版权声明:本文为博主原创文章,保留著作权,未经博主允许不得转载。 https://blog.csdn.net/LoseInVain/article/details/82822631
贝叶斯曲线拟合以及对L2正则化的贝叶斯解释
在以前文章中,我们讨论过《概率学派和贝叶斯学派的区别》 和《 <机器学习系列> 线性回归模型》 ,这里我们讨论下曲线拟合问题中的数据点的噪声问题,以及根据贝叶斯理论的L2正则化解释。
如有谬误,请联系指正。转载请注明出处。
联系方式: e-mail : [email protected] QQ : 973926198github : https://github.com/FesianXu
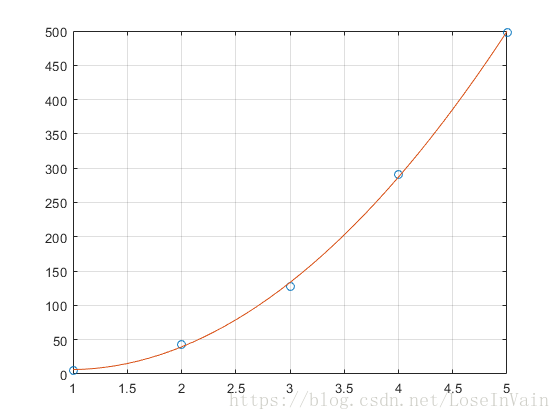
这里的曲线指的是多项式曲线(polynomial curve),如下图所示:
一般来说,概率学派按照最小化平方和误差函数,如下所示,来进行参数的学习的。
(1.1)
T
θ
=
arg
min
θ
L
(
y
^
,
y
)
y
^
j
=
∑
i
=
0
N
θ
i
x
(
i
,
j
)
i
=
y
(
x
;
θ
)
L
(
y
^
,
y
)
=
1
2
∣
∣
y
^
−
y
∣
∣
2
\mathcal{T}_{\theta} = \arg \min_{\theta} \mathcal{L}(\hat{y},y) \\ \hat{y}_j = \sum_{i=0}^N \theta_i x_{(i,j)}^{i} = y(x;\theta)\\ \mathcal{L}(\hat{y}, y) = \dfrac{1}{2}||\hat{y}-y||^2 \tag{1.1}
T θ = arg θ min L ( y ^ , y ) y ^ j = i = 0 ∑ N θ i x ( i , j ) i = y ( x ; θ ) L ( y ^ , y ) = 2 1 ∣ ∣ y ^ − y ∣ ∣ 2 ( 1 . 1 )
x
(
i
,
j
)
x_{(i,j)}
x ( i , j )
j
j
j
i
i
i
但是按照上面策略进行曲线拟合是没有考虑到数据的不确定性(uncertainty)的,这种不确定性体现在数据是添加了噪声的,而基于直接估计出一个点,然后直接拟合的方式没有考虑到这种噪声。为了描述这种不确定性,我们接下来以一种概率的角度去看待曲线拟合问题。
假设我们通过多项式模型预测出来的并不是一个单纯的数字,而是一个分布,一般来说我们将其假设为是一个均值为
t
t
t
σ
2
\sigma^2
σ 2
β
=
1
σ
2
\beta=\dfrac{1}{\sigma^2}
β = σ 2 1
β
\beta
β
(1.2)
p
(
t
∣
x
,
w
,
β
)
=
N
(
t
∣
y
(
x
,
w
)
,
β
−
1
)
p(t|x, \textbf{w}, \beta) = \mathcal{N} (t|y(x, \textbf{w}), \beta^{-1}) \tag{1.2}
p ( t ∣ x , w , β ) = N ( t ∣ y ( x , w ) , β − 1 ) ( 1 . 2 ) 我们假设数据添加的噪声是高斯噪声 ,既是:
(1.3 数据的噪声分解模型)
x
o
b
s
e
r
v
e
=
x
r
e
a
l
+
N
(
μ
,
σ
2
)
\mathbf{x}_{\rm{observe}} = \mathbf{x}_{\rm{real}}+\mathcal{N}(\mu,\sigma^2) \tag{1.3 数据的噪声分解模型}
x o b s e r v e = x r e a l + N ( μ , σ 2 ) ( 1 . 3 数 据 的 噪 声 分 解 模 型 )
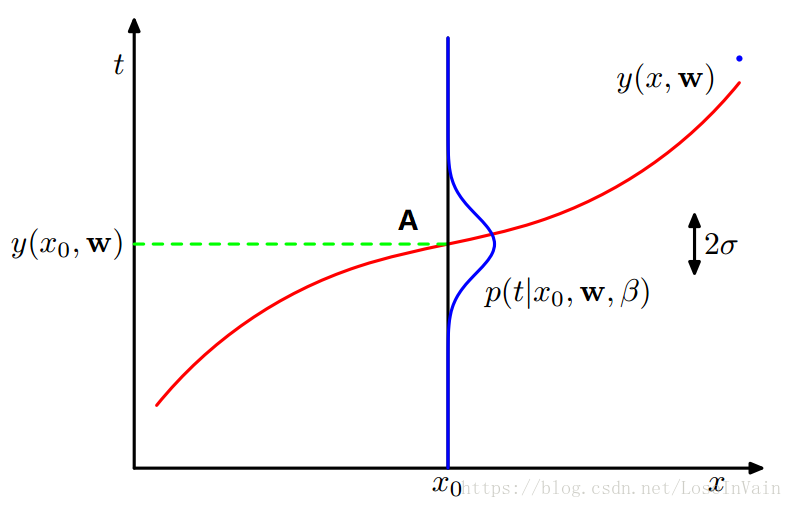
