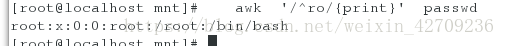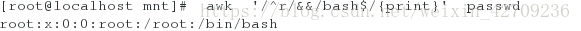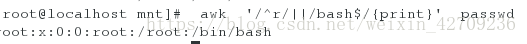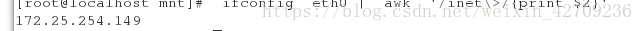一.Grep的用法
grep Global search regular expression and print out the line
(全面搜索研究正则表达式并显示出来)grep 命令是一种强大的文本搜索工具 , 根据用户指定的“模式”对目标文本进行匹配检查 ,
打印匹配到的行由正则表达式或者字符及基本文本字符所编写的过滤条件1.过滤指定字符
(1)grep中字符的匹配次数的设定
* 字符出现0到任意次
? 字符出现0到1次
+ 字符出现1到任意次
{n} 字符出现n次
{m,n} 字符最多出现n次,最少出现m次
{0,n} 字符出现最多n次
{m,} 字符最少出现m次
(xy){n} xy关键字出现n次
.*关键字之间匹配任意字符
'a..b' a和b之间有两个任意字符
'a...' a后边有三个任意字符
'...b' b前边有三个任意字符
(2) grep中字符位置的设定
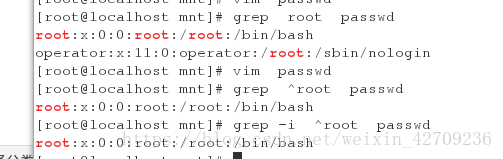
^关键字 以关键字开头的行
关键字$ 以关键字结尾的行
\<关键字 关键字前边不能出现别的字符
关键字 >\ 关键字之后不能有别的字符
二. Sed
sed stream editor(行编辑器)用来操作纯 ASCII 码的文本处理时 , 把当 前处理的行存储在临时缓冲区中 , 称为“模式空间” (pattern space) 可以指定仅仅处理哪些行。sed 符合模式条件的处理不符合条件的不予处理,处理完成之后把缓冲区的内容送往屏幕接着处理下一行 , 这样不断重复 , 直到文件末尾。
1.sed对字符的处理
p 显示 d 删除 a 添加 c 替换 w 写入 i 插入
2.p操作模式
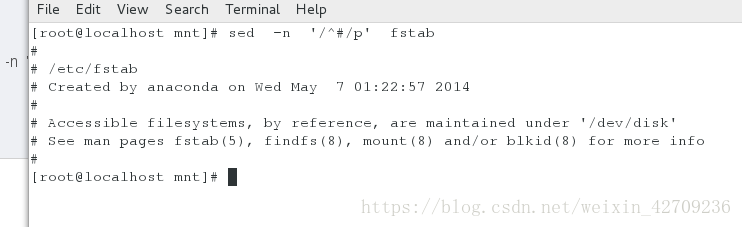
显示fstab以#开头的行 sed -n '/^#/p' fstab
显示不以#开头的行(注意!的位置) sed -n '/^#/!p' fstab
显示fstab的2-6行 cat -n fstab | sed -n '2,6p'
显示fstab的2行和6行 cat -n fstab | sed -n -e '2p;6p' cat -n fstab | sed -n -e '2p' -e '6p'
3.d操作模式
不显示空行 sed -e '/^$/d' fstab 不显示空行和以#开头的 sed -e '/^#/d;/^$/d' fstab
