HashMapEntry next;这一行了么,这说明,每个HashMapEntry实体都是一个单链表。回过头来,table又是一个HashMapEntry的数组,这么一看,HashMap的数据结构就清晰了:table的每个位置都是一个HashMapEntry单链表。如示意图:
HashMap(int capacity)构造函数中,对capacity做了判断:capacity==0,用默认的空table,capacity
private static final int MINIMUM_CAPACITY = 4;MAXIMUM_CAPACITY的声明:
private static final int MAXIMUM_CAPACITY = 1 << 30;也就是说,table的容量应该是在4到1 << 30(1*2^30)之间,小于4按4算,大于1 << 30按1 << 30算。之间的数按照Collections.roundUpToPowerOfTwo(int i)方法的返回值算。从字面上看,这个函数是找出向上离i最近的2的指数幂。这么说可能还是有点晕乎,直接上一段代码测试下:
public void test(){
System.out.println(roundUpToPowerOfTwo(5));
}输出结果为8。对着这个例子解释就是,离5最近的2的指数幂有两个,就是2^3=8,2^2=4,但是向上(up)的含义就是,从大于i的方向取,也就是8。所以不论是4还是1 << 30还是中间,最后capacity都是2的指数幂。
put方法
@Override public V put(K key, V value) {
if (key == null) {
return putValueForNullKey(value);
}
int hash = Collections.secondaryHash(key);
HashMapEntry<K, V>[] tab = table;
int index = hash & (tab.length - 1);
for (HashMapEntry<K, V> e = tab[index]; e != null; e = e.next) {
if (e.hash == hash && key.equals(e.key)) {
preModify(e);
V oldValue = e.value;
e.value = value;
return oldValue;
}
}
// No entry for (non-null) key is present; create one
modCount++;
if (size++ > threshold) {
tab = doubleCapacity();
index = hash & (tab.length - 1);
}
addNewEntry(key, value, hash, index);
return null;
}这段代码,内容并不多,总体分为几个部分:
1、如果key是空,则添加以null为key的值;
2、如果key不空,key已经存在,更新value并且返回旧值;如果存在冲突(同一个index),遍历到这个index下面的单链表末尾。
3、如果大小达到阀值,把table扩容两倍
4、添加实体
第1部分,看下putValueForNullKey的实现:
private V putValueForNullKey(V value) {
HashMapEntry<K, V> entry = entryForNullKey;
if (entry == null) {
addNewEntryForNullKey(value);
size++;
modCount++;
return null;
} else {
preModify(entry);
V oldValue = entry.value;
entry.value = value;
return oldValue;
}
}如果之前没有以null为key的实体entryForNullKey,就添加;否则就修改,并返回旧的value。这个很好理解,以null为key的实体只能有一个。
第2部分,先是用转二进制散列值函数得到一个关于key的二进制的散列值:
public static int secondaryHash(Object key) {
return secondaryHash(key.hashCode());
}用key的hashCode去转成二进制的。然后用这个散列值和table长度-1做与运算,得到一个要填充的位置index,找到这个index的entry,然后以entry的hash值和key的quals结果判断是不是同一个entry。
第3部分,数组table的大小达到阀值,就去扩容:
private HashMapEntry<K, V>[] doubleCapacity() {
HashMapEntry<K, V>[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {
return oldTable;
}
int newCapacity = oldCapacity * 2;
HashMapEntry<K, V>[] newTable = makeTable(newCapacity);
if (size == 0) {
return newTable;
}
for (int j = 0; j < oldCapacity; j++) {
/*
* Rehash the bucket using the minimum number of field writes.
* This is the most subtle and delicate code in the class.
