交流请加群:580043385
我的知乎专栏同步发布:https://zhuanlan.zhihu.com/p/22542101
转载请标明出处:http://blog.csdn.net/ikerpeng/article/details/52604506
这是Nvidia 发表的自己家开发者博客上的一篇关于深度强化学习的通俗讲义,主要是从概念上来理解强化学习。(其余的还包括 RNN的sequence learning等等都可以学习下,地址:https://devblogs.nvidia.com/parallelforall/deep-learning-nutshell-sequence-learning/)
文章主要从基本的reinforcement learning到 DeepMind 2013年的 Playing Atari with Deep Reinforcement Learning。( 其实到现在已经又出了很多的成果了,包括前一段时间浙大在Nature上的那一篇文章。)

- 强化学习概念理解:
其实强化学习最简单的理解就是在训练的过程中,不断的去尝试,错了就扣分,对了就奖励,由此训练得到在各个状态环境当中最好的决策。
强化学习当中有几个重要的组成元素,包括前面说到的奖励reward,可以认为是学习过程中的一个反馈;另外一个就是智能体agent,是一个被抽象出来感知周围环境的单元,可以想想为一个小的机器人,在实际的应用当中可能是一个游戏玩家,一个棋手,一辆自动驾驶的汽车等等。智能体agent感知到的环境被称作的状态state,智能体Agent试图通过一种策略决策来最大化 奖励,通过策略便会引起agent的行动动作action。以上构成了 强化学习的基本要素。如图所示为一个例子:
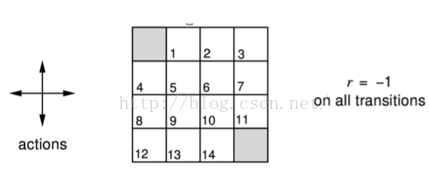
在这个方格中,有一个能够感知周围的智能体agent,它可能处在1~14的任意一个状态s,它要采取某种策略进行行动,达到其中的目标位置(灰色的标出)。可以采取的动作action如上图当中的actions所示,表示可以朝着上下左右行动,并且采取每一种动作的概率相同。而没行动一步得到奖励都是-1. 求解:智能体在任意位置的行动策略,使得得到的奖励值最大。
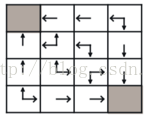
这就是一个强化学习的问题,对于这个问题: 首先,这是一个模型已知的问题(对应还存在一种模型未知的问题Model-free );然后,具有多种求解的方式,包括值迭代求解,策略迭代求解,Q-learning等等。采用值迭代可以得到各个状态情况下的决策,如下所示:
- 值函数(value function):
强化学习是通过奖励或惩罚来学习怎样选择能产生最大积累奖励的行动的算法。为了找到最好的行动,非常有效的方式是,找到那些奖励最大的状态就好了,即在我们目前的环境(environment)中首先找到最有价值的状态states。例如,在赛车跑道上最有价值的是终点线(这里好像就是你冲刺要达到deadline的前一步,这个状态肯定最有价值),这也是奖励最多的状态,因此在跑道之上的状态也比在跑道之外的状态更有价值。(其实这里面就是递归的思想,当你找到了最有价值的状态,你只需要想办法得到这个状态就好了)
最有价值的state可能不只一个,一旦我们确定了哪些状态是最有价值的,我们就可以给这些状态赋奖励值。例如,当赛车偏离跑道时,这些状态就被赋予惩罚;而当赛车跑完一圈时,就会收到一个奖励;当赛车跑出当前最短的时间时,也会收到一个奖励;等等。
我们可以将这些状态和奖励当成一个离散函数,比如在跑道上每隔100m就设定为一个状态点,距离越近的状态价值越高。文章中是把跑道看作 1×1 的方格。对应到这些方格中的奖励就可以用数字表示。例如目标状态的奖励可能为 10,而偏离跑道的方格的惩罚为 -2,其它方格的奖励为 0。最佳的行动是让函数的值越高越好(即最大奖励)的行动。
这些状态中,有些中间状态并不一定有奖励(奖励为 0),但是这些状态是通向奖励状态的必经之路。例如,你必须在跑完一圈之前转弯,或者必须跑完一圈才有机会跑出最短时间。而对于越是接近于终点的状态则可以设置比较高的reward,这也是比较合理的。
需要注意的一点是值函数求解的是一个 累积奖励,通过找到最大的值的状态,然后朝着这个方向前进,但是想想是有问题的:在一场的跑步比赛当中距离终点很远的一个状态只要朝着目标前进,它的奖励值也会很大。但是这显然不合理。因此,在值函数当中会引入一个折扣因子discount Factor,由此使得离他较远的状态给他的奖励贡献是比较小的。因此,折扣因子是一个0~1之间的数,,并且随着距离的增加,这个值会越来越小。当折扣因子为 0.5 时,仅经过 3 次状态改变,奖励值就会变成初始值的八分之一,所以 agent 更倾向于搜索临近状态的奖励值。(其实不加discount factor,累积的时候除以总的迭代次数的倒数也是一样的道理)