4.a操作模式
在file文件中hello后加上world sed '/hello/aworld' file
在file文件hello后加上hello world 并换行 sed '/hello/ahello\nworld' file
5.i操作模式
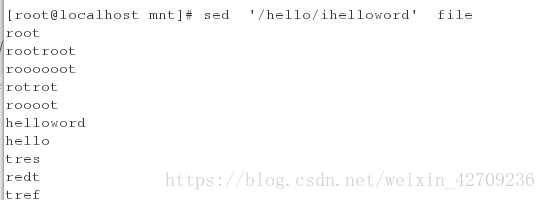
将指定内容插入在hello前边 sed '/hello/ihelloword' file
6.c操作模式
将file中的hello替换成指定字符 sed '/hello/chelloword' file
7.w操作模式
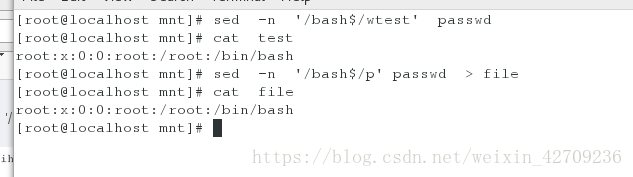
把passwd中以bash结尾的写入文件test sed -n '/bash$/wtest' passwd sed -n '/bash$/p' passwd > file 这两条命令的区别在于第一条是一条命令而第二个是两条命令,第一个处理一行写进一行,第二个是全部处理完才写进去
8.sed 的其他用法
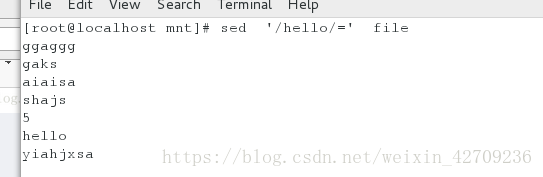
显示file中的行号,与行内容分开 sed '/hello/=' file
将file中的内容加入到fstab中第六行之后 sed '6r file'fstab
仅显示某一行的行号 sed -n '/UUID/=' fstab
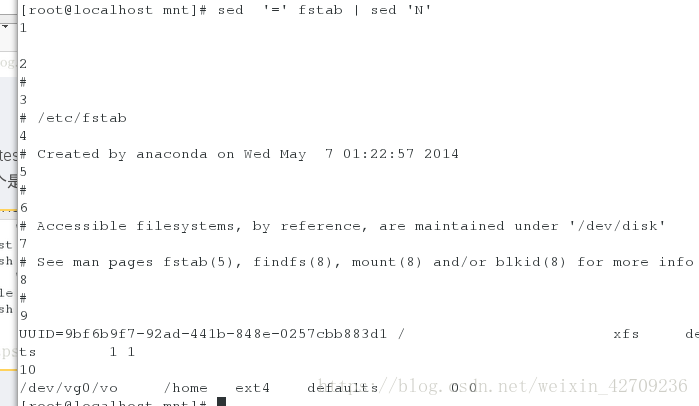
显示每一行的行好并换行 sed '=' fstab | sed 'N'
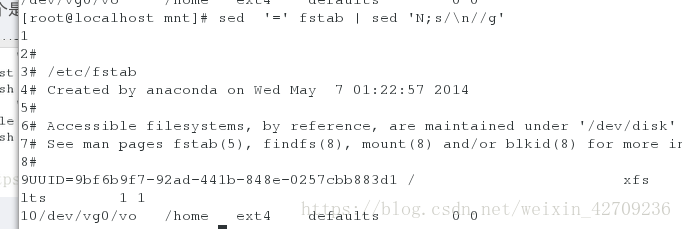
显示每一行的行好不换行 sed '=' fstab | set 'N;s/\n//g' N是将换行符显示出来
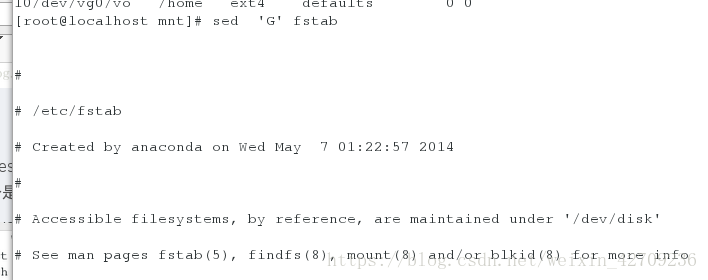
给每一行后便加上空行 sed 'G' fstab
9.替换
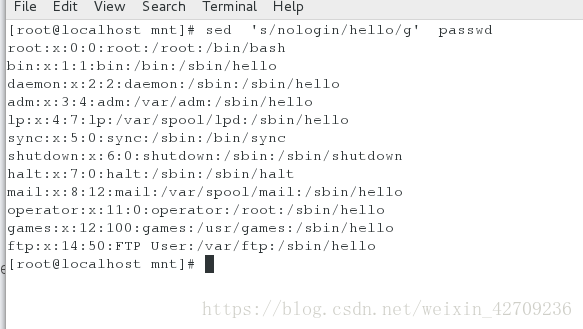
全文替换nologin为hello sed 's/nologin/hello/g' passwd
只替换每一行第一个nologin为hello sed 's/nologin/hello/' passwd
替换3-5行nologin为hello sed '3,5s/nologin/hello/g' passwd
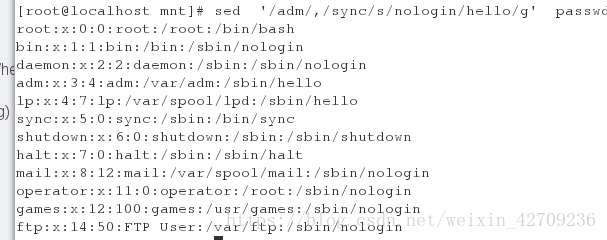
替换两个关键字adm和sync之间的nologin为hello sed '/adm/,/sync/s/nologin/hello/g' passwd
