关于 Alex 的传说……大家随便听个报告都会讲到,这里就不说了。本文主要目的是为自己梳理知识,以便日后复习。
- 网络结构
- ReLU
- Dropout
AlexNet
ImageNet Classification with Deep Convolutional Neural Networks
http://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-network
前5层是卷积层,后3层是全连接层,
每层卷积层后接 RuLU 激活
前两层和最后一层卷积后有池化,具体如下图。

ReLU Nonlinearity
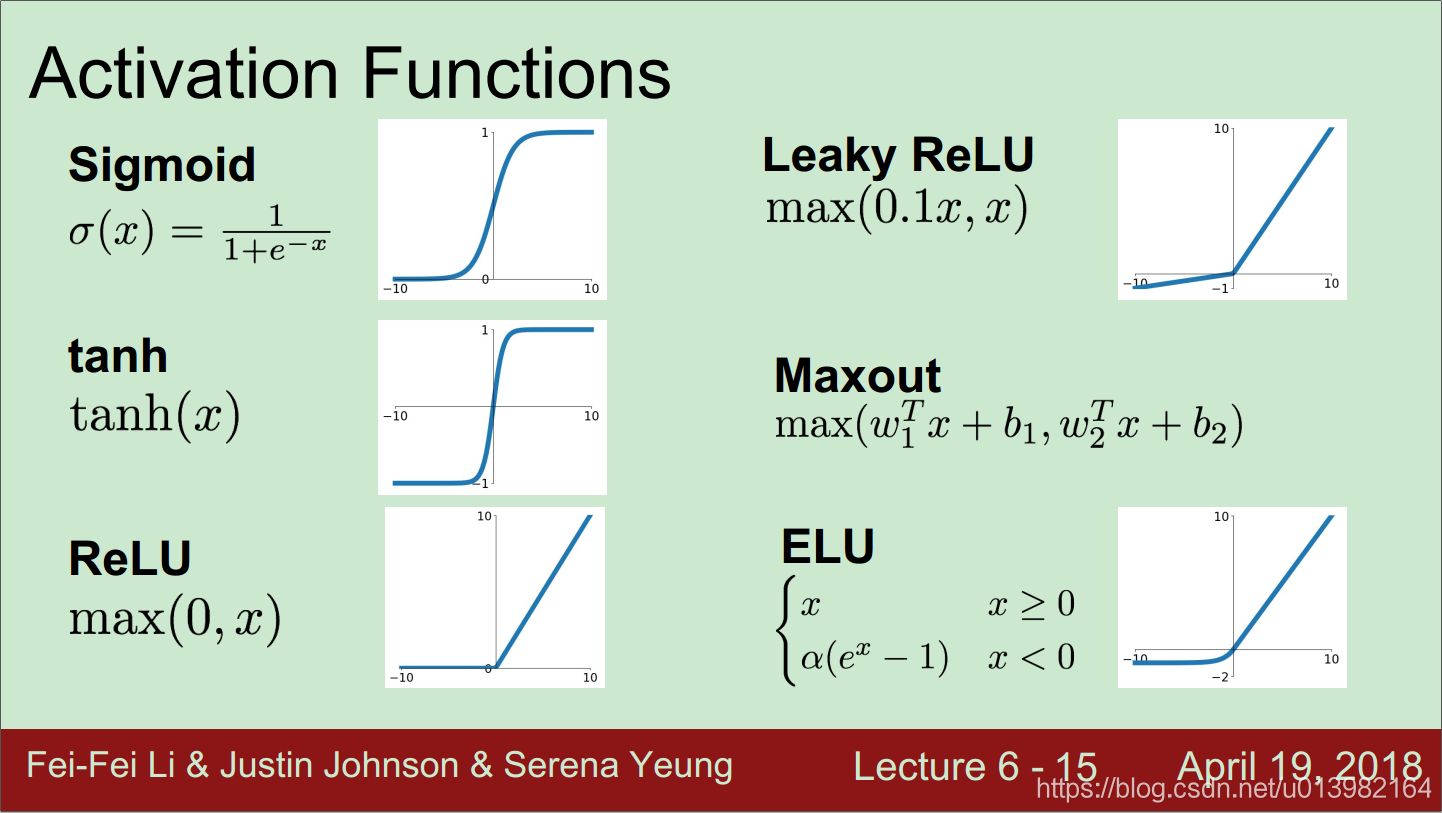
激活函数是从 Sigmoid 到 tanh 到 ReLU 的,最初用 Sigmoid 存在三个问题
-
Saturated neurons “kill” the gradients.
- 当输入 x=0 时,梯度为0.25,当网络层数浅是是OK的,但数值计算中学过当极端情况下,多个小数相乘会等于0,深层网络也是有问题的。
- 当输入 x=±10 时,此时神经元饱和,回传的梯度接近0,这个当然是大问题。
-
Sigmoid outputs are not zero-centered. 为什么要以零为中心?
-