可以看出,对于某一个预测,其为一个分布(蓝色线),其中预测的均值的预期就是观察值点A,可以看出,参数
β
\beta
β
2
σ
2\sigma
2 σ
2
σ
2\sigma
2 σ
如果采用频率学派中的观点,那么就会采用极大似然法 进行参数估计。似然函数如下所示:
(1.4)
p
(
t
∣
x
,
w
,
β
)
=
∏
i
=
0
N
N
(
t
n
∣
y
(
x
n
,
w
)
,
β
−
1
)
p(\textbf{t}|\textbf{x},\textbf{w}, \beta) = \prod_{i=0}^N \mathcal{N} (t_n | y(x_n, \textbf{w}), \beta^{-1}) \tag{1.4}
p ( t ∣ x , w , β ) = i = 0 ∏ N N ( t n ∣ y ( x n , w ) , β − 1 ) ( 1 . 4 )
(1.5)
L
=
ln
p
(
t
∣
x
,
w
,
β
)
=
−
β
2
∑
n
=
1
N
{
y
(
x
n
,
w
)
−
t
n
}
2
+
N
2
ln
β
−
N
2
ln
(
2
π
)
\mathcal{L} = \ln p(\textbf{t}|\textbf{x},\textbf{w}, \beta) \\ = -\dfrac{\beta}{2} \sum_{n=1}^N \{y(x_n, \textbf{w})-t_n\}^2 + \dfrac{N}{2}\ln \beta - \dfrac{N}{2} \ln (2\pi) \tag{1.5}
L = ln p ( t ∣ x , w , β ) = − 2 β n = 1 ∑ N { y ( x n , w ) − t n } 2 + 2 N ln β − 2 N ln ( 2 π ) ( 1 . 5 )
w
\mathbf{w}
w
L
\mathcal{L}
L
w
\mathbf{w}
w
w
\mathbf{w}
w
β
\beta
β
w
\mathbf{w}
w
β
=
1
\beta=1
β = 1
(1.6)
L
=
−
1
2
∑
n
=
1
N
{
y
(
x
n
,
w
)
−
t
n
}
2
T
=
max
w
L
=
min
w
−
L
\mathcal{L} = -\dfrac{1}{2} \sum_{n=1}^N \{y(x_n, \textbf{w})-t_n\}^2 \\ \mathcal{T} = \max_{\mathbf{w}} \mathcal{L} = \min_{\mathbf{w}} \mathcal{-L} \tag{1.6}
L = − 2 1 n = 1 ∑ N { y ( x n , w ) − t n } 2 T = w max L = w min − L ( 1 . 6 ) 平方和损失 ,因此我们得出结论:
∇
\nabla
∇ 平方和损失,是在假设数据噪声符合0均值高斯分布的情况下推导出的。
∇
\nabla
∇
当然,这里的精度
β
\beta
β
(1.7)
1
β
^
=
1
N
∑
n
=
1
N
{
y
(
x
n
,
w
)
^
−
t
n
}
2
\frac{1}{\hat{\beta}} = \frac{1}{N} \sum_{n=1}^N \{y(x_n,\hat{\mathbf{w})}-t_n\}^2 \tag{1.7}
β ^ 1 = N 1 n = 1 ∑ N { y ( x n , w ) ^ − t n } 2 ( 1 . 7 )
w
^
\hat{\mathbf{w}}
w ^
注意到我们之前讨论的都是没有对参数
w
\mathbf{w}
w
w
\mathbf{w}
w
α
\alpha
α
(2.1 对参数的先验假设)
p
(
w
∣
α
)
=
N
(
w
∣
0