*/
HashMapEntry<K, V> e = oldTable[j];
if (e == null) {
continue;
}
int highBit = e.hash & oldCapacity;
HashMapEntry<K, V> broken = null;
newTable[j | highBit] = e;
for (HashMapEntry<K, V> n = e.next; n != null; e = n, n = n.next) {
int nextHighBit = n.hash & oldCapacity;
if (nextHighBit != highBit) {
if (broken == null)
newTable[j | nextHighBit] = n;
else
broken.next = n;
broken = e;
highBit = nextHighBit;
}
}
if (broken != null)
broken.next = null;
}
return newTable;
}总体来说,就是table容量扩大为两倍,然后重新计算每个entry的位置,并计算出新的实体应在的位置。这个过程很精巧,新表的位置是按照高位去计算新的位置的,把旧的冲突链上(此时整个冲突链已经在新的位置),高位不一样的放到新计算的位置,一样的保留。
第4步,按照之前计算的位置添加实体,但是此时index上可能会有存在的实体:
void addNewEntry(K key, V value, int hash, int index) {
table[index] = new HashMapEntry<K, V>(key, value, hash, table[index]);
}HashMapEntry这个构造,第四个参数是下一个实体(next),也就是当前实体table[index]是当前冲突链的链表头。上述的代码可以写成:Entry head = table[index];n.next = head;head = n;所以添加的位置,是冲突链表的头部。
get方法
public V get(Object key) {
if (key == null) {
HashMapEntry<K, V> e = entryForNullKey;
return e == null ? null : e.value;
}
int hash = Collections.secondaryHash(key);
HashMapEntry<K, V>[] tab = table;
for (HashMapEntry<K, V> e = tab[hash & (tab.length - 1)];
e != null; e = e.next) {
K eKey = e.key;
if (eKey == key || (e.hash == hash && key.equals(eKey))) {
return e.value;
}
}
return null;
}get方法逻辑也很简单,key为空就把之前放进来的对应实体返回,实体也为null就返回null。然后找到这个实体的位置,按照传参进来的key和实体的key指向同一个地址(eKey == key)或者实体的hash值和传参key的hash值相等(e.hash == hash)并且传参key和这个位置上的实体key的equals方法返回truekey.equals(eKey),这样的规则确定是否是同一个。
性能问题分析
分析完上面几个关键的方法,基本可以得出几个结论:
- HashMap是可以以null为key的(代码显而易见);
- HashMap是非线程安全的(也没看到用到sychronized、volatile和CAS);
- HashMap的实际大小总是2的指数幂;
- HashMap数组+单链表的数据结构,其实就是用直接链法处理hash冲突(相关概念可以自行百度);
- HashMap的大小不是一成不变的,而是在达到阀值(数组大小0.75倍),就开始扩容;
- 扩容后的大小是原来的两倍;
- put方法中,e.hash == hash && key.equals(e.key)是判定是否为同一个实体的条件;
- get方法中,eKey == key || (e.hash == hash && key.equals(eKey)是判定是否为同一个实体的条件。
性能问题一,HashMap的大小:
为什么说HashMap的实际大小总是2的指数幂?因为就算初始化的时候不是2的指数幂,roundUpToPowerOfTwo函数也会帮你转。为什么一定要是2的指数幂?这个是由于HashMap使用的散列算法,就是用key的hashCode转成对应的二进制,然后和HashMap的size-1座“&”操作。为什么这样做?举个例子,如果HashMap的设定大小为10,那么roundUpToPowerOfTwo转完大小是2^4 = 16,那么16-1=15,用二进制表示就是1111,此时如果一个实例的二进制哈希码为850873883(仅用来举例),二进制表示是110010101101110100111000011011,两者进行与运算,结果就是截取低四位1011,十进制就是11,也就是进来的key<->value的实体放在11这个位置上。试想如果HashMap的大小不是16而是10,10-1 = 9,二进制表示是1001,那么中间两个0的位置永远不会取到1,也就是2,3,4,6,5,7,这6个位置永远都都不会被算到实际填充的位置,空间利用率不足一半。这样的话就明白为什么用2的指数幂了:散列均匀。
