4.1预备知识
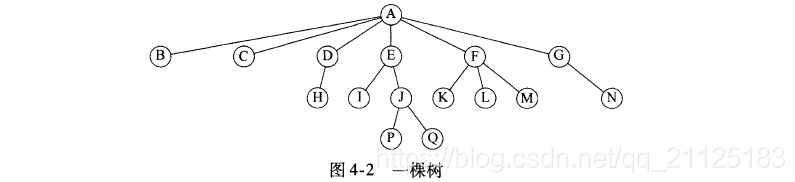
树(tree)可以用几种方式定义。定义树的一种自然的方式使递归的方式。一棵树使一些节点的集合。这个集合可以是空集;若不是空集,则树由称做为根(root)的节点r以及0个或多个非空的树集合T1、T2、T3组成,这些子树的每一课根都被来自根r的一条又向边(edge)所连接。
树的基本概念
- 树叶:没有儿子的节点
- 兄弟:具有相同父亲的节点
- 祖父:从根到该节点所经分支上的所有节点;
- 孙子:以某节点为根的子树中任一节点都称为该节点的子孙;
- 路径:从节点n1到nk的路径的定义为节点n1,n2,n3,n4…nk的一个序列,使得对于节点ni是ni+1的父亲。这条路径的长是为该路径上的边的条数。
- 树的深度:从树的根节点到ni的唯一路径的长
- 树的高度:从ni到一片树叶的最长路径的长度
4.1.1 树的实现
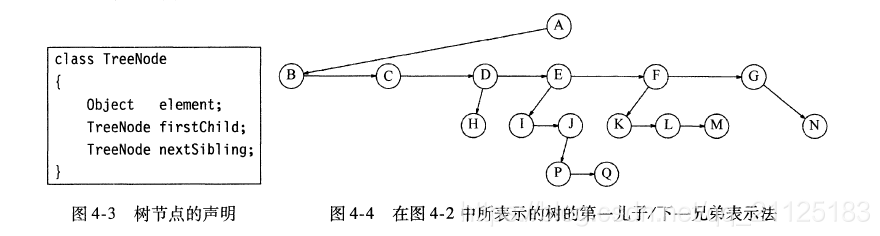
4.1.2 树的遍历和应用
- 先序遍历:在先序遍历中,对节点的处理工作是在它的诸儿子节点被处理之前处理的(pre)。比如UNIX文件系统中的目录结构遍历
- 后序遍历。在后序遍历中,一个节点处的工作是它的诸儿子节点被计算后进行的。比如统计UNXI文件系统中文件夹的磁盘区块个数。
4.2 二叉树
二叉树是一棵树,其中树的每个节点都不能有多于两个的儿子。有一种特殊的二叉树,即二叉查找树,其深度的平均值是O(logN),并且这些操作的平均时间是O(logN)。
- 完全二叉树:完全二叉树是由满二叉树而引出来的。对于深度为K的,有n个结点的二叉树,当且仅当其每一个结点都与深度为K的满二叉树中编号从1至n的结点一一对应时称之为完全二叉树。
- 满二叉树: 一棵深度为k,且有2^(k-1)个节点的树是满二叉树。
完全二叉树的性质:
- 深度为k的完全二叉树,至少有2(k-1)个节点,至多有2^k-1个节点。
- 树高h=log2n + 1。 树高h=log2n + 1。
4.2.1 实现

4.2.2 列子:表达式树
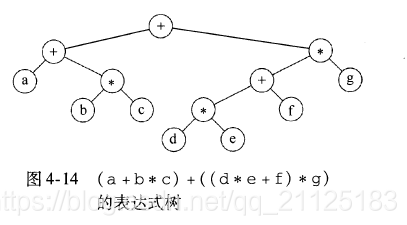
图中显示的就是一个表达式树的列子。表达式树的树叶是操作数,如常数或者变量名,而其他节点都是操作符。
- 中缀表达式:中序遍历(左子树,节点,右子树)
- 后缀表达式:后序遍历(左子树,右子树,节点)
- 前缀表达式:前序遍历(节点,左子树,右子树)
4.3 查找ADT–二叉查找树
基本概念:使二叉树成为二叉查找树的性质是,对于树的每一个节点X,它的左子树的所有项的值小于X中的项,而它的右子树中所有项的值大于X中的项。
- 前驱节点:节点val值小于该节点val值并且值最大的节点 (节点中序遍历后的前一个节点)
- 后继节点:节点val值大于该节点val值并且值最小的节点 (节点中序遍历后的后一个节点)

