前言
本文适合强化学习新手,主要介绍强化学习的基本概念。
什么是增强学习
增强学习关注的是智能体如何在环境中采取一系列行为,通过不断试错和探索( ),从而获得最大的累积回报。下表是强化学习和例子对应关系:
| 强化学习 | 围棋大战 |
|---|---|
| 强化学习没有监督者,只有一个反馈信号 | 我们本身不是优秀的棋手,即便是高超的棋手,也无法完全地将棋局的中间某一步棋划为好的还是坏的 |
| 强化学习的反馈结果是延迟的,不是及时的 | 下棋时,有时候可能需要走了很多步以后才知道以前的某一步的选择是好还是坏。而且,下棋的反馈是在最后赢得或是输掉棋局时才产生的 |
| 强化学习的输入总是变化的,每当主体做出一个行为,影响这下一步或几步接受到的数据,独立同分布被破坏 | 当计算机下一步棋时,均影响着对手接下来一步或几步的出棋策略,每一个时间节点棋局都是不相同的 |
基本术语
主体。如机器人,无人机,人的大脑等在实际场景下,需要作出动作决策的智能体。我们的算法就是agent,指挥下一步采取什么样的行动。我们的 只能接受观察,反馈,然后输出行动。
奖励,用 表示。它是反馈信号的标量度量,是一个数字,用来度量 每一步 做的怎么样。 的目标是把每一步的奖励累加起来,尽可能使奖励的总价值达到最大。例如,你想让机器人行走,那么如果机器人每前进一段距离,就给它一个正的奖励,如果机器人摔打,就给它一个负的奖励。
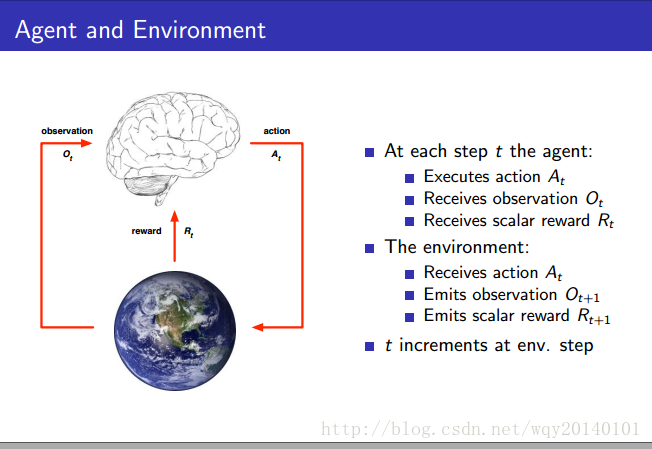
上图的大脑就是 ,也就是我们要实现的算法,用来采取行动,如机器人怎么行走,如何下棋等等。地球代表着外部环境,也就是我们的 需要交互的对象。 采取行动后,新的环境产生,随后产生新的观测和分数。我们不能控制环境,只能控制 采取 来影响环境。强化学习是基于观察、奖励、行动的时间序列。
历史,是观察、行动、奖励的序列。
状态。有时候 会很巨大,而 想要在很短的时间内相应和交互,所以我们引入 。状态是对信息的总结,包含了我们需要的所有信息,决定了下一步的 。换句话说,我们用 代替 。 是 的函数:
- 代表环境状态,这是一种数据的集合。从环境的角度来讲,基于目前所知道的东西,基于 ,某种数字集合决定了接下来要发生什么事情。该状态在下一次观测和奖励的时候,又会被重新拆分。该状态并不一定总是对 可见,但环境通过数据的集合影响我们下一步的举措。
- 代表主体状态,代表 得到了什么,总结目前为止的所发生的事情。通过该状态,我们主体可以选择下一步的措施。
- 信息状态(又称之为马尔科夫状态)是指历史有用信息的总结。一个状态是马尔科夫状态当且仅当:
解释:如果具有马尔科夫性质,那么未来会发生什么,和过去没有关系,仅取决于当下:因为你一旦得到 ,就可以扔掉 ,你不需要 了,因为 里有用的东西,已经被 概括代表了。 - Full Observable Environment:完全观测环境,特指
可以完全观察到环境状态,即
。这是最好的情况, 可以看到所有的环境。
- Partial Obsevable Enviroment:部分观测环境,比如,在屋子里行走的机器人并不知道远处的火山,机器人所能看到的只有他摄像头拍摄的东西。打牌的时候我们只能看到自己的牌。此时, 状态不等于环境状态,agent构造自己的状态。如何构造?

RL的agent包含哪些内容
以下几个部分不一定 全部包含。
的行为函数,即状态到行动的映射,用 表示:
度量某一个 或 的好坏程度。在某种策略 下,计算方式为:
model预测感知环境如何变化。这里不是真实的环境,而是
眼中的环境。这里我们引入两个变量,一是转移状态概率,二是下一个即时奖励的期望。

稍微注意一下,在下一节介绍马尔科夫决策过程的时候,我们还要用到这两个变量。
总结
本人主要是看别人的博客和最新的增强学习视频总结写下的(bibi视频链接)。看别人的视频或者博客,我觉得最重要的是反复看,反复听,每一次都会有不同的感受。第一节的视频我看了三遍,感触较深,希望对你有帮助,坚持!
