强化学习(一):概述
前言:
最近,强化学习非常的火爆,不论在科研界还是工业界,强化学习一直作为一个新兴的领域,在计算机学科范畴内发挥重要的作用。强化学习(Reinforcement Learning),属于一种机器学习架构(范式)。我们知道机器学习一般分为监督和无监督,所谓监督即是否有外在的标准来约束样本,也就是所谓的标签;无监督则是没有标签的样本。强化学习之所以认为是机器学习的一种架构,是基于强化学习学习的本质。强化学习是通过让智能体(Agent)不断地对所处环境(Environment)进行探索和开发并根据反馈的回报(Reward)进行的一种经验学习。其中智能体是我们要学习的对象,环境则是对智能体的一种外在的约束,智能体可以在这个环境内进行探索和开发,而回报则是环境对智能体最直接的反馈。很明显,这种思想不同于监督和无监督,因此认为强化学习是机器学习的一个新范式。
现如今诸多国际会议和期刊中,强化学习所占比例愈来愈高,尤其是结合深度学习的强化学习(DRL),同时博主所在团队也从这一周开始每周进行一次读书会,因此决定开坑强化学习。
打算开两个栏目,第一个栏目是基于表格型(离散)的强化学习,也就是基于统计的一种离散学习方法;另一个则是基于函数逼近的强化学习,是深度强化学习的基础,主要处理连续型。
0、预览
博主将先开辟第一个栏目——基于表格型强化学习算法,本栏目将主要讲解强化学习如下几个内容,每部分将会以博文形式陆续发布:
- 强化学习概述: 了解强化学习几个要素(智能体、环境、回报、策略、价值函数、模型),强化学习的学习目标;
- 多臂赌博机: 以多臂赌博机为例讲解强化学习的学习机理,并预先引入一些算法;
- 有限马尔可夫决策: “智能体-环境”架构,有限马尔可夫决策过程,贝尔曼方程、贝尔曼最优方程、价值函数、动作价值函数等;
- 动态规划: 策略评估(预测)、策略控制(改进)、价值迭代、广义策略迭代(GPI);
- 蒙特卡洛: 蒙特卡洛预测与控制、同轨(on-policy)和离轨(off-policy)、重要度采样;
- 时序差分学习: 单步时序差分TD(0)、SARSA、Q-Learning、SARSA期望、双学习;
- 多步自举法: n步时序差分、n步SARSA、n步树回溯、n步Q( );
- 表格型学习与规划: Dyna架构(Dyna-Q算法)、期望更新与采样比更新、实时动态规划、蒙特卡洛树搜索。
下面是对应的第一栏目的传送门,可供读者自由选择:
| 文章 | 内容 | 地址 |
|---|---|---|
| (一)概述 | 强化学习的相关概念,包括基本元素,策略的分类,原理等 | 点击复习 |
| (二)贪心策略(ε-greedy & UCB) | 开发与探索,贪心策略,多臂赌博机 | 点击查看 |
| (三)有限马尔可夫决策与贝尔曼方程 | 有限马尔科夫决策,贝尔曼方程 | 点击查看 |
| (四)基于表格型动态规划算法的强化学习 | 动态规划,策略迭代,价值迭代 | 点击查看 |
| (五)蒙特卡洛采样方法 | 蒙特卡洛方法, 同轨离轨策略,重要度采样 | 点击查看 |
| (六)时序差分方法 | 单步时序差分,TD误差,SARSA,Q学习,期望SARSA,双学习 | 点击查看 |
| (七)n步自举法(多步引导法) | n步时序差分 | 点击查看 |
| (八)Dyna架构与蒙特卡洛树搜索MCTS | 表格型学习总结,Dyna,MCTS | 点击查看 |
目前已完成第一栏目的编辑。在随后,博主将开辟第二栏目——深度强化学习,主要介绍基于函数逼近的同轨策略和离轨策略、基于资格迹的强化学习和策略梯度。敬请关注和期待!