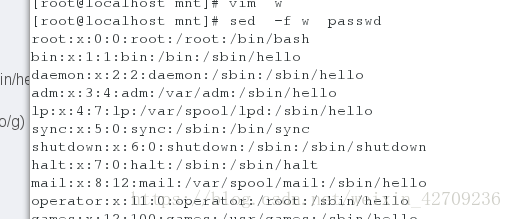
在文件中写替换策略,调用文件替换 sed -f file passwd file(s/nologin/hello/g)
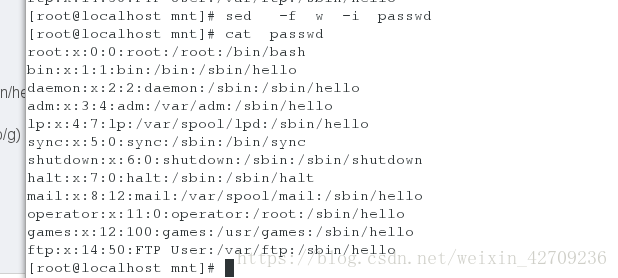
调用文件替换并改变原文件的内容 sed -f file -i passwd
3.awk
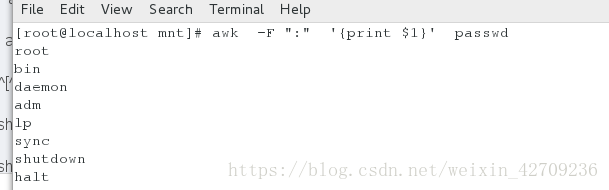
awk 报告生成器 awk的处理机制:逐行处理文本 , 支持在处理第一行之前做一些准备工作 , 以及在处理完最后一行做一些总结性质的工作 , 在命令格式上分别体现如下 : BEGIN{}: 读入第一行文本之前执行 , 一般用来初始化操作 {}: 逐行处理 , 逐行读入文本执行相应的处理 , 是最常见的编辑指令快 END{}: 处理完最后一行文本之后执行 , 一般用来输出处理结果显示passwd的第一列 awk -F ":" '{print $1}' passwd
在第一列列首加name,列 尾加end awk -F ":" 'BEGIN{print "name"} {print $1} END{print "end"}' passwd
显示行号 awk -F ":" BEGIN{print "name"} {print NR$1} END{print "end"} passwd
统计系统中能登陆系统的用户个数 awk -F ":" 'BEGIN{N=0}/bash$/{N++} END{print N}' /etc/passwd
找出passwd中以ro开头的行 awk '/^ro/{print}' passwd
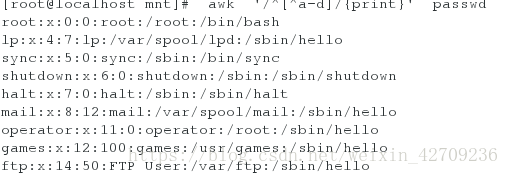
找出passwd中以a-d开头的行 awk '/^[a-d]/{print}' passwd
找出不以a-d开头的行 awk '/^[^a-d]/{print}' passwd
找出passwd中以r开头和以bash结尾的行 awk '/^r/&&/bash$/{print}' passwd
找出passwd中以r开头或以bash结尾的行 awk '/^r/||/bash$/{print}' passwd
找出passwd中第五列以a开头的行 awk -F ":" "$5~/^a/{print}" passwd
找出passwd中第1列不以a开头的行 awk -F ":" "$1!~/^a/{print}" passwd
抓取eth0网卡的ip ifconfig eth0 | awk '/inet\>/{print $2}'