值迭代算法: 首先把所有状态的奖励值初始化为 0 或者一个特定的值,然后搜索所有状态的可能的下一个状态(从当前状态转移到其中的任意一个状态都有一个概率),并估计下一个状态 agent 可能得到的奖励,通过这种方式学习每一个状态特有的局部奖励值。如果 agent 在下一个状态得到奖励,那么这个奖励就会累计到当前的状态中。重复这个过程,直到每个状态的局部奖励值不再改变(其实这就是迭代的终止条件),意味着每次变换状态采取的可能转向以及每个状态的奖励值都被考虑在内。

这种方法也许起初看起来并不高效,但是动态规划(dynamic programming)的技巧可以让它更加高效。在子问题已经解决的前提下,动态规划能解决更高层次的问题:B 到 C 的奖励值可以被用于计算 A->B->C 和 D→B->C 的链式状态的奖励值。
总之,价值函数和价值迭代提供了一个局部值的决策图,agent 根据它就可以朝着奖励值增加的状态方向运动,因此得到各个状态下的决策。
- 策略函数(policy function)
值函数相当于是将所有的策略都计算在内求出来的一个期望额奖励值,而策略函数则是对不同的策略求解值函数(相当于值函数在某一策略的条件概率下求解),这样的做的目标很明确,就是我最终的结果是要求解到一个最好的策略,那为什么不在进行值函数计算的时候就分不同的策略求解勒?实际上上文最后的例子也是采用了贪婪的策略,就是每一个的策略都是朝着奖励值最大的方向去,但实际上这并不一定好:
策略函数(policy function)是根据价值函数选择产生最大(长期)奖励的行动的一组策略。在所有可能的下一步行动中,通常没有明确的优胜者。例如,agent 面临选择下一步进入 4 个状态 A, B, C, D 中的一个,它们的奖励分别为 A=10, B=10, C=5, D=5。A 与 B 都是好的即刻选择,但是随着时间的推移,A 状态之后的路径得到的奖励可能比 B 状态好得多,或者进入 C 状态的行动甚至是最好的选择。所以在训练的过程中,探索所有的选择是值得的,但同时,如果只看到即刻奖励,就可能会导致非最优的选择。那么,我们如何在探索尽量高的奖励和探索尽量少的路径之间找到一个平衡点呢?
一个聪明的方法是按照奖励值的比例随机选取状态。在这个例子中,选择 A 的概率为 33% ( 10/(10+10+5+5) ),同样选择 B, C, D 的概率分别为 33%, 16%, 16%。策略函数的随机选择的原理对学习一个好的策略至关重要。因为,也许存在一个看上去是反直觉的,但是有效甚至关键的成功策略。
例如,如果你以跑得快来训练赛车,它会尝试以最快的速度在转弯抄近道。但是当你把其它选手也纳入模型时,这个策略并不是最优的。agent 会将其他选手在转弯处减速考虑在内,以免发生超车甚至撞车。另一个场景是,在转弯处高速行驶可能会更快的磨损轮胎,导致赛程中的停顿,浪费宝贵的时间。
值得注意的是,策略函数和价值函数相互依赖。给定一个价值函数,不同的策略会导致不同的选择;同样给定一个策略函数,agent 会将不同行动赋予不同的价值。给一个棋类游戏赋予「快去赢」的策略,价值函数就会对赢棋可能性高的行动赋予高价值(牺牲棋子以获得赢棋胜算会被赋予高价值)。但是如果赋予「以大比分领先获胜」的策略,那么策略函数会学习在特定的游戏中选择能最大化得分的行动(从不牺牲棋子)。
这些只是许多例子中的两个。如果想得到特定的结果,我们可以同时使用策略和价值函数来指导 agent 学习策略,最终达到特定的结果。这使得强化学习既灵活又强大。
我们训练策略函数通过:
(1)随机初始化——例如,让每一个状态被选择的概率与它的奖励值成正比(可能要先进行归一化,而周志华的教材当中其实每一种策略的概率是一样的)——然后用这些奖励值初始化价值函数;即把所有没有直接奖励值状态的奖励值设成 0(如跑道终点的奖励为 10,偏离跑道外的惩罚为 -2,所有跑道上的状态的奖励值为 0)。
(2)训练价值函数直到收敛(或者指定的训练次数)
(3)对于特定状态(状态 A),增大能让奖励增加最多的行动(从 A 移动到 B)的概率值(相比从 A 到 C,这种移动也许会导致很低甚至负的奖励值,像牺牲棋子,但是它仍可以最终赢得游戏)。(对于各个状态,找到此时各个策略的值,用最大值的策略更新各个状态下的策略)
(4)最后,重复步骤(1)直到策略不再改变。
- Q-函数(Q-function)
我们已经看到策略和价值函数是高度相依的:我们的策略大多取决于我们看重什么,而我们看重什么决定了我们的行动。因此我们或许可以把策略和价值函数结合起来,这个结合就叫 Q-函数(Q-function)。其实就是状态-动作值函数。
同样用条件概率来理解它: 策略迭代的思想就是 在每一个状态下面分各个 策略来计算值函数,但是其实每一个策略同样对应了多种的动作Action。Q函数就是,那我直接计算采取某种动作的值函数就好了啊。也就是说:在某种的状态s下,计算在一种动作a的条件概率的情况下,该值函数的值。就是直接 直接!!!!