1、基本要素
本节主要讲强化学习的基本要素,并了解强化学习的基本原理,本节并不会涉及到相关算法和公式,旨在帮助大家了解强化学习的概念。另外还将对强化学习做一个简单的分类,了解强化学习的不同方面。
考虑人们是如何对环境进行学习的。我们可以举一个电影《疯狂原始人》里的例子,当小伊发现一个新事物(火)的时候,是对它的存在的一种无知和好奇,而当她触碰火苗的时候感受到灼烧感后则又是对它的一种畏惧。这里的小伊就好比一个智能体,它在起初是对未知环境或事物是无知的,但当她决定触摸(即决策)的时候,灼烧感则是环境给智能体的一种反馈,告诉她不能轻易触碰火苗,因此在之后的抉择中,便会记住这个经验教训。简单的示例基本上可以描述起强化学习的本质,同时引出强化学习的几个要素:
- 环境(Environment)
环境是客观存在的一个约束,例如围棋中,棋盘就是一个环境,每次下棋只能在这个约束范围内完成。与环境依附的一个概念是状态(State),一个环境拥有若干个状态,每个状态时环境的一个具体表现。例如标准围棋棋盘是一个环境,而17*17个格子则会反应不同的状态,所谓的棋局就是对应一个状态。状态记做 ,某一个时刻形成的状态记做 - 智能体(Agent)
智能体是强化学习的对象,可以是人、动物,机器人(例如计算机本身)。智能体顾名思义是有智能的物体,也就是说它可以根据不同的环境状态做出相应的动作。以围棋为例,每当一个人落子后,则会形成一个新的棋局(状态),这个局面会影响智能体对接下来落子的地方。 - 策略(Policy)
策略则是智能体在当前状态下所作出的一个动作,比如下五子棋时,当对方黑子出现三连时,基于这个状态,白子所作出的策略应该是堵住黑子。通常意义上讲,策略是基于当前状态所作出的动作,记做 ,在统计学中,其表示一个条件概率分布,亦即在状态 的条件下,动作 被执行的概率。 - 状态转移:
一般来说,做出一个动作后并非能够达到目标状态,例如在棋盘中随机游走,在每个格子均可以上下左右,而当在边缘或角落时,总会有的动作执行后便出了棋盘,因此在执行这些动作后反应应为保持不动。状态转移则是衡量基于状态 及做出的动作 之后,下一个状态是 的概率分布。 - 回报(Reward):
当状态转移到新的状态 时,环境会回馈智能体一个奖励 ,这个奖励即为单步回报。 - 价值函数(Value Funciton):
价值函数又称为状态价值函数,记做 ,是用来衡量某个时刻某状态开始智能体获得总收益的期望,换句话说,从该状态开始,所有可能的策略及可能转移的状态所获得回报的累计。 - 状态价值(State Value):
状态价值则是衡量从某一个状态执行某个动作后,获得累计价值的期望。换句话说,价值函数是状态价值关于动作的期望。状态价值记做 。 - 模型(Model):模型是一个可选的要素。其是对环境反应模式的模拟。基于模型的强化学习是有模型进行指导的,在某个状态下可根据模型做出相应的动作。
2、强化学习工作原理
根据基本要素可知,强化学习的本质是让智能体通过尝试执行相应的决策来学习某个状态下的经验,其目标则是最大化累计价值。
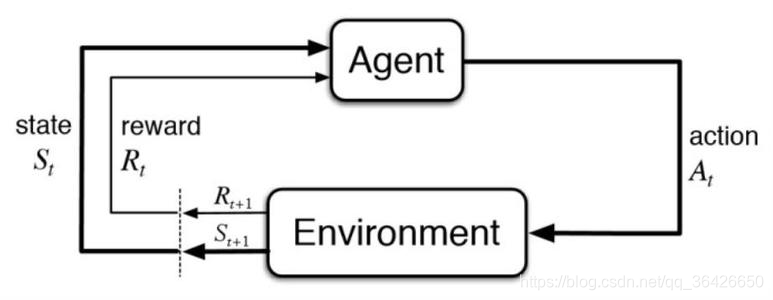