二叉查找树的平均深度是O(logN),并且操作的平均运行时间是O(logN)。

4.3.1 contains方法

4.3.2 findMin方法和findMax方法

4.3.3 insert方法

4.3.4 remove方法
如果节点是一片树叶,那么它可以立即被删除。如果节点有一个儿子,则该节点可以在其父节点调整自己的链以绕过该节点后被删除。
复杂的情况处理有两个儿子的节点。一般的删除策略是用其右子树的最小的数据(很容易找到)代替该节点的数据并递归地删除那个节点。因为右子树中最小的节点不可能有左儿子,所以第二次remove就要容易。
如果删除的次数不多,通常使用的是**惰性删除**:当一个元素要被删除的时候,它仍留在树中,而只是标记为删除。
4.3.5 平均情况分析
假设所有的插入序列都是等可能的,则树的所有节点的平均深度为O(logN)
二叉查找树的平均运行时间是O(logN)
- 问题:如果一颗树的输入预先排序好的数据,那么一连串的insert操作将花费二次的时间,而链表实现的代价会非常巨大,因此树将只由那些没有左儿子的节点组成。一种解决方法就是要有一个称为平衡的附加结构条件:任何节点的深度都不能过深。
所以引入了平衡二叉查找树:AVL树
4.4 AVL树
AVL树是带有平衡条件的二叉查找树。这个平衡条件必须要容易保持,并且它保证树的深度必须是O(logN)
一颗AVL树是其每个节点的左子树和右子树的高度差为1的二叉查找树。
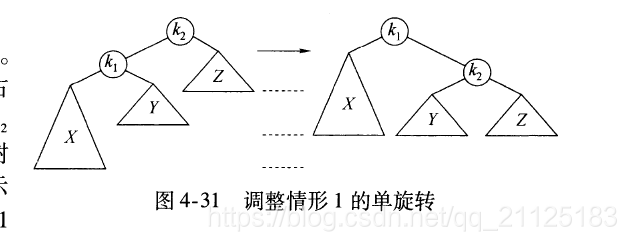
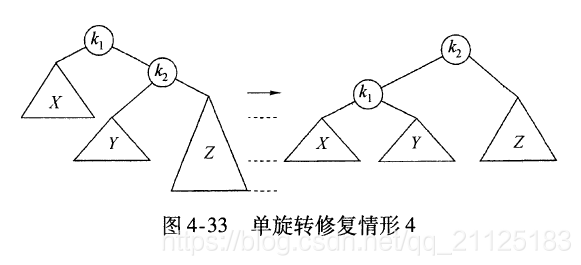
4.4.1 单旋转
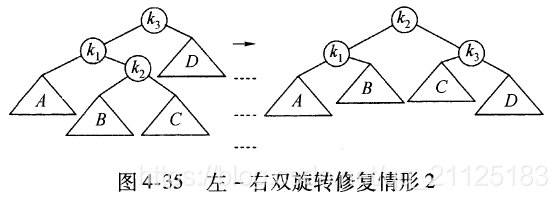
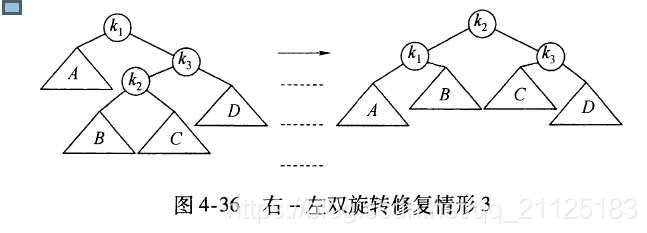
4.4.2 左右双旋转
4.5 伸展树
伸展树:它保证从空树开始连续M次对树的操作最多花费O(MlogN)时间。
一般来说,当M次操作的序列总的最坏情形运行时间为O(Mf(N)),我们就说他的摊还代价是O(logN)
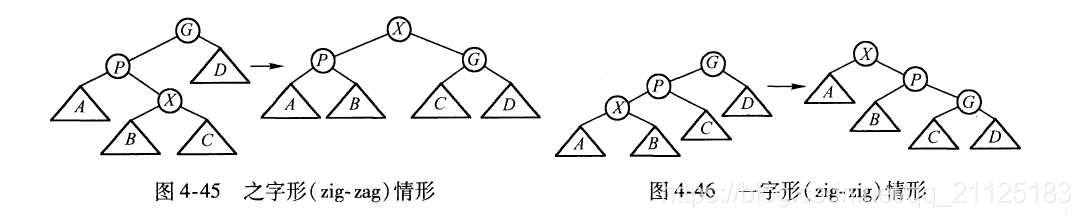
伸展树的基本想法是:当一个节点被访问后,它就要经过一系列AVL树的旋转被推到跟节点上。
4.5.2 伸展
4.6 再探树的遍历
-
中序遍历:该方法能够解决将项排序的问题。正如我们所看到的,这类程序当用于二叉查找树的时候则称为中序遍历。(左子树,根节点,右子树)
