这节课看的有点晕,断断续续看了3遍吧...
本节课主要讲的内容:
1.现代计算机如何存储人类语言,并进行显示或处理。python3中将其称为字符串(string)。
2.如何把python字符串(string)编码成为字节串(bytes),以及如何把字节串(bytes)解码成字符串(string)。
3.如何处理在字符串和字节处理中出现的错误。
4.如何阅读代码,并弄明白你看到的新东西。
5.还有简单了解 if 语句。
知识点:
原文过长,总结一下要点:
1. 1字节(byte)== 8位,就是二进制的8位数,计算机可以用8位数编写256个数字,00000000代表0、11111111代表255,0~255总共256个数字;
也有人认为1字节(byte)表示9位、7位等等,不过非常少见。还有一些用来表示更大数字的,会用到16位、32位、64位等等。
2. 编码标准:
ASCII(美国信息交换标准代码)是使用8位二进制(也就是1byte)数字来表示256个数字的编码方式,然后每个数字代表1个字符(例如26个大写字符+26个小写字母+10个数字+特殊字符等等,有兴趣可以百度下)。
但是这个标准只能对英语和部分西欧语言进行编码,世界上的语言多种多样,用到的字符数远远不止256个(例如中国常用汉字大约5000+)。为了解决这个问题,就有些人发明了Unicode(通用编码),Unicode提供的编码方案和ASCII表格类似,但是庞大很多,你可以用32位编码1个Unicode字符,它能装下所有的人类语言,还有表情符号等等。
但是32位是4bytes,这对于我们要编码的大部分类型的文本都是一种浪费。这个问题的解决方案就是把大部分常用字符用8位编码,如果需要编码更多的字符,就“逃”出去使用更大的数。于是我们又有了编码方式,就是一种压缩编码方式,叫UTF-8(Unicode Transformation Format 8 Bits)。
3. Python中字符串(string)和字节串(bytes)的转换:
把字节串(bytes)解码 成字符串(string): .decode()
把字符串(string)编码 成字节串(bytes): .encode()
研究代码:
首先需要一个叫languages.txt,下载地址是:https://learnpythonthehardway.org/python3/languages.txt 编码格式:UTF-8。
下面代码的启动方式 :C:\Users\Administrator\zet> py ex23.py utf-8 strict
#导入参数,argv的前面都学过,稍微有点不一样,但是结果都一样;
import sys
scirpt, encoding, error = sys.argv
#定义主函数 main ,内有三个形参
def main(language_file, encoding, errors):
#读取文件中的一行文本,并赋值给line,注意language_file是main主函数的实参
line = language_file.readline()
'''
if语句,用来检测line中是否为真值,如果为真,则执行下面2行代码,如果为假,则跳过不执行;
所以如果readling()返回包含东西,则继续执行下面2行,如果返回为null,则不执行,这是为了防止死循环;
'''
if line:
#在主函数main内调用了另外一个函数 print_line
print_line(line, encoding, errors)
#这个return是让我们在主函数main内又调用一次main,看上去不可能,实际上就是跳到main顶端在运行一次;
return main(language_file, encoding, errors)
#定义 print_line 函数,内有3个形参,这个函数的作用就是对languages.txt里的每一行进行编码
def print_line(line, encoding, errors):
#.strip()的作用删掉每行结尾的\n
next_lang = line.strip()
#.encode()的作用:把每一行字符串编码成字节串bytes
raw_bytes = next_lang.encode(encoding, errors = errors)
#.decode()的作用:把每一行字节串解码成字符串string
cooked_string = raw_bytes.decode(encoding, errors = errors)
#打印: ”字节串 <===> 字符串“
print(raw_bytes, "<==>", cooked_string)
#把languages.txt文件以utf-8的编码方式打开
languages = open("languages.txt", encoding = "utf-8")
'''
上面都是定义函数,现在开始调用函数,main函数的执行顺序:
1.传入三个参数,languages, encoding, error, language是第32行的变量,后2个是第3行的变量;
2.第8行:读取languages的一行文本,赋值给line
3.第13行:做个判定,判定第15行的函数返回的结果,如果为真,执行第15、17行代码,如果为假,则不执行
4.第15行:调用print_line函数,这个函数删除了第8行读取的一行文本后面的\n,
然后把这行文本编码成字节串,赋值给raw_bytes变量待用,
又把raw_bytes变量解码成字符串,赋值给cooked_string变量待用,最后按照格式打印出来;
5.然后交由第13行的if进行判定第15行打印的内容是否位null,如果不为null,则执行第17行;
6.第17行再次调用main函数,重复上面的顺序,最后结果就是把languages.txt文件的每一行读取出来进行编码、解码、打印。
7.然后当所有的内容都读取完后,再次调用main函数,则第13行的if此时会发现返回结果为null,
然后就会停止执行return,循环结束,整段代码执行完毕。
'''
main(languages, encoding, error)
结果:
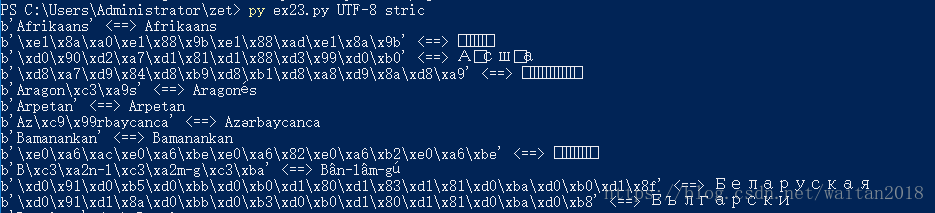

运行结果中间有一段没截图,太长了。“<===> ”左边显示的都是bytes,右边显示的是string。
右边有些显示为框框,这是powershell没法显示的utf-8。
代码看了3遍才看懂,注意看注释;