那么问题来了,既然HashMap的实现已经帮我们做了这么多工作,我们是不是直接用就好了,不用管其他的了?明显不是。首先当HashMap的大小过小的时候,会增加Hash冲突的几率;另外如上面分析put方法说道的第三点,当当前的大小达到阀值(默认0.75*size),就会扩容,容量扩大为原来的两倍,扩容的过程会遍历原来的table,把它的元素重新计算在对应的新table中的位置,最坏时间复杂度为O(n^2);而在hash不冲突的场景下,不需要扩容的话,实际的时间复杂度为O(1)(只需要按照得到的index放进去)。所以我们最好给HashMap一个初始值,这个值是2的指数幂,并且它呈上装载因子(默认0.75)后的大小大于我们实际需要的大小。例如,我们实际需要200,那么200/0.75 约等于267,那么实际大于方向靠近267的2的指数幂为2^9 = 512。
性能问题2:重写equals和hashCode方法:
首先明确这两者的关系:
A和B对象equals方法返回true,hasCode方法返回值必然一样;
A和B对象hashCode不一样,那么equals方法必须返回false。
A和B对象hashCode一样,不能判定A equals B。
所以equals方法返回true和hasCode方法返回值一样是充分非必要的关系。
从Collections.secondaryHash的方法看,最终散列的位置index是和key的hashCode有关的,如果key是引用类型对象,且没有重写hashCode,就会很容易出现hash冲突,在put的过程中,发生冲突就会沿着单链表遍历到最后并插入。这个时间复杂度也是O(n)。
同时,put和get的判定都有e.hash == hash && key.equals(e.key),如果不重写equals方法,默认用“==”判定,比较内存地址。如果key是引用对象,则必须是同一个引用才能判定是相同的对象。例如:
public class UserData {
public String mUserName;
UserData(String userName){
mUserName = userName;
}
public static void main(String[] arg){
HashMap<UserData,String> map = new HashMap<>(8);
map.put(new UserData("yue"),"yue");
String result = map.get(new UserData("yue"));
System.out.println("result="+result);
}
}输出的结果为null。所以不管是为了满足equals和hashCode充分非必要的关系,还是保障程序的健壮性,都应重写equals。
性能问题3:多线程问题
HashMap是非线程安全的,这点已经毋庸置疑。那多线程条件下,怎么个不安全呢?关键在于扩容的过程。现在已知,不管哪种实现(android、jdk各版本),扩容的过程都是遍历旧的table,然后把旧table中的元素填充到扩容后的table中。伪代码如下:
{
newTable = new Entry[oldCapacity*2];
for(int i = 0;i<oldCapacity;i++){
Entry e = oldTable[i];//取出老的数组上的entry
for(遍历冲突链e){
newTable[newIndex];//创建新数组
findNewIndex();//找到新的位置
updateNodes(newTable);//更新冲突链
}
}
}不同的jdk有不同方式的实现。其中最经典的jdk1.7的写法:
void transfer(Entry[] newTable, boolean rehash) {
//把旧的数据转存到新的table中
int newCapacity = newTable.length;
for (Entry<K,V> e : table) {
while(null != e) {
//在这有循环,有链表的next节点赋值,
Entry<K,V> next = e.next; //flag
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}
}以经典组合3、7、5,findNewIndex()为retrun key.hashCode() % table长度为例(这个例子很特殊,一会说为什么很特殊)。
假设:
HashMap<Integer,Object> map = new HashMap<>(2);
map.put(3,obj1);//node3