- Always all positive or all negative. Sigmoid 的输出恒为正,假设x除了输入层其他都为正,那么此时所有关于参数的梯度与上游梯度同号(当前梯度=局部梯度×上游梯度),因此所有维度参数w更新方向只能相同,这样导致的结果就是当前批次,更新参数是用不同的正数去增加或减小参数w,以至于梯度更新十分低效。为什么低效呢?
- 如上图,Sigmoid 允许参数更新的方向在第一象限(全正),第三行星(全负),假设最佳w是蓝色向量,我们只能在允许的方向上更新,导致更新路径是红色向量,比起蓝色向量低效走远了
- this is also why you want zero-mean data! 这也是一般情况下我们使用0均值的数据作为输入。
-
-
exp() is a bit compute expensive.
- 卷积网络中主要代价是 dot products,exp() 的代价稍微注意一下就行了
然后就出现了 tanh
- zero centered (nice) . 解决了 not zero centered 的问题,
- still kills gradients when saturated . 但任存在另外两个问题。
接着就是本文用的 ReLU 方法,优点有四,缺点有一
-
优点
- Does not saturate (in +region).
- 看图还是很直观,如果输入是正数,输出还是这个数,因此在输入空间(+region)不存在饱和问题
- Very computationally efficient.
- Converges much faster than sigmoid/tanh in practice (e.g. 6x)
- Alex 也做了对比实验
- Actually more biologically plausible than sigmoid
- Does not saturate (in +region).
-
缺点
-
Not zero-centered output
-
RuLU 只有一半的区域能被激活,当权重初始化不好时,会出现 dead ReLU 的现象,people like to initialize ReLU neurons with slightly positive biases (e.g. 0.01)
-
存在 dead ReLU,当你传入数据到训练好的网络,会发现网络中多达10%到20% dead ReLU,所以才出现了模型蒸馏等等方法?
-
PReLU, LReLU 讲道理是更优的,为什么现在论文中不用呢? 我觉得应该是 RuLU 是个基线吧。
-
-
Training on Multiple GPUs
当年数据是有了,但计算能力不强加上还没轮子用,幸好 Alex 工程能力极强,在 cuda 环境下把代码死磕出来了
Local Response Normalization
据说是 Hinton 在当年能训练多层网络的独门绝技,,,该想法的动机是,对于这张图片的每个位置来说,我们可能并不需要太多的激活省神经元。但是我出生的晚,跳过这部分吧。
Overlapping Pooling
避免过拟合用
Reducing Overfitting
机器学习的本质目的是泛化误差最小,所以避免过拟合是一个老生常谈的话题了。
Data Augmentation
无需多讲,深度学习训练前必做的一步。Alex 首先对数据进行水平翻转和旋转,然后做了PCA
Dropout
使用Bagging解释Dropout比使用稳健性噪声解释Dropout更好,Dropout 提供了一种廉价的 Bagging 集成近似, 见下图
-

-
因为Dropout是一个正则化技术,它减少了模型的有效容量。为了抵消这种影响,我们必须增大模型规模,但这是以更大的模型和更多训练算法的迭代次数为代价换来的。当数据非常大时,正则化带来的泛化误差减少得很小 ,只有极少的训练样本可用时,Dropout不会很有效。 所以需要根据数据来 trade-off
-
一般选择 Dropout 率为0.5,原因是0.5的时候 Dropout 随机生成的网络结构最多
-
在 inference 阶段是不用 Dropout 的
参考
Krizhevsky. ImageNet Classification with Deep Convolutional Neural Networks. 2012
Li. CS231n. Lecture 6
Goodfellow. Deep Learning. 7.13
Ng. Deep Learning Specialization. CNN-Classic networks