文章目录
Chapter 1: Introduction
人类与环境进行互动,学习环境如何响应我们的行为,并试图通过自身行为影响将来发生的事,这就是一种交互式的学习方式,是人类获取知识的主要来源,同时也是几乎所有学习和智能化理论的基本思想。强化学习正是一种从交互中学习的计算方法,它更侧重于从交互中进行目标导向的学习方式,而不是其他的机器学习方式。
1.1 Reinforcement Learning
强化学习特征
强化学习就是学习该做什么,如何将情境映射到动作从而最大化奖励信号。试错搜索(trial-and-error search)和延迟奖励(delayed reward)是强化学习两个最重要的显著特征,另一个重要特征是强化学习并不局限于孤立的子问题,即:
· 学习者不会被告知需要采取哪些行动,而是必须通过尝试来发现哪些行动可以产生最大的回报;
· 当前行动不仅影响即时奖励,还会影响下一个state,以及后续奖励;
· 明确考虑了目标导向的agent与不确定环境交互的整个问题。
强化学习与其他人工智能技术的区别
监督学习:是从一组有标记的训练集中进行学习,目的是让系统归纳与推断其响应,使其在训练集中不存在的样例下也能正确做出相应action。监督学习是一种重要的学习方式,但其不足以从交互中学习。在交互问题中获取正确而又代表所有情况的所期望行为的样例是不切实际的。在未知领域,agent必须能够从自身经验中学习才能习得最有益的action。
非监督学习:通常是寻找隐藏在未标记数据集合中的某种结构。虽然强化学习也不需要带有正确标记的例子,但它的目标是最大化奖励信号,而不是试图找到隐藏的结构。当然,找到agent学习经验中的隐藏结构也是有用的,但这并不是最终目标。
强化学习的挑战
探索与开发的权衡(trade-off between exploration and exploitation)。为了获得大量奖励,agent必须更倾向于过去尝试过的行为,并且发现他们能够有效地产生奖励。但是要发现这样的行为,agent必须尝试以前没有尝试过的行为,它必须利用它已经经历的经验来获得奖励,但也必须进行探索,以便在将来做出更好的选择。困难在于,任何探索和开发都有可能会失败,agent必须尝试各种操作,并逐渐倾向于那些看起来最好的操作。在随机任务中,必须多次尝试每一个action以获得对其期望奖励的可靠估计。
1.3 Elements of Reinforcement Learning
策略(policy):策略定义了agent在给定时间内的行为方式。策略是从感知的环境状态到该state下action的映射。通常策略可以是随机的,指定每个action的概率。
奖励信号(reward signal):奖励信号定义了强化学习问题的目标,是agent一次action后的反馈,说明了agent某个action对于目标而言是有利的还是有害的。奖励信号是更改策略的基础,如果回报低,下次遇到相同的情况,agent就会采取不同的action。agent唯一的目标是最大化累计获得的奖励。
值函数(value function):state的值表示agent以该state为起点,未来可期望的各个state回报的总和。奖励信号表示该state直接意义上的好坏,但值函数表示了以该state为起点,长期运行中的好坏。我们寻求的action应该是带来最高value而非最高reward。
环境模型(model of the environment):利用models来解决强化学习的方法为model-based method,反之叫做model-free method。对环境进行建模,不必在真实环境中试验每一action,给定state和action,model会给出下一个state和返回的reward,极大减小了试错搜索的成本,是未来新的发展方向。
1.4 Limitations and Scope
进化方法(evolutionary methods):如果策略空间较小,或可以被结构化(好的策略容易被检索到),或者有大量时间可以用于搜索,则进化方法是可行的。此外,进化方法在agent无法感知其环境的完整状态的问题上具有优势。
强化学习方法:进化方法(EM)只看policy的最后结果而不考虑中间的演变的过程。而强化学习方法在与环境的交互中学习,许多情况下,可以利用个体行为相互作用的细节。进化方法忽略了强化学习问题的许多有用结构:EM没有利用所搜索的policy是states到actions的映射这个事实;EM没有注意到agent一生经过了哪些states,选择了哪些actions。虽然某些情况下,该信息可能具有误导性(例如state被误观察),但更一般的,这些信息会带来更高效的搜索。
1.5 An Extended Example: Tic-Tac-Toe
优化方法对比
以“井”字游戏为例说明了传统的AI方法如minimax、dynamic programming、evolutionary method都不太适合即使是这么简单的RL问题。
经典的博弈论的minimax解决方案在这里是不正确的,因为它假定了对手的特定玩法。