Q-函数考虑了当前的状态(如价值函数)和下一步行动(如策略函数),然后针对状态-行动组合,返回局部奖励值。在更复杂的情况下,Q-函数可能会结合更多状态来预测下一步状态。例如,如果行动的方向是很重要的,我们需要至少 2 个状态去预测下一步状态,因为只用一个状态(如一幅静止图像)去推断精确的方向几乎是不可能的。我们也可以将输入状态传给 Q-函数去得到每个可能状态的局部奖励值。然后我们可以按照局部奖励值的比例,随机选取下一步的行动(这种方法叫探索(exploration));或者直接选取最高价值的行动(这种方法叫利用(exploitation))。(通常会采用的方式是概率p随机的从所有的动作当中选取一个动作,以1-p的概率选取当前最优的动作)。
然而,Q-函数的要旨实际上并不在此。设想一辆自动驾驶汽车:有太多的「状态」以至于无法建立一个覆盖所有状态的价值函数;地球上的所有道路的每一个可能的位置和可能的速度实在太多,要计算它们的局部奖励值几乎是不可能的。相反,Q-函数:
(1)只在一步的范围内查找所有可能的下一步状态;
(2)基于当前状态和下一步状态,查看最佳的可能行动。所以对于每一个下一步状态,Q-函数会向前探索一步(并不会探索所有可能的步数直到终止,如价值函数)。
在有些情况下我们需要为绝对无限状态建模。例如,自动驾驶汽车的「状态」经常会被表示为一个连续函数,如神经网络,神经网络会将所有状态的变量(如速度和位置)纳入,然后对每一个行动输出 Q-值。为什么只获取一些状态的信息是有益的呢?很多状态是非常相关的,所以在两个不同但是相似的状态采取相同的行动可能都会取得成功。例如,跑道上每一个转弯是不同的,但是每一个左转弯赛车学到的内容——什么时候开始转弯,怎样调整速度等等——对下一个左转弯时有用的。所以,随着时间的推移,一个赛车 agent 会学到越来越好的左转弯技术,将来即使遇到没见过的赛道也会轻松应对。
Q-学习(Q-Learning)
为了训练 Q-函数我们将所有状态-行动组合的 Q-值初始化为零,并将状态奖励值设定为给定的值,作为状态的初始化值。由于agent 只能看到下一个状态的 Q-值,因为初始时都为 0,因此起初 agent 并不知道如何获得奖励,agent 可能会探索很多状态直到发现一个奖励。因此我们会对训练 Q-函数定义一个训练长度(例如 100 步),或者定义训练直到达到某些状态(跑道上完成一圈)。这保证了我们不会卡在学习一个无用状态行动的过程中,这些无用状态可能不管做了多少次迭代却仍无法得到有用的奖励值。如下图所示为一个Q学习的例子,网格中的 Q-学习,S 是起始状态,G 是目标状态,T 方格是陷阱,黑色的方格是障碍状态。在 Q-学习过程中,agent 一步一步探索环境,起初并不知道目标状态 G。开始的很多次迭代可能一只都不会得到一个有效的Q值,直到如下所示的状态,经过不断的探索得到了一些Q值,一旦目标状态到起始状态附近的路径建立,算法会迅速收敛到一个解,然后再进一步找到问题的最佳策略。

学习 Q-函数是从结果(奖励)到开始(起始状态)进行的。假设目标是以最少的步数达到目标状态 G。最开始 agent 随机移动直到(碰巧)进入陷阱或目标状态。因为陷阱离起始状态很近,agent 很可能最初会先碰到陷阱,但是一旦 agent 在磕磕绊绊中遇到目标状态,这种情况就会改变。从那以后的迭代,到达目标状态之前的那些状态(向前探索一步)就会被赋予局部奖励,同时因为奖励更接近起始位置,agent 也更可能遇到这样的奖励状态。通过这种方式,我们建立起一连串从目标到起始状态的局部奖励值,而且 agent 越是常遇到有局部奖励值的状态,局部奖励值就收敛得越快(见上图)。
- 深度 Q-学习(Deep Q-Learning)