,
α
−
1
I
)
=
(
α
2
π
)
(
M
+
1
)
/
2
e
x
p
{
−
α
2
w
T
w
}
p(\mathbf{w}|\alpha) = \mathcal{N}(\mathbf{w}|\mathbf{0},\alpha^{-1}\mathbf{I}) \\ = (\frac{\alpha}{2\pi})^{(M+1)/2} \rm{exp}\{-\frac{\alpha}{2}\mathbf{w}^T\mathbf{w}\} \tag{2.1 对参数的先验假设}
p ( w ∣ α ) = N ( w ∣ 0 , α − 1 I ) = ( 2 π α ) ( M + 1 ) / 2 e x p { − 2 α w T w } ( 2 . 1 对 参 数 的 先 验 假 设 )
M
M
M
α
\alpha
α 超参数(hyperparameters) 。
(2.2)
p
(
w
∣
x
,
t
,
α
,
β
)
∝
p
(
t
∣
x
,
w
,
β
)
p
(
w
∣
α
)
p(\mathbf{w}|\mathbf{x},\mathbf{t},\alpha,\beta) \propto p(\mathbf{t}|\mathbf{x},\mathbf{w},\beta)p(\mathbf{w}|\alpha) \tag{2.2}
p ( w ∣ x , t , α , β ) ∝ p ( t ∣ x , w , β ) p ( w ∣ α ) ( 2 . 2 )
{
x
,
t
}
\{\mathbf{x},\mathbf{t}\}
{ x , t }
w
\mathbf{w}
w
w
\mathbf{w}
w 最大后验概率法(MAximum Posterior,MAP) 。取(2.2)的负对数,我们有:
(2.3)
ln
p
(
w
∣
x
,
t
,
α
,
β
)
∝
ln
p
(
t
∣
x
,
w
,
β
)
+
ln
p
(
w
∣
α
)
\ln{p(\mathbf{w}|\mathbf{x},\mathbf{t},\alpha,\beta)} \propto \ln{p(\mathbf{t}|\mathbf{x},\mathbf{w},\beta)}+\ln{p(\mathbf{w}|\alpha)} \tag{2.3}
ln p ( w ∣ x , t , α , β ) ∝ ln p ( t ∣ x , w , β ) + ln p ( w ∣ α ) ( 2 . 3 )
w
\mathbf{w}
w
β
2
∑
n
=
1
N
{
y
(
x
n
,
w
)
−
t
n
}
2
+
α
2
w
T
w
⇒
1
2
∑
n
=
1
N
{
y
(
x
n
,
w
)
−
t
n
}
2
+
α
β
w
T
w
\frac{\beta}{2}\sum_{n=1}^N \{y(x_n,\mathbf{w})-t_n\}^2+\frac{\alpha}{2}\mathbf{w}^T\mathbf{w} \\ \Rightarrow \frac{1}{2}\sum_{n=1}^N \{y(x_n,\mathbf{w})-t_n\}^2+\frac{\alpha}{\beta}\mathbf{w}^T\mathbf{w}
2 β n = 1 ∑ N { y ( x n , w ) − t n } 2 + 2 α w T w ⇒ 2 1 n = 1 ∑ N { y ( x n , w ) − t n } 2 + β α w T w
γ
=
α
β
\gamma=\dfrac{\alpha}{\beta}
γ = β α
γ
2
w
T
w
\dfrac{\gamma}{2}\mathbf{w}^T\mathbf{w}
2 γ w T w
∇
\nabla
∇ 在贝叶斯理论中,L2正则项是在参数
w
\mathbf{w}
w