用于顺序决策问题的经典优化方法,例如dynamic programming,可以为任何对手计算最优解,但需要输入该对手的完整规范,包括对手在每个棋盘状态下进行每次移动的概率。
为了评估策略,进化方法使得策略固定并且针对对手玩许多次游戏,或者使用对手的模型模拟许多次游戏。胜利的频率给出了对该策略获胜概率的无偏估计,并且可用于指导下一个策略的选择。但是每次策略更改都是在许多游戏之后进行的,并且只使用每个游戏的最终结果:在游戏期间发生的事情会被忽略。例如,如果玩家获胜,那么游戏中的所有行为都会被信任,而不管具体哪些actions对获胜至关重要,甚至可以归功于从未发生过的actions。
相反值函数方法允许评估各个states。最后,进化和值函数方法都在搜索策略空间,但学习值函数会利用游戏过程中可用的信息。
value function方法步骤
- 建立数据表,每个数据都代表游戏中的一个可能state,每个数字都是我们从该state获胜概率的最新估计;
- 假设我们总是玩X,那么连续三个X的value是1,连续三个O的value为0,其他状态的初始值设置为0.5,表示我们有50%的获胜机会;
- 进行多场游戏,大多数时候我们采用贪婪式方法,选择导致具有最大value的state移动,即具有最高的估计获胜概率。但偶尔也会采取随机下法即探索性动作;
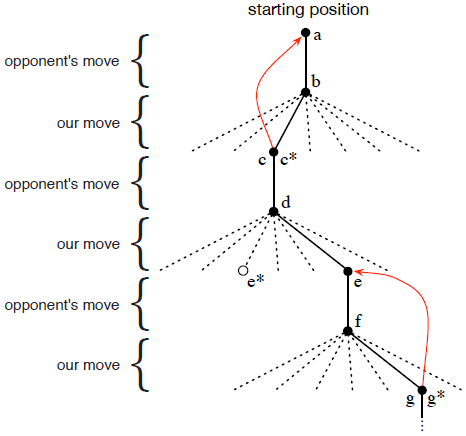
- 在贪婪选择时,使用时间差分法(temporal-di↵erence)更新之前state的value:
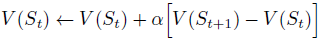
α为步长,S为state,V()为value。 - 可以通过改变α慢慢趋向于0使得这个方法收敛到一个最优策略;也可以不改变α使得策略不断改变以对抗对手。
扩展
本小节引出如下几点思考:
- 将先验知识应用到强化学习中可以改善学习效果;
- 强化学习的动作,除了像这个游戏这种离散的,也可能是连续的,value函数也可能是连续函数;
- 监督学习为程序提供了从其经验中概括(泛化)的能力。因此当状态集非常大甚至无限时,将监督学习方法与强化学习方法相结合是一个很好的解决途径。ANN和DL并不是唯一的或最好的方法;
- 如果能够获得或构建一个环境模型,则强化学习效果与效率会更好更高。
1.7 Early History of Reinforcement Learning
本小节讲述了RL的三条研究主线:
- learning with trial and error;
- optimal control and its solution using value functions and dynamic programming(planning);
- TD-methods。
Exercise
Exercise 1.1:Self-Play Suppose, instead of playing against a random opponent, the reinforcement learning algorithm described above played against itself, with both sides learning. What do you think would happen in this case? Would it learn a different policy for selecting moves?
译:假设上述强化学习算法不是与随机对手比赛,而是双方都在学习。 在这种情况下你认为会发生什么? 是否会学习选择行动的不同策略?
答:对于固定的对手来说,算法可能是次优的,对于随机对手而言,算法可能是最优的。对抗式学习和足够的探索相较于一个固定的对手可以产生更为强大的智能体。最后两个智能体应该会达到某种动态平衡,或是某方一直输,另一方一直赢(初始动作或顺序可能影响了学习策略)。
Exercise 1.2:Symmetries Many tic-tac-toe positions appear different but are really the same because of symmetries. How might we amend the learning process described above to take advantage of this? In what ways would this change improve the learning process? Now think again. Suppose the opponent did not take advantage of symmetries. In that case, should we? Is it true, then, that symmetrically equivalent positions should necessarily have the same value?