如图所示,当当前的状态为 时,智能体会根据现有的经验做出决策动作,这个经验可能是保守型的(只选择可能累积价值最大的动作,称之为开发),也可能是探索型的(随机选择一个未知的动作,称之为探索),做出相应动作 后,状态会转移到下一个 ,此时环境的状态发生了变化,且会给智能体一个直接的反馈 。这里需要注意的是,只有当状态转移到 时刻, 时刻的状态价值才能获得更新。
3、强化学习分类
本节简单做一个分类,涉及到具体的概念在将来会进行详细的讲解:
(1)按模型分:

在之前提及到模型是强化学习中一个可选的要素。基于模型Model-Based和不基于模型Model-Free本质上的区别在于是否已知每个状态的所有状态转移分布。当我们已经知道状态转移分布时,当处于某个状态时,我们便可以执行某一个动作并且有一定概率向下一个状态靠近。当我们不知道这些概率时,我们唯一的做法就是去采样。因此:
*基于模型的强化学习: 一般指在已知的状态转移分布条件下,智能体根据这个模型做出预先设定好的决策。通常意义来讲,动态规划是一种有模型的强化学习算法。
*无模型的强化学习: 一般是让智能体自己去对环境进行学习。在之后我们将会学习蒙特卡洛、时序差分等均是无模型的。
(2)按策略分:
一般包括同轨策略(on-policy,有时候也叫同策略)和离轨策略(off-policy,也称离策略)。一般这个划分是在蒙特卡洛采样基础上。同轨策略中,用于生成采样数据的策略和用于实际决策的待评估和改进的策略是相同的,而离轨策略则是不同的,换句话说,同轨策略和离轨策略本质区别在于采样的策略和目标训练的策略是否一致,采样的策略称为行动策略(Behavior Strategy),目标学习的策略称为目标策略(Target Strategy)。
我们以后面会讲到的时序差分法为例,如图所示:

SARSA是一种同轨策略,而Q-Learning是一种离轨策略。SARSA之所以称为同轨,是因为其每次采样之后进行的策略评估(贝尔曼迭代)和采样的策略是一致的,也就是说在第
时刻采样的序列和做出学习的序列一样;Q-Learning则不然,其采样的策略和更新的策略完全不一样。在采样时,第
时刻只能前往某一个状态,然后获得这个状态给与的奖励,而在进行策略评估时,则是对第
时刻所有可能的状态动作中挑选最大值,也就是说最大值对应的状态动作和采样时的会不一样。具体的算法和讲解将会后续补上。
另外离轨策略还可以基于重要度采样。
(3)按学习目标分:
我们了解了强化学习的学习目标是最大化累计收益,但这种理解较为粗糙,细致的讲,强化学习的学习目标有两个:

状态动作价值: 一般来说,基于表格型的强化学习是离散的,例如下棋、走格子等,通常以一个邻接矩阵来存储每个状态当前的价值。我们目标则是当我们处于某一个状态时,我们希望依靠经验来判断做出什么决策能够最大可能的获得到最高收益,因此对应于公式:
直面意思就是在状态
条件下,选出能够让状态动过价值最大的动作
。
基于策略: 另外是基于策略的强化学习,例如策略梯度、基于函数逼近的强化学习等,其解决的是连续问题,例如状态转移是连续型函数。
最后给一个使用DQN(深度Q网络)训练的FlappyBird视频,体验强化学习是如何让计算机玩游戏的:https://www.bilibili.com/video/av13940007?from=search&seid=8600208941274500562。
【参考学习资料】
【1】Sutton的《Reinforcement Learning》
【2】伯克利大学强化学习视频CS294-112
欢迎关注“夏栀的博客”