γ
\gamma
γ
∇
\nabla
∇
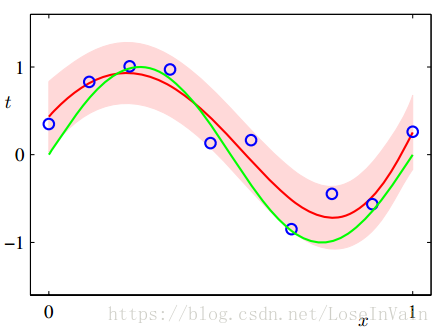
在上一步中,虽然我们根据最大后验法估计出了
w
\mathbf{w}
w
t
^
\hat{\mathbf{t}}
t ^
w
\mathbf{w}
w
t
^
\hat{\mathbf{t}}
t ^
w
\mathbf{w}
w
{
x
,
t
}
\{\mathbf{x},\mathbf{t}\}
{ x , t }
x
x
x
t
t
t
p
(
t
∣
x
,
x
,
t
)
p(t|x,\mathbf{x},\mathbf{t})
p ( t ∣ x , x , t )
(3.1)
p
(
t
∣
x
,
x
,
t
)
=
∫
p
(
t
∣
x
,
w
)
p
(
w
∣
x
,
t
)
d
w
p(t|x,\mathbf{x},\mathbf{t}) = \int p(t|x,\mathbf{w})p(\mathbf{w}|\mathbf{x},\mathbf{t}) \rm{d} \mathbf{w} \tag{3.1}
p ( t ∣ x , x , t ) = ∫ p ( t ∣ x , w ) p ( w ∣ x , t ) d w ( 3 . 1 )
(3.2)
p
(
t
∣
x
,
x
,
t
)
=
N
(
t
∣
m
(
x
)
,
s
2
(
x
)
)
p(t|x,\mathbf{x},\mathbf{t}) = \mathcal{N}(t|m(x),s^2(x)) \tag{3.2}
p ( t ∣ x , x , t ) = N ( t ∣ m ( x ) , s 2 ( x ) ) ( 3 . 2 )
(3.3)
m
(
x
)
=
β
ϕ
(
x
)
T
S
∑
n
=
1
N
ϕ
(
x
n
)
t
n
m(x) = \beta \phi(x)^T \mathbf{S} \sum_{n=1}^N \phi(x_n) t_n \tag{3.3}
m ( x ) = β ϕ ( x ) T S n = 1 ∑ N ϕ ( x n ) t n ( 3 . 3 )
(3.4)
s
2
(
x
)
=
β
−
1
+
ϕ
(
x
)
T
S
ϕ
(
x
)
s^2(x) = \beta^{-1}+\phi(x)^T\mathbf{S}\phi(x) \tag{3.4}
s 2 ( x ) = β − 1 + ϕ ( x ) T S ϕ ( x ) ( 3 . 4 )
(3.5)
S
−
1
=
α
I
+
β
∑
n
=
1
N
ϕ
(
x
n
)
ϕ
(
x
)
T
\mathbf{S}^{-1} = \alpha\mathbf{I}+\beta \sum_{n=1}^N \phi(x_n)\phi(x)^T \tag{3.5}
S − 1 = α I + β n = 1 ∑ N ϕ ( x n ) ϕ ( x ) T ( 3 . 5 )
ϕ
(
x
)
=
x
i
,
i
=
0
,
⋯
 
,
M
\phi(x)=x^i,i=0,\cdots,M
ϕ ( x ) = x i , i = 0 , ⋯ , M
m
(
x
)
m(x)
m ( x )
x
x
x
w
\mathbf{w}
w
[1] Bishop C M. Pattern recognition and machine learning (information science and statistics) springer-verlag new york[J]. Inc. Secaucus, NJ, USA, 2006.《概率学派和贝叶斯学派的区别》 《 <机器学习系列> 线性回归模型》 《随机梯度下降法,批量梯度下降法和小批量梯度下降法以及代码实现》 《机器学习模型的容量,过拟合与欠拟合》 《先验概率、后验概率以及共轭先验》