map.put(7,obj2);//node7
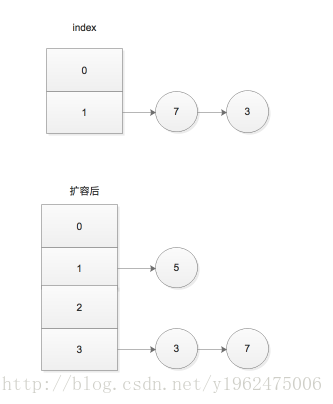
map.put(5,obj3);//node5按照(size++> threshold),那么在put7的时候,会扩容(注意++前置和后置的区别)此时的map的变化(冲突节点头插):
可以发现,原来index = 1的位置上,是Entry(7,obj1)->Entry(3,obj2);
扩容后:index = 3 的位置上,Entry(3,obj2)->Entry(7,obj1);顺序发生了倒置!如图:
假设:线程A和线程B,同时进到了上面标注的flag处。线程B挂起,线程A继续执行,那么A执行完的结果就是上图,在A的本地内存和JMM主内存newTable的情况是:
newTable[0]=null;
newTable[1]=node5;
newTable[2]=null;
newTable[3]=node3->node7(node3.next = node7);
此时线程B唤起开始执行,但是线程B的本地内存中的情况是执行之前的:newTable各个位置上没有值,
oldTable[0] = null;
oldTable[1] = node7->node3(node7.next = node3);
然后继续按mod4计算新的位置,此时node7的新位置应该在newTable的3上,即上述代码中i= 3;此时的e = node7;
然后执行e.next = newTable[3],注意此时的操作,对newTable是一个读操作,在JMM中,读操作都是直接从主内存中读取,所以现在的newTable[3] = node3->node7(node3.next = node7);于是有e.next = node3->node7,刚刚说到,e = node7,所以node7插在了单链表node3->node7之前,此时的newTable[3]= node7->node3->node7;死循环出现,线程B无法停止,耗尽CPU资源,只能重启机器。过程图如下:
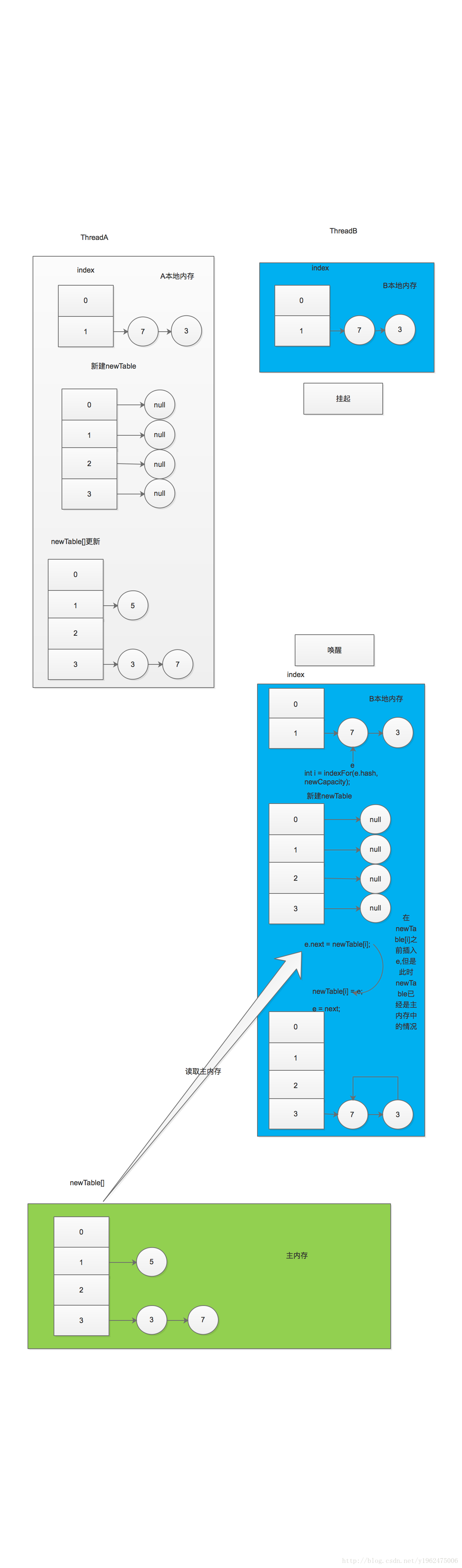
从上面的分析看,死循环的根源是:
1、原来的冲突链上的节点rehash(扩容)的时候又冲突在了一起(node3和node7);
2、findNewIndex()这个环节存在节点倒置。
3、多线程下的顺序一致性问题
这三个条件都满足,就可能会出现死循环。
为什么说这个例子很特殊呢?因为初始大小为2,扩容后为4,mod2时,这三个数会直接冲突到一个冲突链上,在扩容后重新计算index,3和7又产生了冲突。仅仅三个操作,就能模拟到不断冲突的情况。当然也许有人说这太特殊了,我们平时不可能这么写,但是谁都没法保证,程序实际使用过程中是否会发生这样的情况,Hash和rehash的算法优化固然可以减少死循环发生的几率,但是一旦发生,就是灾难性的。
回过头来看这个特殊例子在android的doubleCapacity的情况:
初始大小为2,3的hashCode为3,即011,7的hashCode为7,即111,5的hashCode为5,即101,那么在放3和7的时候,index分别为011&001 = 001 ->1,111&001 = 001 ->1,所以3和7是冲突在1的位置上的,由于是头插法,所以oldtable:
oldtable[0]= null;
oldtable[1]= node7->node3;
然后根据
int highBit = e.hash & oldCapacity;
HashMapEntry<K, V> broken = null;
newTable[j | highBit] = e;
扩容时,node7的highBit为111&010=010->2;node3的highBit为011&010=010->2;
根据
if (nextHighBit != highBit) {
if (broken == null)
newTable[j | nextHighBit] = n;
else
broken.next = n;
broken = e;
highBit = nextHighBit;
}
当前后两个相邻的节点的highBit相同时,对这条链内部不作处理,所以node7->node3直接指向了newTable[j | highBit]也就是newTable[2],新来的node5,直接根据index= hash & (tab.length - 1) = 101&011 = 001->1,放在了1的位置上。
这个分析可以看到,android的实现并不会造成节点倒置,不满足死循环的条件2,所以不会导致死循环。但是由于多线程下,每个线程都在更新冲突链,可能会出现put的值和预期不匹配的情况,所以我们仍要关注HashMap的并发问题。
解决这个问题有几个方法:
1、使用HashTable;
2、Collections.synchronizedMap处理HashMap;
3、使用ConcurrentHashMap
前两种性能太差,推荐使用第三种,ConcurrentHashMap使用CAS轻量级锁,性能更好。