-
后序遍历:该方法可以用于遍历树的高度。(左子树,右子树,根节点)
-
前序遍历:该方法用于遍历树的深度。(根节点,左子树,右子树)
-
层序遍历:在层序遍历中,所有深度为d的节点都要在深度为d+1节点之前进行处理。层次遍历与其他类型遍历不同的地方在于它不是递归地执行;它需要使用到队列,而不使用递归所默示的栈。
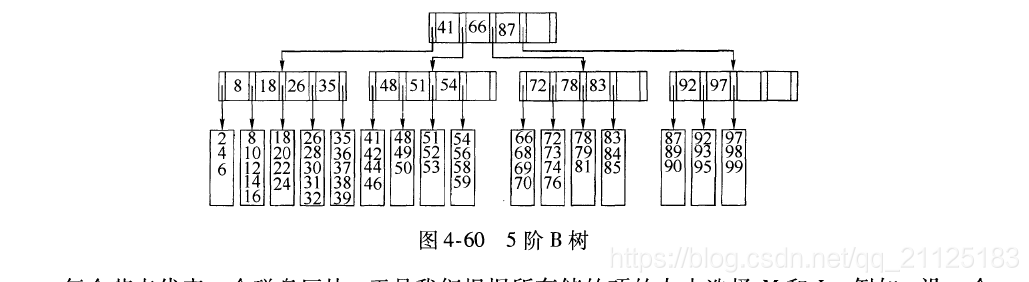
4.7 B树
磁盘的代价太高了
首先,简单说一下B树产生的原因。B树是一种查找树,我们知道,这一类树(比如二叉查找树,红黑树等等)最初生成的目的都是为了解决某种系统中,查找效率低的问题。B树也是如此,它最初启发于二叉查找树,二叉查找树的特点是每个非叶节点都只有两个孩子节点。然而这种做法会导致当数据量非常大时,二叉查找树的深度过深,搜索算法自根节点向下搜索时,需要访问的节点也就变的相当多。如果这些节点存储在外存储器中,每访问一个节点,相当于就是进行了一次I/O操作,随着树高度的增加,频繁的I/O操作一定会降低查询的效率。
这里有一个基本的概念,就是说我们从外存储器中读取信息的步骤,简单来分,大致有两步:
- 找到存储这个数据所对应的磁盘页面,这个过程是机械化的过程,需要依靠磁臂的转动,找到对应磁道,所以耗时长。
- 读取数据进内存,并实施运算,这是电子化的过程,相当快。
综上,对于外存储器的信息读取最大的时间消耗在于寻找磁盘页面。那么一个基本的想法就是能不能减少这种读取的次数,在一个磁盘页面上,多存储一些索引信息。B树的基本逻辑就是这个思路,它要改二叉为多叉,每个节点存储更多的指针信息,以降低I/O操作数。
4.8 标准库中的集合与映射
4.8.1 关于Set接口
Set 接口不允许重复的Collection。有接口SortedSet给出的一种特殊类型的Set保证其中的各项处于有序状态。
由Set所要求的一些独特的操作是一些插入、删除以及执行基本查找的能力。保持各项以有序状态的Set的实现是TreeSet。
get操作和add操作
4.8.2 关于Map接口
Map是一个接口,代表由关键字以及它们的值组成的一些项的集合。关键字必须是唯一的,但是若干关键字可以映射到一些相同的值。因此值不必是唯一的。
在SortedMap接口中,映射中的关键字保持逻辑上是有序状态。SortedMap接口的一种实现是TreeMap类。Map的基本操作包括isEmpty、clear、size等方法。