译:许多井字位置看起来不同,但由于对称性,它们实际上是相同的。我们如何修改上述学习过程以利用这一点?这种变化会以何种方式改善学习过程? 现在再想一想。假设对手没有利用对称性。在那种情况下,我们应该吗?那么,对称等价的位置是否必须具有相同的值?
答:可以依据4个轴的对称性对状态空间进行约减,即对称移动视为属于相同的状态空间,进而将减少实际的状态数量,加速学习。如果对手没有利用对称性,则其策略会区分“对称”状态,这可能导致我们算法整体性能变差。例如,如果对手在一个状态空间中存在弱点但在另一个状态空间中没有(即使它们是对称的),则对称相似的状态应该具有相同的值是不正确的,因此,这种情况下我们也不应该使用对称性。
Exercise 1.3:Greedy Play Suppose the reinforcement learning player was greedy, that is, it always played the move that brought it to the position that it rated the best. Might it learn to play better, or worse, than a nongreedy player? What problems might occur?
译:假设强化学习者是贪婪的,也就是说,它总是做出能够把它带到它认为最好的位置的动作。它可能会比一个不贪婪的学习者学的更好或更差吗?可能会出现什么问题?
答:一般而言,贪婪玩家的学的可能会更差。贪婪玩家会追求最大的即时reward,而好的学习策略应该是追求最大的value,即累积回报。如果每一步都追求最好的动作,我们可能永远找不到最优解。贪婪玩家可能会陷入局部最优点。
Exercise 1.4:Learning from Exploration Suppose learning updates occurred after all moves, including exploratory moves. If the step-size parameter is appropriately reduced over time (but not the tendency to explore), then the state values would converge to a different set of probabilities. What (conceptually) are the two sets of probabilities computed when we do, and when we do not, learn from exploratory moves? Assuming that we do continue to make exploratory moves, which set of probabilities might be better to learn? Which would result in more wins?
译:假设在所有动作之后发生了学习更新,包括探索性动作。 如果步长参数随时间适当减小(但不是探索的趋势),则状态值将收敛到不同的概率集。 什么(概念上)是我们这样做时计算的两组概率,当我们不这样做时,从探索性动作中学习? 假设我们继续做出探索性的动作,哪一组概率可能更好学习? 哪会赢得更多?
答:一个状态的值是从一个状态开始直到获胜的可能性。随着步长的适当减少,且假设探索的概率是固定的,没有从探索中学习的概率集是给定从此采取的最佳行动的每个状态的值,而从探索中学习的概率集是包括主动探索策略在内的每个状态的期望值。使用前者能够更好地学习,因为它避免了算法一味地进行贪婪式的行动,可能到达一个一般来说我们永远不会到达的状态,进而减少了次优的未来状态的偏差(例如,如果你可以在一次移动中赢得一盘棋,但如果你执行另一次移动你的对手获胜,这不会使该状态变坏)。前者会在所有其他条件相同的情况下获得更多胜利。
Exercise 1.5:1.5 Other Improvements Can you think of other ways to improve the reinforcement learning player? Can you think of any better way to solve the tic-tac-toe problem as posed?
译:你能想到其他改善强化学习者的方法吗?你能想出更好的方法来解决所提出的井字游戏问题吗?
答:根据对手行为的变化改变探索率。加大损失的惩罚力度。
Reference:
[1] 《reinforcement learning:an introduction》第一章《The Reinforcement Learning Problem》总结:https://blog.csdn.net/mmc2015/article/details/74931291
[2] 强化学习经典入门书的读书笔记系列–第一篇:https://zhuanlan.zhihu.com/p/27133367
[3] Reinforcement Learning:An Introduction 读书笔记- Chapter 1:https://blog.csdn.net/PeytonPu/article/details/78450681
[4] rl-book-exercises:https://github.com/jlezama/rl-book-exercises
本博客与https://xuyunkun.com同步更新