( Q-learning中使用神经网络的做法其实之前就有人想到了,但是效果并不好,因为一方面那时候深度学习的技术还没有现在这么成熟,变成个神经网络也不会比其他模型更好;而另一方面也是最关键的问题来源于强化学习的特殊性。这个特殊性体现在两个方面,一个是它的数据是序列产生的,这样子数据之间并不满足机器学习中通常假设的独立同分布的性质)
一辆自动驾驶汽车也许需要考虑许多状态:每一个不同速度和位置的组合就是一个不同的状态。但是大多数状态是相似的。将相似的状态放在一起并认为它们有相似的 Q-值是否可行?这就是深度学习需要派上用场的地方。
我们可以将当前驾驶员看到的视野——一张图像——输入到卷积神经网络(CNN),训练它预测下一个可能行动的奖励值。因为相似状态的图像也是相似的(许多左转弯看起来相似),它们也会导致相似的行动。例如。神经网络会生成许多左转弯,并且甚至在没有遇到过的左转弯做出适当的行动。正如一个通过很多物品的图像训练的卷积神经网络能够准确识别这些物品一样,一个通过很多相似左转弯训练的网络也能够对不同左转弯做出速度和位置的微调。
然而要成功地使用深度 Q 学习,我们不能简单地应用规则来训练之前所描述的 Q 函数。如果我们盲目地应用 Q 学习规则,那么网络将在进行左转弯时学习做好左转弯,但同时将开始忘记如何做好右转弯。这是因为所有神经网络的动作都使用相同的权重;调整左转弯的权重会使它们在其他情况中表现得更糟糕。解决方案是将所有输入图像和输出动作存储为「经验(experiences)」:即将状态、动作和奖励三者一起存储。
运行了一段时间训练算法后,我们从迄今为止的所有经验中随机选择一个,并为神经网络权重创造一个均值更新,它能为每一个发生在那些经验期间的动作最大化 Q 值(奖励)。这样我们可以在同一时间教我们的神经网络左转和右转。由于在跑道上的较早期驾驶经验并不重要——因为它们源于我们代理的经验不足、甚至是初学者的一个时期——我们只跟踪固定数量的过去经验并忽略休息期。这个过程被称为经验回放(experience replay)。
- AlphaGo
由谷歌 DeepMind 所开发的 AlphaGo 在 2016 年制造了大新闻,它成为第一个在游戏中击败人类职业玩家的计算机程序。接着它以 4:1 击败了一位世界顶尖棋手李世石(Lee Sedol)。AlphaGo 结合了之前本文所提到的许多元素;即(1)价值(value)和(2)策略(policy)神经网络,其中(1)代表了围棋游戏中当前配置的值函数,从而预测每步棋之间的相对值;而(2)策略函数则表明应该选择走哪部棋以赢得游戏。这些网络是卷积网络,它把棋盘当做一张 19×19 的输入「图像」(每个位置一个像素)。

由于我们已经有了许多围棋游戏的记录,通过使用来自专业人员的围棋游戏数据,这些记录对于训练策略网络很有用。该策略网络基于这些数据训练,以在给定游戏配置的游戏中预测出围棋冠军的下一步棋。
一旦完成该监督训练阶段,强化学习就登场了。这里 AlphaGo 与自己对抗并试图改善其策略来挑选行动(策略网络),以评估谁将获胜(价值网络)。即使是仅仅训练策略网络,这种方法也比之前最著名的围棋算法 Pachi 更好,后者利用树搜索(tree-search)算法和启发式算法(heuristics)。然而仅仅在价值网络的帮助下,深度学习方法的性能仍然可以得到显著提高。
(目前,我还没好好研究过AlphaGo,所以这一部分暂时不多说)
后面的文章准备逐步的从数学推导的层面介绍强化学习当中的 模型已知的强化学习问题和模型未知的强化问题,包括CNN代码级别的讲解,敬请关注!
Reference:
- Deep Learning in a Nutshell
- 机器之心
- David Sliver
- 周志华 《机器学习16章:强化学习》