版权声明: https://blog.csdn.net/qq_26386707/article/details/79341609
机器学习(二)概率密度估计之非参数估计
2018/2/19
by ChenjingDing
二.非参数估计
2.1直方图估计
直方图估计概率密度函数基本思想:
将数据空间分成许多个子空间,每一个子空间大小为
△
,在每一个子空间内计算样本出现的个数
ni
,样本总个数为N,则概率密度函数为:
p(x)=niN△;
平滑因子:
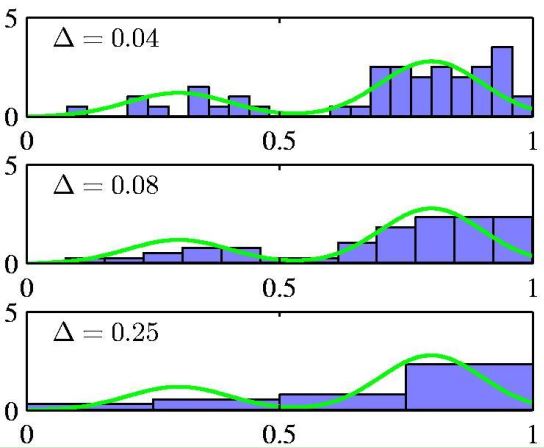 图4 不同平滑因子(上:平滑因子过小,估计的概率密度函数有很多毛刺,噪声; 中:平滑因子适合的时候,估计的概率密度函数; 下:平滑因子过大,估计的概率密度函数误差增大)
图4 不同平滑因子(上:平滑因子过小,估计的概率密度函数有很多毛刺,噪声; 中:平滑因子适合的时候,估计的概率密度函数; 下:平滑因子过大,估计的概率密度函数误差增大)
缺点:
当数据空间的维数为D,每一维划分的子空间个数为M,则所需子空间个数为
MD
, 该个数呈指数级增长。有两种方法可以解决这个问题,它们都是针对每一个输入样本
xˆ
,而并非对整个训练样本事先划分好子空间。
这两种方法有相同的思路:在一个很小的区域R内,
P(x)=∫Rp(x)dx≈p(x)V⇒p(x)=P(x)V=KNV
K可以理解成V内训练样本的个数。如果固定V,则产生了核方法。如果固定K,则产生了K近邻估计的方法。
2.2核方法
引入核函数:
k(μ)⩾0,V=∫k(μ)dμ=1(积分也可不为1)则K(xˆ)=∑i=1nk(xi−xˆ)⇒p(x)=1N∑i=1nk(xi−xˆ)
上述表述没有直方图方法那么直观,举以下两个例子:
k(μ)
如下定义:
k(μ)={1 (|ui|<h2,i=1,2...D)0,elseV=∫k(μ)dμ=hD
如果μ是二维,则该积分表示以
xˆ
为中心,长宽为h,高为1的长方体体积 。
K(xˆ)=∑i=1nk(xi−xˆ)=∑i=1n1(|xi−xˆ|<h2)p(x)=KNV=∑ni=11(|xi−xˆ|<h2)N∗hD
K(xˆ)
表示的是与
xˆ
距离小于
h2
的样本点的个数,如下图所示:
 图5 核方法中K的意义(红色点为
xˆ
, 方框边长为h)
图5 核方法中K的意义(红色点为
xˆ
, 方框边长为h)
但是该核函数估计的概率密度在边界处不连续,可以选择更加光滑的核函数比如高斯函数解决这个问题。
-
k(μ)
为一维高斯函数
k(μ)=12π−−√∗hexp−(μ)22h2V=∫k(μ)dμ=1K(xˆ)=∑i=1nk(xi−xˆ)
该核函数的
K(xˆ)
表示与
xˆ
距离小于
h2
的样本点的加权个数,权值是高斯函数的值,第一个例子中的权值全为1。
平滑因子h:
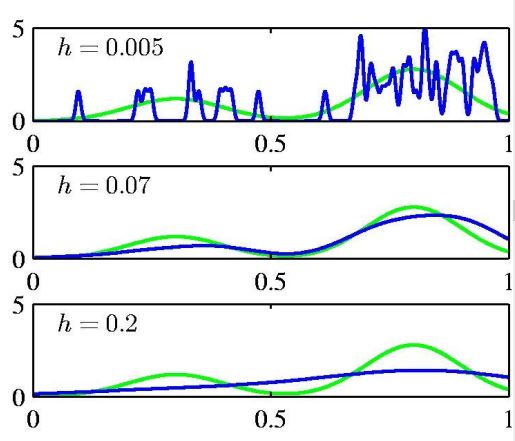 图6不同平滑因子(上:平滑因子过小,估计的概率密度函数有很多毛刺,噪声; 中:平滑因子适合的时候,估计的概率密度函数; 下:平滑因子过大,估计的概率密度函数误差增大)
图6不同平滑因子(上:平滑因子过小,估计的概率密度函数有很多毛刺,噪声; 中:平滑因子适合的时候,估计的概率密度函数; 下:平滑因子过大,估计的概率密度函数误差增大)
2.3K近邻估计
固定K,增大V至
V∗
, 使得
V∗
内含有K个训练样本。
p(x)=KNV∗
平滑因子K:
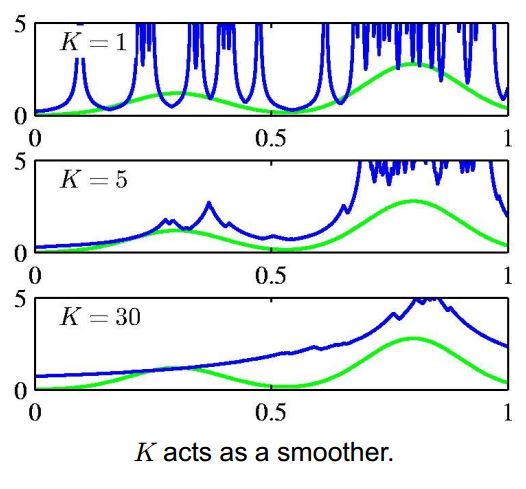 图7不同平滑因子(上:平滑因子过小,估计的概率密度函数有很多毛刺,噪声; 中:平滑因子适合的时候,估计的概率密度函数; 下:平滑因子过大,估计的概率密度函数误差增大)
图7不同平滑因子(上:平滑因子过小,估计的概率密度函数有很多毛刺,噪声; 中:平滑因子适合的时候,估计的概率密度函数; 下:平滑因子过大,估计的概率密度函数误差增大)
缺点:
K近邻估计的概率密度函数并不是真正的概率密度函数。
考虑
K=1,∃xi,xi=xˆ⇒V=0⇒p(x)=∞
K近邻用于分类:
用K近邻方法推出后验概率:
p(xˆ)=KNVp(xˆ|Cj)=KjNjVP(Cj|xˆ)=p(xˆ|Cj)∗P(Cj)p(xˆ)=KjNjV∗NjN∗NVK=KjK
如果
P(Cj|xˆ)>P(Ck|xˆ)∀j≠k
,则将样本
xˆ
分到 j 类。
2.4 核方法和K近邻估计的缺点
需要存储训练样本,对每一个输入样本
xˆ
,都需要遍历整个训练样本。
三参数方法和非参数方法的比较
| 方法 |
适用范围 |
| 参数法 |
各样本独立同分布,只能预先假设样本的分布 |
| k近邻&核函数法 |
训练样本集数据比较少 |
| 直方图 |
训练样本的维数较低 |
综上,以上这些简单的方法都不够灵活和有效,下节将介绍更加灵活的方法——高斯混合模型。